從無到有、從小到大,今日頭條大數據平臺實踐經歷的那些坑
原創【51CTO.com原創稿件】隨著公司規模的發展,數據量呈遞增式爆棚,他也見證了基礎數據平臺從無到有、從小到大的歷程。頭條在這一發展過程中對于數據使用及難度都經歷了數量級的變化。本文將與大家分享數據平臺經歷的各種坑及一些重要的技術決策。
基礎數據平臺的建設歷程
為什么要建設基礎數據平臺?
對于初創公司來講,核心是服務好用戶,做好產品功能的迭代。當公司發展到一定階段,業務開始多元化并開始精細化運營,數據需求變多,產生的數據量和數據處理復雜度也大幅增加,這時就該建設基礎數據平臺了。
2014 年,頭條每天只有幾百萬活躍用戶,支撐好產品是首要任務,并沒有專門的人負責做數據。眾多復雜業務的上線,同步會招聘大量的 PM(產品經理)和運營。基于刻到骨子里的數據驅動的思想,各種各樣的數據需求源源不斷的被提上來,這時不再是幾個數據工程師單打獨斗就能解決問題了,而讓PM 和運營直接分析數據的門檻也很高。
面對這些情況,頭條的做法是成立數據平臺團隊,把數據基礎設施像 Hadoop、Hive、Spark、Kylin 等封裝成工具,把這些工具結合通用的分析模式整合成完整的解決方案,再把這些解決方案通過平臺的形式,提供給業務部門使用。
這里需要注意數據平臺的發展是一個演進的過程,并不需要追求一開始就大而全,不同階段采用的技術能匹配當時需求就好。
基礎數據平臺的職責什么?
數據平臺的需求最初來自推薦業務,從用戶的閱讀需求出發,搭建面向全公司的通用數據平臺。其中,用戶數據(內容偏愛、行為軌跡、閱讀時間等)是頭條最龐大的數據源,這些被記錄下來的數據反映了用戶的興趣,會以各種形式傳輸和存儲,并提供給全公司各個業務系統來調用。
還要維護面向 RD(分析師)數據工具集(日志收集、入庫、調度、依賴管理、查詢、元數據、報表),面向 PM、運營的通用用戶行為分析平臺,底層查詢引擎(Hive,Presto,Kylin 等 OLAP 查詢引擎,支撐上層數據平臺和數據倉庫),平臺基礎數據倉庫及協助維護業務部門數據倉庫。
面臨哪些挑戰?
當前,頭條每日處理數據量為 7.8 PB、訓練樣本量 200 億條、服務器總量 40000 臺、Hadoop 節點 3000 臺。
數據生命周期分為生成、傳輸、入庫和統計/分析/挖掘,每個環節的難度都會隨著數據規模的變大而上升。平臺建設面臨的挑戰是由龐大的數據量和業務復雜度給數據生成、采集、傳輸、存儲和計算等帶來的一系列問題。
(1)數據生成與采集——SDK、用戶埋點
一般情況下,數據生成與采集是很簡單的事,但對于頭條這個功能眾多的 APP 來講,難點就在于每個功能背后都是一個團隊獨立運營。如果每個團隊都用自研的數據采集方法,那會給后續的進程帶來巨大的困擾。
怎么辦呢?因為頭條屬于 C 端業務公司,主要以日志形式為主,數據的主要來源是用戶行為,那么就采用事件模型來描述日志,以 SDK 形式接入,支持客戶端、服務端埋點。
這里需要注意的是:數據質量很重要,埋點規范趁早確立,臟數據是不可避免的,可以引入必要的約束、清洗等。
- 埋點。埋點是用戶在使用某一個功能時,產生的一段數據。頭條初期,埋點由各業務場景自定義日志格式,之后埋點統一到事件模型,保證了信息的結構化和自描述,降低了后續使用成本,并復用統一的解析和清洗流程、數據倉庫的入庫和行為分析平臺的導入。
