IT運(yùn)維平臺(tái)算法背后的兩大“神助攻”
原創(chuàng)【51CTO.com原創(chuàng)稿件】智能運(yùn)維(AIops)是目前 IT 運(yùn)維領(lǐng)域最火熱的詞匯,全稱(chēng)是 Algorithmic IT operations platforms,正規(guī)翻譯是『基于算法的 IT 運(yùn)維平臺(tái)』,直觀可見(jiàn)算法是智能運(yùn)維的核心要素之一。
本文主要談算法對(duì)運(yùn)維的作用,涉及異常檢測(cè)和歸因分析兩方面,圍繞運(yùn)維系統(tǒng) Kale 中 skyline、Oculus 模塊、Opprentice 系統(tǒng)、Granger causality(格蘭杰因果關(guān)系)、FastDTW 算法等細(xì)節(jié)展開(kāi)。
一、異常檢測(cè)
異常檢測(cè),是運(yùn)維工程師們最先可能接觸的地方了。畢竟監(jiān)控告警是所有運(yùn)維工作的基礎(chǔ)。設(shè)定告警閾值是一項(xiàng)耗時(shí)耗力的工作,需要運(yùn)維人員在充分了解業(yè)務(wù)的前提下才能進(jìn)行,還得考慮業(yè)務(wù)是不是平穩(wěn)發(fā)展?fàn)顟B(tài),否則一兩周改動(dòng)一次,運(yùn)維工程師絕對(duì)是要發(fā)瘋的。
如果能將這部分工作交給算法來(lái)解決,無(wú)疑是推翻一座大山。這件事情,機(jī)器學(xué)習(xí)當(dāng)然可以做到。但是不用機(jī)器學(xué)習(xí),基于數(shù)學(xué)統(tǒng)計(jì)的算法,同樣可以,而且效果也不差。
異常檢測(cè)之Skyline異常檢測(cè)模塊
2013年,Etsy 開(kāi)源了一個(gè)內(nèi)部的運(yùn)維系統(tǒng),叫 Kale。其中的 skyline 部分,就是做異常檢測(cè)的模塊,它提供了 9 種異常檢測(cè)算法:
-
first_hour_average、
-
simple_stddev_from_moving_average、
-
stddev_from_moving_average、
-
mean_subtraction_cumulation、
-
least_squares
-
histogram_bins、
-
grubbs、
-
median_absolute_deviation、
-
Kolmogorov-Smirnov_test
簡(jiǎn)要的概括來(lái)說(shuō),這9種算法分為兩類(lèi):
-
從正態(tài)分布入手:假設(shè)數(shù)據(jù)服從高斯分布,可以通過(guò)標(biāo)準(zhǔn)差來(lái)確定絕大多數(shù)數(shù)據(jù)點(diǎn)的區(qū)間;或者根據(jù)分布的直方圖,落在過(guò)少直方里的數(shù)據(jù)就是異常;或者根據(jù)箱體圖分析來(lái)避免造成長(zhǎng)尾影響。
-
從樣本校驗(yàn)入手:采用 Kolmogorov-Smirnov、Shapiro-Wilk、Lilliefor 等非參數(shù)校驗(yàn)方法。
