實(shí)用 | Apache Kudu讀寫(xiě)路徑
Kudu的體系架構(gòu)已經(jīng)具備了提供良好分析性能的能力,同時(shí)還能夠接收插入和更新操作的連續(xù)流。為了使用戶(hù)能夠?qū)W⒂谄渥铌P(guān)心的內(nèi)容,Kudu提供了簡(jiǎn)單的API,而封裝了后臺(tái)的復(fù)雜性。但是一些高級(jí)用戶(hù)希望了解內(nèi)部部件,以理解Kudu如何能夠快速分析快速數(shù)據(jù),以及如何更好地利用其功能。本篇博文旨在向用戶(hù)介紹向Kudu內(nèi)寫(xiě)入數(shù)據(jù)以及從Kudu中讀取數(shù)據(jù)時(shí)在其后臺(tái)會(huì)發(fā)生什么。本篇博文假設(shè)讀者對(duì)本文中所介紹的Kudu架構(gòu)已經(jīng)有一個(gè)基本的了解。
多版本并發(fā)控制(MVCC)
數(shù)據(jù)庫(kù)使用并發(fā)控制方法確保用戶(hù)始終看到一致性的結(jié)果,不管是否進(jìn)行并發(fā)寫(xiě)入操作。Kudu使用了一種稱(chēng)為多版本并發(fā)控制(MVCC)的方法,該方法可以跟蹤正在進(jìn)行的操作,并通過(guò)確保讀取操作只能讀到已提交的操作來(lái)保證一致性。Kudu使用多版本并發(fā)控制(MVCC)的主要優(yōu)點(diǎn)是允許讀取者(通常是大型掃描程序)不必獲取鎖定,分析作業(yè)不會(huì)阻止同一數(shù)據(jù)上的并發(fā)寫(xiě)入者,這樣就可以顯著提高其掃描性能。每個(gè)寫(xiě)入都使用系統(tǒng)生成的時(shí)間戳進(jìn)行標(biāo)記,該時(shí)間戳保證在tablet中是唯一的。當(dāng)用戶(hù)創(chuàng)建掃描程序從tablet讀取數(shù)據(jù)時(shí),他們可以選擇兩種讀取模式:
- READ_LATEST(默認(rèn))在tablet中獲取多版本并發(fā)控制(MVCC)當(dāng)前狀態(tài)的快照,無(wú)法保證***版本。也就是說(shuō),該功能可讀取在副本上提交的任何寫(xiě)入,但是由于寫(xiě)入可以無(wú)序執(zhí)行,所以不保證其一致性。而且由于副本可能落后于同一tablet中的其他副本,因此不能保證讀取的是***版本。
- READ_AT_SNAPSHOT可以獲取多版本并發(fā)控制(MVCC)的快照,其中包括基于特定時(shí)間戳的行版本,無(wú)論是用戶(hù)選擇還是系統(tǒng)選擇(“當(dāng)前”時(shí)間)。tablet等到這個(gè)時(shí)間戳是“安全的”(即已經(jīng)完成所有具有較低時(shí)間戳的飛行中寫(xiě)入操作),并且由于具有較晚的時(shí)間戳,tablet中的進(jìn)一步寫(xiě)入將被掃描程序忽略。在這種模式下,掃描是一致且可重復(fù)的。
通過(guò)提供您自己的掃描時(shí)間戳,第二種快照類(lèi)型具備發(fā)布 “時(shí)間行程讀取”的能力,這反映了在該時(shí)間點(diǎn)數(shù)據(jù)庫(kù)的狀態(tài)。這意味著用戶(hù)只能看到單個(gè)版本的行,但在內(nèi)部Kudu可以存儲(chǔ)行的多個(gè)版本以提供多版本并發(fā)控制(MVCC)快照功能。
Raft
