大量MySQL表導致服務變慢的問題
背景
有一個業務需要分 1000 個庫,每一個庫中都有 80 個表,總共就是 80000 * 2 個文件。文件使用率還挺高,大概是 60000 * 2。
這個業務采用的高可用架構是 MMM,由于集群機器在硬件檢查時發現有問題,必須要換掉。于是想了一個比較簡單、影響面較小的方法去解決,就是找了另外兩臺機器遷移過去。同時,要求這四臺機器屬于同一個網段,VIP(虛擬 IP 地址)在機器之間可以漂移,這樣業務就不需要修改 IP 地址即可遷移,相當于兩次主從切換過程。
切換方案如圖 16.1 所示。
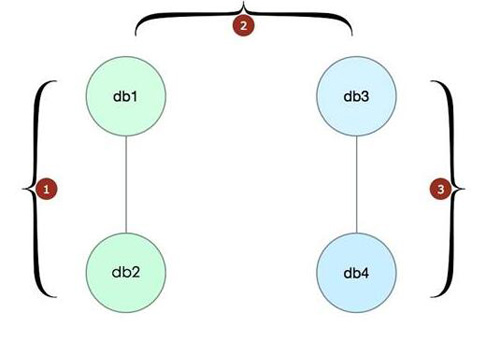
從圖 16.1 中可以看到,切換過程很簡單,如下三步。
- 先將原來的寫節點(db1)與一個新的節點(db3)切換成一套集群,也就是把在 db2 上面的 VIP(讀流量)切換到 db3 上面,此時 db1 與 db3 組成一套新集群。
- 接著將 db1 和 db3 的角色互換,讓 db3 成為寫節點,db1 成為讀節點。
- 最后,再將 db1 讀節點上面的 VIP(讀流量)切換到 db4 上面,此時新的集群就是 db3 和 db4,db3 為寫節點,已經切換完成。這樣的變更是晚上做的。做好之后,觀察了一段時間,發現沒有什么問題(因為壓力小),所以覺得事情完成了,睡吧。 第二天上班之后,業務反映說遷移之后,數據庫比原來慢了 10 倍(10 倍啊!感覺不可思議)。詢問了一番,說沒有任何變更,只是做了遷移之后就成這樣了。同時經過觀察,只有寫庫的讀操作變慢了,而讀庫的讀是不慢的。最后,業務已經受不了了,要求切換回去。還好,db1 還正在從 db3 復制,做了一個回退操作,把寫掛在 db1 上面,把讀掛在 db3 上面。神奇的是,問題解決了!好吧,那就先這樣,走出去的路不能回頭,總是要遷出去的,所以先在新舊兩臺機器上面掛著,查明原因后再切換回去(這樣少做一步)。
以上是背景。
問題分析
環境對比
- db1 寫入時,db1 寫不慢,讀不慢,db3 也不慢。
- db3 是新的硬件,db1 是老的、有問題的硬件。
- db3 切換成寫之后,在慢查詢文件中明顯看到很多慢查詢(使用相同的語句查詢,原來是 50ms,現在是 500ms),和監控是一致的。
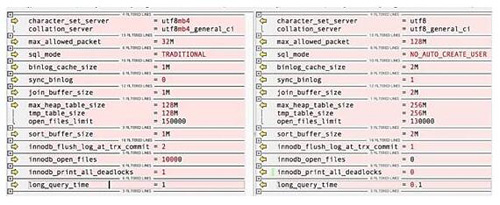
- db1 和 db3 配置文件有差別,如圖 16.2 所示(左邊是 db3 的,右邊是 db1 的)。
其他方面,環境完全相同,業務方面沒有任何更改,重現慢的現象,只是需要切換而已。
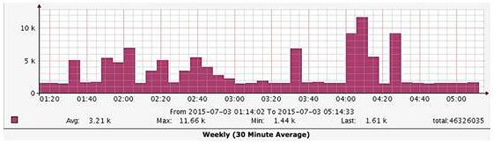
圖 16.3 是切換過程中的監控圖,高起來的就是把流量切換到 db3 的情況,處于低谷的就是切換到 db1 的情況,效果非常明顯,慢得立竿見影,好神奇!
原因分析
- 從對比中可以得知,db1 是正常的(以前長時間在這個機器上跑,沒有問題),而 db3 是不正常的。這個業務目前是讀多寫少,現在的現象是讀慢。因為寫少,沒有發現慢,就不考慮了。
- 接著就是硬件的區別,二者都是 PCI-e 卡,老的、壞的概率比較大,從經驗上來看新的會比較好,這是一個值得懷疑的點。但實際上,針對這個問題,找到了新卡的技術人員進行分析,將寫切換到 db3 上之后觀察,發現 IO 非常小,能看到的監控指數都非常正常。(他們也很納悶。)
- 除此之外,唯一的區別就是二者的配置了,但從圖 16.3 中可以看到,沒有一個參數可以影響到讓數據庫的響應時間是原來的 10 倍。
但上面這些都只是分析,硬件測試之后,沒有發現問題(也不能說就不是硬件的問題,一直吊在那里)。那只剩下配置了,所以接下來從這里入手吧,希望能成功!