埋點的管理,也由通過文檔、Wiki 等方式演進成埋點管理系統,覆蓋整個埋點生命周期。這樣一來,也得到了埋點元信息的描述,后續可應用在數據清洗、分析平臺等場景,同時埋點的上線流程實現標準化,客戶端也可進行自動化測試。
SDK。數據平臺實現了通用的客戶端埋點 SDK 和服務端埋點 SDK,放棄之前按約定生成數據的方式,可以保證生成的日志符合埋點規范,并統一 App 啟動、設備標識等的基本口徑,也減少了新 App 適配成本。
對數據的描述由使用 JSON 改為 Protobuf,這樣就可通過 IDL 實現強制約束,包括數據類型、字段命名等。
除了日志數據,關系數據庫中的數據也是數據分析的重要來源。頭條在數據的采集方式上,用 Spark 實現類 Sqoop 的分布式抓取替代了早期定期用單機全量抓取 MySQL 數據表的方式,有效的提升了抓取速度,突破了單機瓶頸。
再之后為了減少 MySQL 壓力,選用 Canal 來接收 MySQL binlog,離線 merge 出全量表,這樣就不再直接讀 MySQL 了,而且對千萬/億級大表的處理速度也會更快。
(2)數據傳輸——Kafka 做消息總線連接在線和離線系統
數據在客戶端向服務端回傳或者直接在服務端產生時,可以認為是在線狀態。當數據落地到統計分析相關的基礎設施時,就變成離線的狀態了。在線系統和離線系統采用消息隊列來連接。
頭條的數據傳輸以 Kafka 作為數據總線,所有實時和離線數據的接入都要通過 Kafka,包括日志、binlog 等。這里值得注意的是:盡早引入消息隊列,與業務系統解耦。
頭條的數據基礎設施以社區開源版本作為基礎,并做了大量的改進,也回饋給了社區,同時還有很多自研的組件。
因為以目前的數據和集群規模,直接使用社區版本乃至企業版的產品,都會遇到大量困難。像數據接入,就使用自研 Databus,作為單機 Agent,封裝 Kafka 寫入,提供異步寫入、buffer、統一配置等 feature。
Kafka 數據通過 Dump 落地到 HDFS,供后續離線處理使用。隨著數據規模的增加,Dump 的實現也經歷了幾個階段。最初實現用的是類似 Flume 模式的單機上傳,很快遇到了瓶頸,實現改成了通過 Storm 來實現多機分布式的上傳,支持的數據吞吐量大幅增加。
現在開發了一個叫 DumpService 的服務,作為托管服務方便整合到平臺工具上,底層實現切換到了 SparkStreaming,并實現了 exactly-once 語義,保證 Dump 數據不丟不重。
(3)數據入庫——數據倉庫、ETL(抽取轉換加載)
頭條的數據源很復雜,直接拿來做分析并不方便。但是到數據倉庫這一層級,會通過數據處理的過程,也就是 ETL,把它建設成一個層次完備的適合分析的一個個有價值的數倉。在數倉之上,就可以讓數據分析師和數據 RD 通過 SQL 和多維分析等更高效的手段使用數據。
數據倉庫中數據表的元信息都放在 Hivemetastore 里,數據表在 HDFS 上的存儲格式以 Parquet 為主,這是一種列式存儲格式,對于嵌套數據結構的支持也很好。
頭條有多種 ETL 的實現模式在并存,對于底層數據構建,一種選擇是使用 Python 通過 HadoopStreaming 來實現 Map Reduce 的任務,但現在更傾向于使用 Spark 直接生成 Parquet 數據,Spark 相比 MapReduce 有更豐富的處理原語,代碼實現可以更簡潔,也減少了中間數據的落地量。對于高層次的數據表,會直接使用 HiveSQL 來描述 ETL 過程。