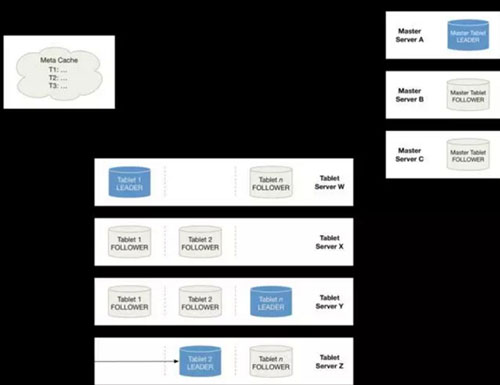
Kudu中的表被分割成稱(chēng)為tablet的連續(xù)片段,并且為了實(shí)現(xiàn)容錯(cuò)功能,每個(gè)tablet都在多個(gè)tablet服務(wù)器上進(jìn)行復(fù)制。 Kudu使用Raft一致性算法以保證對(duì)tablet進(jìn)行的更改獲得其所有副本的同意。在任何時(shí)候,其中一個(gè)副本會(huì)被選為***,而其他則是追隨者。任何副本都可以為讀取提供服務(wù),但只有***可以接受寫(xiě)入。Raft保留了復(fù)制的操作日志,只有在大多數(shù)副本被持久存儲(chǔ)在日志中時(shí)才會(huì)對(duì)其進(jìn)行確認(rèn)。復(fù)制日志是一個(gè)抽象概念,實(shí)際上由tablet的寫(xiě)入日志(WAL)表示。具有N個(gè)副本(通常為3或5個(gè))的tablet可以繼續(xù)接受最多(N-1)/ 2個(gè)副本的失敗。
Tablet發(fā)現(xiàn)
當(dāng)創(chuàng)建Kudu客戶(hù)端時(shí),其會(huì)從主服務(wù)器上獲取tablet位置信息,然后直接與服務(wù)于該tablet的服務(wù)器進(jìn)行交談。為了優(yōu)化讀取和寫(xiě)入路徑,客戶(hù)端將保留該信息的本地緩存,以防止他們?cè)诿總€(gè)請(qǐng)求時(shí)需要查詢(xún)主機(jī)的tablet位置信息。隨著時(shí)間的推移,客戶(hù)端的緩存可能會(huì)變得過(guò)時(shí),并且當(dāng)寫(xiě)入被發(fā)送到不再是tablet***的tablet服務(wù)器時(shí),則將被拒絕。然后,客戶(hù)端將通過(guò)查詢(xún)主服務(wù)器發(fā)現(xiàn)新***的位置來(lái)更新其緩存。
寫(xiě)入路徑
寫(xiě)入操作是指需進(jìn)行插入、更新或刪除操作的一組行。需要注意的事項(xiàng)是Kudu強(qiáng)制執(zhí)行主關(guān)鍵字的唯一性,主關(guān)鍵字是可以更改行的唯一標(biāo)識(shí)符。為了強(qiáng)制執(zhí)行此約束條件,Kudu必須以不同的方式處理插入和更新操作,并且這會(huì)影響tablet服務(wù)器如何處理寫(xiě)入。
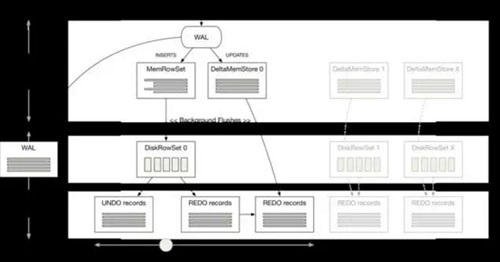
Kudu中的每個(gè)tablet包含預(yù)寫(xiě)式日志(WAL)和多個(gè)行集合(RowSet),它們是保存在存儲(chǔ)器和磁盤(pán)上(被刷新時(shí))的不相交的行集合。寫(xiě)入操作先被提交到tablet的預(yù)寫(xiě)式日志(WAL),并根據(jù)Raft 一致性算法取得追隨節(jié)點(diǎn)的同意,然后才會(huì)被添加到其中一個(gè)tablet的內(nèi)存中:插入會(huì)被添加到tablet的MemRowSet中。為了在MemRowSet中支持多版本并發(fā)控制(MVCC),對(duì)最近插入的行(即尚未刷新到磁盤(pán)的新的行)的更新和刪除操作將被追加到MemRowSet中的原始行之后以生成重做(REDO)記錄的列表。讀取者需要應(yīng)用相關(guān)的重做(REDO)記錄,根據(jù)掃描程序給定的時(shí)間戳構(gòu)建行的正確快照。