那么,再找一個夜深人靜的夜晚……
案例解決
首先要做的事情是,把 db3 的讀流量切換到 db1,然后把配置完全換成 db1 的配置,將數據庫重啟,然后上線。此時,db1 是寫節點,db3 是讀節點,最神奇的時刻即將到來。
切換之后,經過觀察,竟然沒有問題了。問題已經解決,那么說明還是上面列出來的配置差別引起的問題。
那么解決之后,下面的工作就是重復一開始的工作,把 db1 下線,讓 db4 上線。此刻,之前的遷移工作已經完成,線上服務沒有問題。
但……開發同學,能給我半個小時,讓我看看是哪個參數引起的么? 得到的回答是:“迅速點,就這一次,給你 20 分鐘。”
把最有可能的參數找出來,比如字符集(實際上,上面列出的每一個,我們認為都不會有多大影響),考慮到字符集是不可動態修改的參數,所以先把這個改了。重啟,然后一個一個地動態修改、業務重啟重連等,都沒有發現。修改的這些參數包括:sql_mode、join_buffer_size、max_heap_size、sort_buffer_size,這些都沒有影響。
結果已經說好的只有這一次,那就這樣吧,任務成功完成,問題解決失敗。
然而,這個問題“才下手頭,卻上心頭”,總有一件事放心不下,約吧。 和開發商量了一下,我們想解決這個問題,知道其所以然,防止在其他業務上出現同樣的問題。好吧,再給你們一次機會(來之不易啊)。
那么,再找一個夜深人靜的夜晚……這次的月亮好像比上次更圓一些,是好日子的征兆么?
操作之前,還簡單規劃了一下,下面是當時的一個計劃步驟。
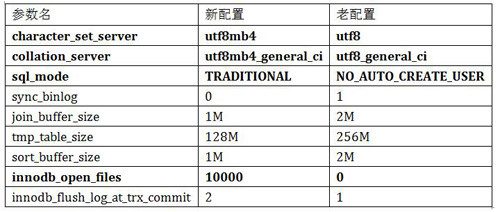
^* 黑體的表示已經專門測試過,沒有影響
步驟如下。
考慮到先重現問題,首先應該全部使用新配置測試一次,確定問題是否還存在。
因為重點考慮問題是因為 sql_mode 引起的,所以第二次只將這個參數改為老配置,這樣就可以測試出其他配置組合時有問題,或者是沒有問題,從而得出結論是 sqlmode 的問題。
如果上面還沒有找到問題原因,那么就是除了 sql_mode 之外的其他參數組合出了問題(如果沒有,則見鬼了)。此時,通過二分法測試,先測試 innodb_flush_log_at_trx_commit、innodb_open_files、sort_buffer_size 三個參數。
如果發現上一步有問題,則再進行二分;如果沒有發現問題,則對 sync_binlog、join_buffer_size、tmp_table_size 進行二分。
如果能走到這里,那也是醉了。
再說吧。
按照步驟,一步步地開始做。
首先使用有問題的配置,測試一遍,發現是老樣子,還是有問題的(真是幸運,問題還存在)。
把除了 sql_mode 之外的所有參數改成新的,其他都用老配置,測試發現沒有問題。
做完了,也是沒有問題。
做完了,還是沒有問題。
我醉了。
此時當事人已經搞不清楚了,難道是某兩個的組合會導致出現這樣的問題?如果是這樣的話,那情況就太多了,天已經亮了,很累,放棄吧!
就在想放棄的時候,突然有一種新的思路。在有問題的基礎上,把所有經過測試沒有影響的可以動態修改的參數改成與 db1 相同的參數,這樣應該是最少量的可以影響到性能的參數組合了。此時,在 db1 與 db3 實例上分別執行 show variables,全量導出變量,進行對比,發現有幾個參數的區別(左邊是老的 db1,右邊是新的 db3),如圖 16.4 所示。
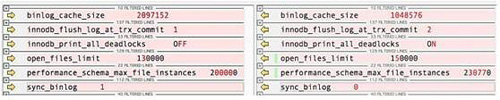
此時,我們做了最后的掙扎,已經只剩下這 6 個了,看上去還是不會有什么影響,有些已經試過了,再隨便試一次吧。二分查找,從下面開始找了三個參數,下線、重啟、上線……發現問題竟然奇跡般地存在。而此時只剩下了三個參數,其中一個參數是 sync_binlog,有問題的是 0,肯定不會影響啊。只能定位到剩下的兩個了,可以看到倒數第二個是一個 performance_schema 的參數,配置文件中沒有設置,是默認的,可以忽略。于是,把問題定位到 open_files_limit 了。
此時,再做最后一次,只剩下 open_files_limit 的區別了。結果還是有問題,說明就是這個參數了。
回過頭來想了一下,其實當初看區別的時候,這兩個參數就在配置文件中,只是看著 13 萬和 15 萬相差不大,就忽略了。好吧,問題已經解決,找到了原因,天亮了,回家吧。
已經查到了是 open_files_limit 的原因。那么,究竟為什么在一個參數相差這么小的情況下會影響 10 倍的性能呢?查查源碼!