這些都是統(tǒng)計(jì)學(xué)上的算法,而不是機(jī)器學(xué)習(xí)的事情。當(dāng)然,Etsy 這個(gè) Skyline 項(xiàng)目并不是異常檢測(cè)的全部。
首先,這里只考慮了一個(gè)指標(biāo)自己的狀態(tài),從縱向的時(shí)序角度做異常檢測(cè)。而沒(méi)有考慮業(yè)務(wù)的復(fù)雜性導(dǎo)致的橫向異常。其次,提供了這么多種算法,到底一個(gè)指標(biāo)在哪種算法下判斷的更準(zhǔn)?這又是一個(gè)很難判斷的事情。
問(wèn)題一:實(shí)現(xiàn)上的抉擇。同樣的樣本校驗(yàn)算法,可以用來(lái)對(duì)比一個(gè)指標(biāo)的當(dāng)前和歷史情況,也可以用來(lái)對(duì)比多個(gè)指標(biāo)里哪個(gè)跟別的指標(biāo)不一樣。
問(wèn)題二:Skyline 其實(shí)自己采用了一種特別樸實(shí)和簡(jiǎn)單的辦法來(lái)做補(bǔ)充——9 個(gè)算法每人一票,投票達(dá)到閾值就算數(shù)。至于這個(gè)閾值,一般算 6 或者 7 這樣,即占到大多數(shù)即可。
異常檢測(cè)之Opprentice系統(tǒng)
作為對(duì)比,面對(duì)相同的問(wèn)題,百度 SRE 的智能運(yùn)維是怎么處理的。在去年的 APMcon 上,百度工程師描述 Opprentice 系統(tǒng)的主要思想時(shí),用了這么一張圖:
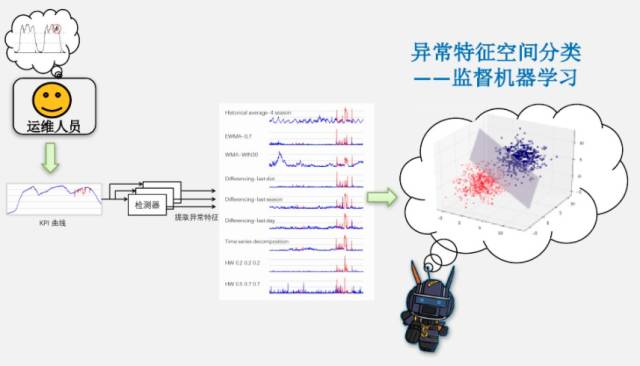
Opprentice 系統(tǒng)的主體流程為:
-
KPI 數(shù)據(jù)經(jīng)過(guò)各式 detector 計(jì)算得到每個(gè)點(diǎn)的諸多 feature;
-
通過(guò)專(zhuān)門(mén)的交互工具,由運(yùn)維人員標(biāo)記 KPI 數(shù)據(jù)的異常時(shí)間段;
-
采用隨機(jī)森林算法做異常分類(lèi)。
其中 detector 有14種異常檢測(cè)算法,如下圖:

我們可以看到其中很多算法在 Etsy 的 Skyline 里同樣存在。不過(guò),為避免給這么多算法調(diào)配參數(shù),直接采用的辦法是:每個(gè)參數(shù)的取值范圍均等分一下——反正隨機(jī)森林不要求什么特征工程。如,用 holt-winters 做為一類(lèi) detector。holt-winters 有α,β,γ 三個(gè)參數(shù),取值范圍都是 [0, 1]。那么它就采樣為 (0.2, 0.4, 0.6, 0.8),也就是 4 ** 3 = 64 個(gè)可能。那么每個(gè)點(diǎn)就此得到 64 個(gè)特征值。
異常檢測(cè)之 Opprentice 系統(tǒng)與 Skyline 很相似
Opprentice 系統(tǒng)整個(gè)流程跟 skyline 的思想相似之處在于先通過(guò)不同的統(tǒng)計(jì)學(xué)上的算法來(lái)嘗試發(fā)現(xiàn)異常,然后通過(guò)一個(gè)多數(shù)同意的方式/算法來(lái)確定最終的判定結(jié)果。