當(dāng)MemRowSet填滿時(shí),則被刷新到磁盤(pán)并成為一個(gè)DiskRowSet。為了支持磁盤(pán)中存儲(chǔ)數(shù)據(jù)的多版本并發(fā)控制(MVCC)功能,DiskRowSets被分為兩種不同的文件類(lèi)型。 MemRowSet中行的***版本(即應(yīng)用了其所有重做(REDO)記錄的原始插入)被寫(xiě)入到基礎(chǔ)數(shù)據(jù)文件。這是一種柱狀文件格式(非常像Parquet),用于快速、高效的讀取訪問(wèn),其賦予了Kudu支持分析訪問(wèn)模式的能力。MemRowSet中存在的行的先前版本(即重做(REDO)記錄的倒序)作為一組撤銷(xiāo)(UNDO)記錄寫(xiě)入增量文件。時(shí)間行程讀取可以應(yīng)用相關(guān)的撤銷(xiāo)(UNDO)記錄,從早期的時(shí)間點(diǎn)構(gòu)建行的正確快照。
更新已被編碼和壓縮的柱狀格式化數(shù)據(jù)文件需要重寫(xiě)整個(gè)文件,因此基礎(chǔ)數(shù)據(jù)文件一旦被刷新則被認(rèn)為是不可變的。此外,行關(guān)鍵字唯一性約束意味著基本記錄的更新和刪除不能被添加到tablet的MemRowSet中,而是被添加到名為DeltaMemStore的單獨(dú)的內(nèi)存存儲(chǔ)器中。像MemRowSet一樣,所有的變化都將被添加到DeltaMemStore中作為一組重做(REDO)記錄;當(dāng)DeltaMemStore填滿時(shí),重做(REDO)記錄將被刷新到磁盤(pán)上存儲(chǔ)的增量文件中。每個(gè)DiskRowSet都存在一個(gè)單獨(dú)的DeltaMemStore。如需構(gòu)建行的正確快照,讀取者必須在應(yīng)用相關(guān)撤銷(xiāo)(UNDO)或重做(REDO)記錄之前首先找到行的基本記錄。
壓縮 隨著時(shí)間的推移,tablet會(huì)積累許多DiskRowSets,并且會(huì)在行更新時(shí)累積很多增量重做(REDO)文件。當(dāng)插入一個(gè)關(guān)鍵字時(shí),為了強(qiáng)制執(zhí)行主關(guān)鍵字唯一性,Kudu會(huì)針對(duì)RowSets查詢(xún)一組布隆過(guò)濾器,來(lái)找到可能包含該關(guān)鍵字的Rowset。越多的布隆過(guò)濾器檢查及隨后的DiskRowSet搜索,寫(xiě)入操作就會(huì)變得越慢。隨著更多DiskRowSets的積累,必須采取措施確保寫(xiě)入性能不會(huì)下降。此外,隨著每個(gè)RowSet累積更多的重做(REDO)增量文件,為了將基礎(chǔ)數(shù)據(jù)轉(zhuǎn)換為行的***版本,需要執(zhí)行更多的工作掃描。這意味著如果不采取任何行動(dòng),讀取性能也會(huì)隨時(shí)間而下降。Kudu可以通過(guò)執(zhí)行壓縮功能來(lái)處理這些問(wèn)題,其中包括三種類(lèi)型的壓縮:
- 微小增量壓縮(Minor delta compaction)可以在不會(huì)觸及基礎(chǔ)數(shù)據(jù)的前提下,通過(guò)將增量文件合并在一起以減少文件的數(shù)量。其結(jié)果是讀取操作必須尋求更少的增量文件來(lái)生成當(dāng)前版本的行。