(4)數據計算——計算引擎的演進
數據倉庫中的數據表如何能被高效的查詢很關鍵,因為這會直接關系到數據分析的效率。常見的查詢引擎可以歸到三個模式中,Batch 類、MPP 類、Cube 類,頭條在 3 種模式上都有所應用。
頭條最早使用的查詢引擎是 InfoBright,Infopight 可以認為是支持了列式存儲的 MySQL,對分析類查詢更友好,但 Infopight 只支持單機。隨著數據量的增加,很快換成了 Hive,Hive 是一個很穩定的選擇,但速度一般。
為了更好的支持 Adhoc 交互式查詢,頭條開始調研 MPP 類查詢引擎,先后使用過 Impala 和 Presto,但在頭條的數據量級下都遇到了穩定性的問題。
頭條現在的方案是混合使用 Spark SQL 和 Hive,并自研 QAP 查詢分析系統,自動分析并分發查詢 SQL 到適合的查詢引擎。在 Cube 類查詢引擎上,頭條采用了 Kylin,現在也是 Kylin 在國內***的用戶之一。
(5)數據門戶——為業務的數據分析提供整體解決方案
對于大部分需求相對簡單的公司來說,數據最終可以產出報表就夠用了,如做一個面向管理層的報表,可以讓老板直觀的了解一些關鍵性指標,這是最基礎的數據應用模式。
再深入一點,就需要匯總各種來源的業務數據,提供多種維度和指標來進行更深入的探索型分析,得到的結論用來指導產品的迭代和運營。頭條絕大部分業務都是數據驅動的,都需要產出和分析大量的數據,這就或多或少需要用到平臺提供的系列工具。
頭條開發了一套叫數據門戶的平臺系統,提供給業務部門使用,對數據生命周期各個環節都提供了相應支持。數據門戶提供的工具都是聲明式的,也就是讓使用者只需要說明要實現什么目的,具體實現的復雜細節都隱藏起來,對使用者更友好。
通過這些工具,可以讓業務部門的 RD 、分析師、PM 等將精力放在業務分析本身,而不是去學習大量數據基礎設施的使用方法。
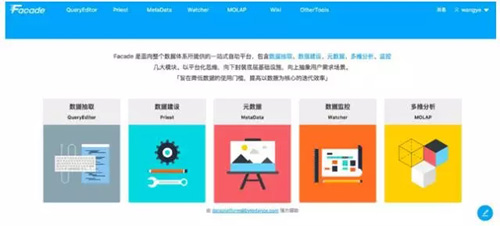
數據抽取平臺 QueryEditor
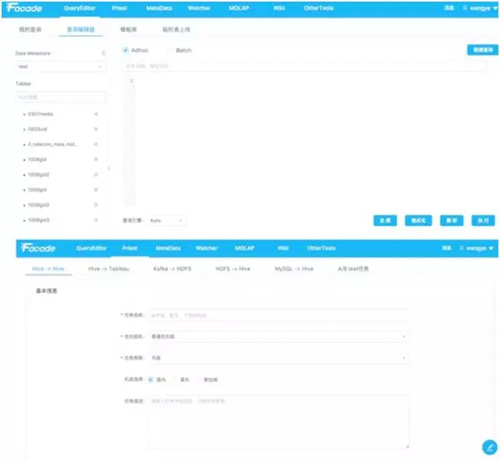
數據抽取平臺 QueryEdito 使用界面
數據抽取平臺 QueryEditor,用于數據生命周期管理,對 Kafka 數據 Dump、數據倉庫入庫、SQL 查詢托管等做了統一支持。
結語
基礎數據平臺的建設理念是通過提供整體解決方案,降低數據使用門檻,方便各種業務接入。互聯網產品的數據分析模式也是相對固定的,比如事件多維分析、留存分析、漏斗分析等,把這些分析模式抽象出工具,也能覆蓋住大部分常用需求。
同時,期望參與業務的人比如 PM 等能更直接的掌握數據,通過相關工具的支持自行實現數據需求,盡量解放業務部門工程師的生產力,不至于被各種臨時跑數需求困擾。而對于更專業的數據分析師的工作,也會提供更專業的工具支持。
王燁
今日頭條數據平臺架構師
2014 年加入今日頭條,目前負責頭條基礎數據平臺的技術架構,解決海量數據規模下推薦系統和用戶產品的統計分析問題,并見證了頭條數據平臺從無到有、從小到大的歷程。加入頭條前,曾就職于豆瓣負責 Antispam 系統的研發。
【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】