只不過(guò)這里百度采用了一個(gè)隨機(jī)森林的算法,來(lái)更靠譜一點(diǎn)的投票。而 Etsy 呢?在 skyline 開(kāi)源幾個(gè)月后,他們內(nèi)部又實(shí)現(xiàn)了新版本,叫 Thyme。利用了小波分解、傅里葉變換、Mann-whitney 檢測(cè)等等技術(shù)。
另外,社區(qū)在 Skyline 上同樣做了后續(xù)更新,Earthgecko 利用 Tsfresh 模塊來(lái)提取時(shí)序數(shù)據(jù)的特征值,以此做多時(shí)序之間的異常檢測(cè)。我們可以看到,后續(xù)發(fā)展的兩種 Skyline,依然都沒(méi)有使用機(jī)器學(xué)習(xí),而是進(jìn)一步深度挖掘和調(diào)整時(shí)序相關(guān)的統(tǒng)計(jì)學(xué)算法。
開(kāi)源社區(qū)除了 Etsy,還有諸多巨頭也開(kāi)源過(guò)各式其他的時(shí)序異常檢測(cè)算法庫(kù),大多是在 2015 年開(kāi)始的。列舉如下:
-
Yahoo! 在去年開(kāi)源的 egads 庫(kù)。(Java)
-
Twitter 在去年開(kāi)源的 anomalydetection 庫(kù)。(R)
-
Netflix 在 2015 年開(kāi)源的 Surus 庫(kù)。(Pig,基于PCA)
其中 Twitter 這個(gè)庫(kù)還被 port 到 Python 社區(qū),有興趣的讀者也可以試試。
二、歸因分析
歸因分析是運(yùn)維工作的下一大塊內(nèi)容,就是收到報(bào)警以后的排障。對(duì)于簡(jiǎn)單故障,應(yīng)對(duì)方案一般也很簡(jiǎn)單,采用 service restart engineering~ 但是在大規(guī)模 IT 環(huán)境下,通常一個(gè)故障會(huì)觸發(fā)或?qū)е麓竺娣e的告警發(fā)生。如果能從大面積的告警中,找到最緊迫最要緊的那個(gè),肯定能大大的縮短故障恢復(fù)時(shí)間(MTTR)。
這個(gè)故障定位的需求,通常被歸類(lèi)為根因分析(RCA,Root Cause Analysis)。當(dāng)然,RCA 可不止故障定位一個(gè)用途,性能優(yōu)化的過(guò)程通常也是 RCA 的一種。
歸因分析之 Oculus 模塊
和異常檢測(cè)一樣,做 RCA 同樣是可以統(tǒng)計(jì)學(xué)和機(jī)器學(xué)習(xí)方法并行的~我們還是從統(tǒng)計(jì)學(xué)的角度開(kāi)始。依然是 Etsy 的 kale 系統(tǒng),其中除了做異常檢測(cè)的 skyline 以外,還有另外一部分,叫 Oculus。而且在 Etsy 重構(gòu) kale 2.0 的時(shí)候,Oculus 被認(rèn)為是1.0 最成功的部分,完整保留下來(lái)了。