通過 sysbench,創建 60000 個表,每個表 10000 行,在只讀模式下,發現設置為 130000 時,QPS 可以達到 20000,而設置為 150000 的時候,QPS 只有 4000 左右。問題重現了,就簡單多了。
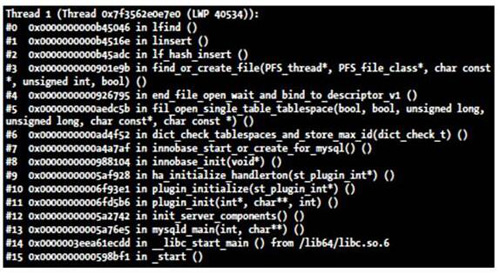
此外,還有一個額外的發現。如果設置為 150000 之后,重啟數據庫,非常慢,大概需要 1 分鐘,而設置為 130000 之后,只需要 10 秒左右。查看了一下在很慢的過程中 mysqld 的線程情況。其中,在啟動的過程中,有一個線程長時間都基本處于同一個堆棧,使用 pstack mysqldpid 查看,如圖 16.5 所示。
還有一個發現就是,當設置 open_files_limit 為相同的時候,performance_schema_max_file_instances 參數也相同了,并且這個參數沒有設置過。那么,通過源碼發現,這個參數竟然是通過 open_files_limit 值來設置的。如果 open_files_limit 值設置得比較大(這樣就可以忽略掉其他影響條件,比如 max_connection 等),performance_schema_max_file_instances 的值直接就是從 open_files_limit/0.65 得來的(源碼對應函數 apply_load_factor)。這樣就知道了,130000/0.65 正好是 200000,150000/0.65 正好是 230770,與圖 16.4 所示相符合。
另外,通過測試發現,如果單獨設置 performance_schema_max_file_instances 為不相同的值,而將 open_files_limit 設置為相同,性能還是不一樣。從而可以確定與 open_files_limit 參數實際上沒有什么關系,只是 performance_schema_max_file_instances 使用了默認值,它的值就來源于 open_files_limit/0.65 了,這樣間接影響了 performance_schema_max_file_instances 值,突然有種“隔山打牛”的感覺。
還有一個發現,如果將 performance_schema_max_file_instances 設置為 200000、210000、220000、230000、240000、300000 等,性能都是差不多的,唯獨設置為 230770 是有問題的。仔細研究之后發現,performance_schema_max_file_instances 最終影響的是 performance_schema 數據庫中的 file_instances 表,這個表中的數據是通過一個 HASH 表來緩存的,而這個參數決定的是該 HASH 表的大小。
后面又做了一個非常無聊的測試,是 performance_schema_max_file_instances 值與 QPS 的對比,如圖 16.6 所示。
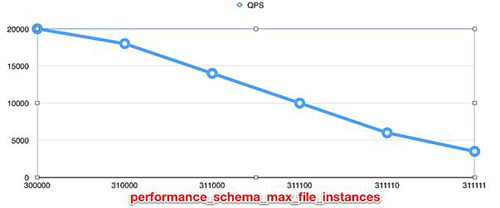
至此,一切都豁然開朗了。結合上面非常慢的堆棧,以及將 performance_schema_max_file_instances 設置為不同值的現象,可以確定,這個問題最終是 HASH 算法的問題。當 HASH 桶大小為一個比較好看的數值時,這個算法就非常快,而如果是一個比較零碎的值時,算法就非常慢了,會導致響應時間是原來的 10 倍。
總結
這個問題,確實很詭異,萬萬沒有想到是相差那么小的一個變量的問題(以至于一開始就被忽略了)。
這個問題,比較少見,只有表比較多的時候才會比較明顯(因為表比較少的時候,算法相對比較穩定)。
這個問題,查明了,其實就是一個算法方面的 BUG。
這個問題,簡單的規避方法是單獨設置 performance_schema_max_file_instances 值為 0,或者設置 performance_schema_max_file_instances 為一個比較好看的數值,又或者設置 open_files_limit 為 0.65 的整數倍,這樣都不會有問題。
這個問題,雖然影響比較小,但我們對問題的探索精神不能沒有,要了然于胸。
這個問題,到此為止。