- 重大增量壓縮(Major delta compaction)將重做(REDO)記錄遷移到撤銷(xiāo)(UNDO)記錄中,并更新基礎(chǔ)數(shù)據(jù)。考慮到大多數(shù)讀取將讀取最近的快照(從基礎(chǔ)數(shù)據(jù)的時(shí)間向前計(jì)算),并且基礎(chǔ)數(shù)據(jù)將以最有效的方式進(jìn)行存儲(chǔ)(被編碼和壓縮),最小化重做(REDO)記錄存儲(chǔ)的數(shù)量可以獲得更有效的讀取。在重大壓縮期間,行的重做(REDO)記錄可以合并到基礎(chǔ)數(shù)據(jù)中,并替換為包含先前版本行的等效的撤銷(xiāo)(UNDO)記錄集。可以對(duì)列的任何子集執(zhí)行重大壓縮,因此如果某列與其他列相比收到更多的更新,就可以在單個(gè)列上執(zhí)行壓縮,通過(guò)避免重寫(xiě)未更改的數(shù)據(jù)以減少重大增量壓縮的I / O。
- 行集合壓縮(RowSet compaction)可以將范圍內(nèi)重疊的行集合(RowSets)組合在一起,從而生成更少的行集合(RowSets),從而加快寫(xiě)入速度。
這是針對(duì)壓縮過(guò)程的簡(jiǎn)要介紹,旨在方便讀者理解Kudu執(zhí)行的后臺(tái)工作以管理和優(yōu)化其物理存儲(chǔ)。在博客中我們將發(fā)表后續(xù)文章更詳細(xì)地描述該壓縮過(guò)程。讀取路徑 當(dāng)客戶(hù)端從Kudu的表中讀取數(shù)據(jù)時(shí),必須首先建立需要連接的系列tablet服務(wù)器。通過(guò)執(zhí)行tablet發(fā)現(xiàn)過(guò)程(如上所述)來(lái)確定包含要讀取的主關(guān)鍵字范圍的tablet的位置(讀取不必在***tablet上發(fā)生,除非用戶(hù)明確選擇該選項(xiàng))。tablet隨后使用掃描程序基于行集合(RowSets)和相關(guān)撤銷(xiāo)(UNDO)或重做(REDO)增量記錄生成最終行。首先,tablet必須確定包含基本記錄的行集合(RowSet)。然后掃描MemRowSet以及一個(gè)或多個(gè)DiskRowSets。***,tablet將遍歷所選的行集合(RowSet),匹配該掃描的謂詞并生成最終記錄。
在MemRowSet中,掃描程序?qū)?shí)現(xiàn)每一行的完整投影并應(yīng)用任何增量記錄。由于所有操作都發(fā)生在內(nèi)存中因此可以非常快速地完成。對(duì)于每一個(gè)DiskRowSet而言,掃描程序?qū)⒚看螌?shí)現(xiàn)一列,并且在轉(zhuǎn)到下一列前應(yīng)用對(duì)當(dāng)前列任何增量記錄和謂詞。 只有與掃描的謂詞匹配的列才可以從磁盤(pán)讀取,這使得磁盤(pán)I / O非常高效,也賦予了Kudu快速的分析性能。Kudu將優(yōu)先掃描已定義謂詞的列。如果謂詞不滿足的話,Kudu可以完全避免掃描其他列,從而避免不必要的I / O。
本篇博文能夠?qū)udu的讀寫(xiě)路徑進(jìn)行清晰簡(jiǎn)明的概述,并且使讀者理解Kudu如何能夠在不斷變化的數(shù)據(jù)上支持快速的分析訪問(wèn)模式。