Oculus 的思路,用一句話(huà)描述,就是:如果一個(gè)監(jiān)控指標(biāo)的時(shí)間趨勢(shì)圖走勢(shì),跟另一個(gè)監(jiān)控指標(biāo)的趨勢(shì)圖長(zhǎng)得比較像,那它們很可能是被同一個(gè)根因影響的。那么,如果整體 IT 環(huán)境內(nèi)的時(shí)間同步是可靠的,且監(jiān)控指標(biāo)的顆粒度比較細(xì)的情況下,我們就可能近似的推斷:跟一個(gè)告警比較像的最早的那個(gè)監(jiān)控指標(biāo),應(yīng)該就是需要重點(diǎn)關(guān)注的根因了。
Oculus 截圖如下:
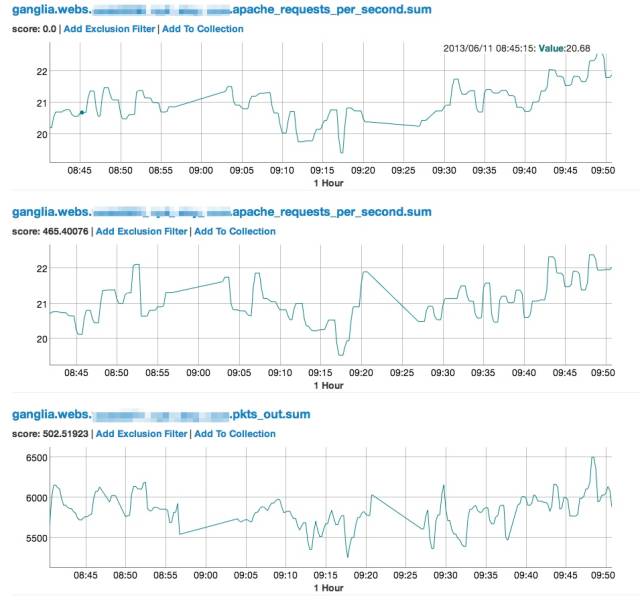
這部分使用的計(jì)算方式有兩種:
-
歐式距離,就是不同時(shí)序數(shù)據(jù),在相同時(shí)刻做對(duì)比。假如0分0秒,a和b相差1000,0分5秒,也相差1000,依次類(lèi)推。
-
FastDTW,則加了一層偏移量,0分0秒的a和0分5秒的b相差1000,0分5秒的a和0分10秒的b也相差1000,依次類(lèi)推。當(dāng)然,算法在這個(gè)簡(jiǎn)單假設(shè)背后,是有很多降低計(jì)算復(fù)雜度的具體實(shí)現(xiàn)的,這里就不談了。
唯一可惜的是 Etsy 當(dāng)初實(shí)現(xiàn) Oculus 是基于 ES 的 0.20 版本,后來(lái)該版本一直沒(méi)有更新。現(xiàn)在停留在這么老版本的 ES 用戶(hù)應(yīng)該很少了。除了 Oculus,還有很多其他產(chǎn)品,采用不同的統(tǒng)計(jì)學(xué)原理,達(dá)到類(lèi)似的效果。
歸因分析之 Granger causality
Granger causality(格蘭杰因果關(guān)系)是一種算法,簡(jiǎn)單來(lái)說(shuō)它通過(guò)比較“已知上一時(shí)刻所有信息,這一時(shí)刻 X 的概率分布情況”和“已知上一時(shí)刻除 Y 以外的所有信息,這一時(shí)刻 X 的概率分布情況”,來(lái)判斷 Y 對(duì) X 是否存在因果關(guān)系。
可能有了解過(guò)一點(diǎn)機(jī)器學(xué)習(xí)信息的讀者會(huì)很詫異了:不是說(shuō)機(jī)器只能反應(yīng)相關(guān)性,不能反應(yīng)因果性的么?需要說(shuō)明一下,這里的因果,是統(tǒng)計(jì)學(xué)意義上的因果,不是我們通常哲學(xué)意義上的因果。
統(tǒng)計(jì)學(xué)上的因果定義是:『在宇宙中所有其他事件的發(fā)生情況固定不變的條件下,如果一個(gè)事件 A 的發(fā)生與不發(fā)生對(duì)于另一個(gè)事件 B 的發(fā)生的概率有影響,并且這兩個(gè)事件在時(shí)間上有先后順序(A 前 B 后),那么我們便可以說(shuō) A 是 B 的原因。』
歸因分析之皮爾遜系數(shù)
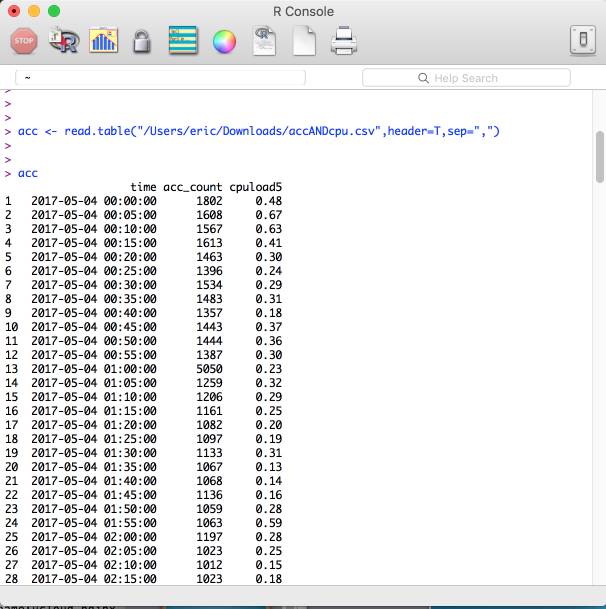
