如何將Bitcoin比特幣區(qū)塊鏈數(shù)據(jù)導(dǎo)入關(guān)系數(shù)據(jù)庫
在接觸了比特幣和區(qū)塊鏈后,我一直有一個想法,就是把所有比特幣的區(qū)塊鏈數(shù)據(jù)放入到關(guān)系數(shù)據(jù)庫(比如SQL Server)中,然后當(dāng)成一個數(shù)據(jù)倉庫,做做比特幣交易數(shù)據(jù)的各種分析。想法已經(jīng)很久了,但是一直沒有實施。最近正好有點時間,于是寫了一個比特幣區(qū)塊鏈的導(dǎo)出導(dǎo)入程序。
一、準備
我們要解析的是存儲在本地硬盤上的Bitcoin Core錢包的全量比特幣數(shù)據(jù),那么首先就是要下載并安裝好Bitcoin Core,下載地址:https://bitcoin.org/en/download 然后就等著這個軟件同步區(qū)塊鏈數(shù)據(jù)吧。目前比特幣的區(qū)塊鏈數(shù)據(jù)大概130G,所以可能需要好幾天,甚至一個星期才能將所有區(qū)塊鏈數(shù)據(jù)同步到本地。當(dāng)然如果你很早就安裝了這個軟件,那么就太好了,畢竟要等好幾天甚至一個星期,真的很痛苦。
二、建立比特幣區(qū)塊鏈數(shù)據(jù)模型
要進行區(qū)塊鏈數(shù)據(jù)的分析,那么必須得對區(qū)塊鏈的數(shù)據(jù)模型了解才行。我大概研究了一下,可以總結(jié)出4個實體:區(qū)塊、交易、輸入、輸出。而其中的關(guān)系是,一個區(qū)塊對應(yīng)多個交易,一個交易對應(yīng)多個輸入和多個輸出。除了Coinbase的輸入外,一筆輸入對應(yīng)另一筆交易中的輸出。于是我們可以得出這樣的數(shù)據(jù)模型:
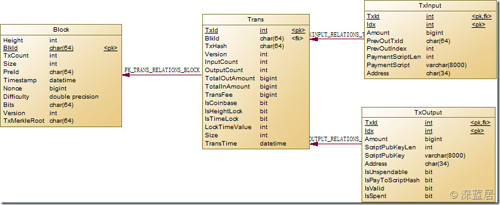
需要特別說明幾點的是:
1.TxId是自增的int,我沒有用TxHash做Transaction的PK,那是因為TxHash根本就不唯一啊!有好幾個不同區(qū)塊里面的***筆交易,也就是Coinbase交易是相同的。這其實應(yīng)該是異常數(shù)據(jù),因為相同的TxHash將導(dǎo)致只能花費一次,所以這個礦工杯具了。
2.對于一筆Coinbase 的Transaction,其輸入的PreOutTxId是0000000000000000000000000000000000000000000000000000000000000000,而其PreOutIndex是-1,這是一條不存在的TxOutput,所以我并沒有建立TXInput和TxOutput的外鍵關(guān)聯(lián)。
3.對于Block,PreId就是上一個Block的ID,而創(chuàng)世區(qū)塊的PreId是0000000000000000000000000000000000000000000000000000000000000000,也是一個不存在的BlockId,所以我沒有建立Block的自引用外鍵。
4.有很多字段其實并不是區(qū)塊鏈數(shù)據(jù)結(jié)構(gòu)中的,這些字段是我添加為了接下來方便分析用的。在導(dǎo)入的時候并沒有值,需要經(jīng)過一定的SQL運算才能得到。比如Trans里面的TotalInAmount,TransFee等。
我用的是PowerDesigner,建模完成后,生成SQL語句,即可。這是我的建表SQL:
- View Code
三、導(dǎo)出區(qū)塊鏈數(shù)據(jù)為CSV
數(shù)據(jù)模型有了,接下來我們就是建立對應(yīng)的表,然后寫程序?qū)⒈忍貛诺腂lock寫入到數(shù)據(jù)庫中。我本來用的是EntityFramework來實現(xiàn)插入數(shù)據(jù)庫的操作。但是后來發(fā)現(xiàn)實在太慢,插入一個Block甚至要等10多20秒,這要等到何年何月才能插入完啊!我試了各種方案,比如寫原生的SQL,用事務(wù),用LINQToSQL等,性能都很不理想。***終于找到了一個好辦法,那就是直接導(dǎo)出為文本文件(比如CSV格式),然后用SQL Server的Bulk Insert命令來實現(xiàn)批量導(dǎo)入,這是我已知的最快的寫入數(shù)據(jù)庫的方法。
解析Bitcoin Core下載下來的所有比特幣區(qū)塊鏈數(shù)據(jù)用的還是NBitcoin這個開源庫。只需要用到其中的BlockStore 類,即可輕松實現(xiàn)區(qū)塊鏈數(shù)據(jù)的解析。
以下是我將區(qū)塊鏈數(shù)據(jù)解析為我們的Block對象的代碼:
- View Code
至于WriteBitcoin2Csv方法,就是以一定的格式,把Block、Trans、TxInput、TxOutput這4個對象分別寫入4個文本文件中即可。
四、將CSV導(dǎo)入SQL Server
在完成了CSV文件的導(dǎo)出后,接下來就是怎么將CSV文件導(dǎo)入到SQL Server中。這個很簡單,只需要執(zhí)行BULK INSERT命令。比如這是我在測試的時候用到的SQL語句:
- bulk insert [Block] from 'F:\temp\blk205867.csv';
- bulk insert Trans from 'F:\temp\trans205867.csv';
- bulk insert TxInput from 'F:\temp\input205867.csv';
- bulk insert TxOutput from 'F:\temp\output205867.csv';
當(dāng)然在實際的情況中,我并不是這么做的。我是每1000個Block就生成4個csv文件,然后使用C#連接到數(shù)據(jù)庫,執(zhí)行bulk insert命令。執(zhí)行完成后再把這生成的4個csv文件刪除,然后再循環(huán)繼續(xù)導(dǎo)出下一批1000個Block。因為比特幣的區(qū)塊鏈數(shù)據(jù)實在太大了,如果我不分批,那么我的PC機硬盤就不夠用了,而且在導(dǎo)入SQL Server的時候我也懷疑能不能導(dǎo)入那么大批量的數(shù)據(jù)。
***,附上一張我正在導(dǎo)入中的進程圖,已經(jīng)導(dǎo)了一天了,還沒有完成,估計還得再花一、兩天時間吧。
所有區(qū)塊鏈數(shù)據(jù)都進入數(shù)據(jù)庫以后,就要發(fā)揮一下我的想象力,看能夠分析出什么有意思的結(jié)果了。