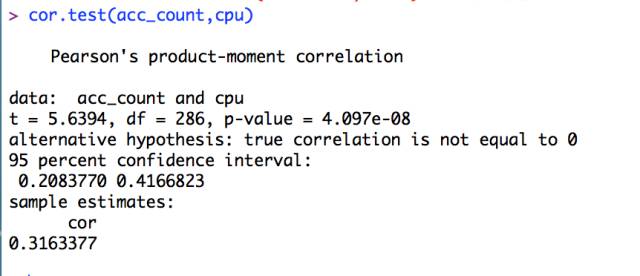
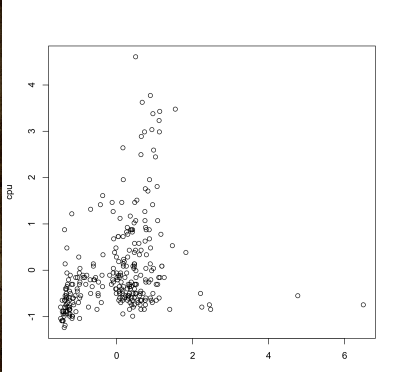
另一個(gè)常用的算法是皮爾遜系數(shù)。下圖是某 ITOM 軟件的實(shí)現(xiàn):
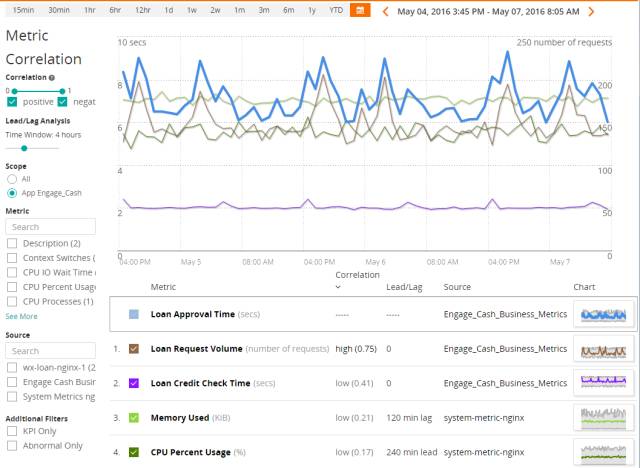
我們可以看到,其主要元素和采用 FastDTW 算法的 Oculus 類(lèi)似:correlation 表示相關(guān)性的評(píng)分、lead/lag 表示不同時(shí)序數(shù)據(jù)在時(shí)間軸上的偏移量。 皮爾遜系數(shù)在 R 語(yǔ)言里可以特別簡(jiǎn)單的做到。比如我們拿到同時(shí)間段的訪(fǎng)問(wèn)量和服務(wù)器 CPU 使用率: 然后運(yùn)行如下命令: 可以看到如下結(jié)果輸出: 對(duì)應(yīng)的可視化圖形如下: 這就說(shuō)明網(wǎng)站數(shù)據(jù)訪(fǎng)問(wèn)量和 CPU 存在弱相關(guān),同時(shí)從散點(diǎn)圖上看兩者為非線(xiàn)性關(guān)系。因此訪(fǎng)問(wèn)量上升不一定會(huì)真正影響 CPU 消耗。 其實(shí) R 語(yǔ)言不太適合嵌入到現(xiàn)有的運(yùn)維系統(tǒng)中。那這時(shí)候使用 Elasticsearch 的工程師就有福了。ES 在大家常用的 metric aggregation、bucket aggregation、pipeline aggregation 之外,還提供了一種 matrix aggregation,目前唯一支持的 matrix_stats 就是采用了皮爾遜系數(shù)的計(jì)算,接口文檔見(jiàn): https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-matrix-stats-aggregation.html 唯一需要注意的就是,要求計(jì)算相關(guān)性的兩個(gè)字段必須同時(shí)存在于一個(gè) event 里。所以沒(méi)法直接從現(xiàn)成的 ES 數(shù)據(jù)中請(qǐng)求不同的 date_histogram,然后計(jì)算,需要自己手動(dòng)整理一遍,轉(zhuǎn)儲(chǔ)回 ES 再計(jì)算。 饒琛琳,目前就職日志易,有十年運(yùn)維工作經(jīng)驗(yàn)。在微博擔(dān)任系統(tǒng)架構(gòu)師期間,負(fù)責(zé)帶領(lǐng)11人的SRE團(tuán)隊(duì)。著有《網(wǎng)站運(yùn)維技術(shù)與實(shí)踐》、《ELKstack權(quán)威指南》,合譯有《Puppet 3 Cookbook》、《Learning Puppet 4》。在眾多技術(shù)大會(huì)上分享過(guò)自動(dòng)化運(yùn)維與數(shù)據(jù)分析相關(guān)主題。 【51CTO原創(chuàng)稿件,合作站點(diǎn)轉(zhuǎn)載請(qǐng)注明原文作者和出處為51CTO.com】