













一文貫通python文件讀取
不論是數據分析還是機器學習,乃至于高大上的AI,數據源的獲取是所有過程的入口。 數據源的存在形式多為數據庫或者文件,如果把數據看做一種特殊格式的文件的話,即所有數據源都是文件。獲得數據,就是讀取文件的操作,文件有各種各樣的格式即數據的組織形式,如何方便快捷地獲取文件中的內容呢?
還是那句名言,life is short, just use python。
操作基礎
在python 中,文件的操作分為面向目錄和面向文件的,本質都是一樣的。
面向目錄的常見操作見下表:
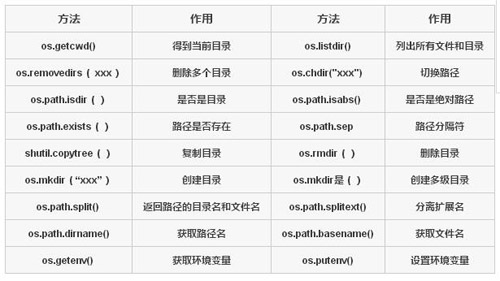
面向文件的常見操作見下表:
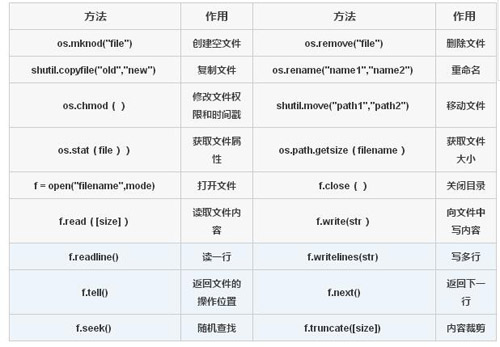
在這些基本操作中,遍歷目錄并列出所有文件或者所需的目標文件是一種常見的操作。另外,需要注意的是打開文件時的模式,a,w,r,組合時的a+,w+,r+, 還有針對這六種模式在讀取二進制文件時都要加上b。 在操作結束時,一定要顯式關閉文件, 當然 通過with 語句的隱式關閉也是可以的。
對于作為數據內容源的文件而言, 可以簡單的分為文本和非文本兩類,就是內容本身是文字的和非文字的,對混合形式的文件一般可以采用分而治之的方式。對于數據分析而言,這里側重于文件讀取及數據的采集上。
文本文件讀取
數據分析乃至文本分析都有涉及到文本文件的讀取。文本文件也可以粗略的分為兩類:純內容文本和帶格式約定的文本。純內容文本就是相對純粹的文本數據,例如新聞,博客文字內容,readme等等。帶格式約定的文本是為了增強內容的功能性或者實現特定的語義,例如xml,html,json文件等。
純內容文本文件
在讀取純內容文本的時候,就是一般的讀文件基礎操作,需要注意的是文本內容的字符集編碼。判斷文本文件屬于哪個字符集,老碼農還在用chardet,不知道現在有沒有更先進的手段了。示例代碼如下:
- import chardet
- f = open('/target_path/abel.txt',r)
- my_data = f.read()
- print chardet.detect(my_data)
chardet.detect 返回的是一個字典,包括編碼類型和一個概率值。然后,就可以根據自己的需要進行編碼轉換了。
鍵值對相關的配置文件
在應用中經常有.ini文件來用于配置信息,在python 中可以利用ConfigParser來處理。ConfigParser 模塊有RawConfigParser,ConfigParser 和SafeConfigParser 三種對象,一般采用ConfigParser即可。 一個應用的配置文件"myweb_config.ini"如下:
- [myweb]
- url = http://%(host)s:%(port)s/myweb
- host = 192.168.1.100
- port = 8888
那么,使用ConfigParser的示例代碼如下:
- import ConfigParser
- mysql_config = ConfigParser.ConfigParser()
- cf.read("myweb_config.ini")
- print cf.get("portal", "url")
讀取配置文件的一個常見使用情形是獲取數據庫的訪問信息,以便從數據庫中獲取數據。
Json,XML和HTML文件
JSON是一種輕量級的數據交換格式。Json 文件采用完全獨立于編程語言的文本格式來存儲和表示數據。簡潔和清晰的層次結構使得 JSON 成為理想的數據交換語言,是當前應用中主流的數據文件之一。 通過Python的json模塊,可以將字符串形式的json數據轉化為字典,也可以將Python中的字典數據轉化為字符串形式的json數據。讀取Json文件的示例代碼如下:
- import json
- f = open("test.json", encoding='utf-8')
- my_json = json.load(f)
然后就可以對my_json 以字典方式進行讀取了,需要主要的是設置Json文件解碼模式。
XML是一套定義語義標記的規則,將文檔分成許多部分并對這些部分加以標識。同時,也是定義了用于定義其他與特定領域有關的、語義的、結構化的標記語言的句法語言。在python 中解析 XML 文件有三種方法:SAX,DOM,和ElementTree。ElementTree就像一個輕量級的DOM,示例代碼如下:
- import xml.etree.ElementTree as ET
- my_xml_tree = ET.parse('/home/abel/face.xml')
- print my_xml_tree.getroot()
HTML 更是我們最常接觸文件,基于web的數據爬蟲,數據分析,數據挖掘等都會涉及到HTML文件的讀寫。在python中,用BS4 來對html 進行操作是非常方便的,同樣也可以對xml 文件進行類似的操作,尤其是從網絡中讀取html,示例代碼如下:
- import requests
- from bs4 import BeautifulSoup
- res = requests.get("http://a.b.c/c?d=e")
- soup = BeautifulSoup(res.text)
- print soup.find_all('a')
CSV文件
CSV文件就是一種由逗號隔開的文本文件,使用非常廣泛,尤其是excel 文件可以另存為CSV文件,使分析CSV文件中的數據更加方便。 在Python中可以之間使用csv模塊進行操作即可,示例代碼如下:
- import csv
- csv_reader = csv.reader(open('mydata.csv', encoding='utf-8'))
- for each_line in csv_reader:
- print each_line
常見的文本文件除了純文本,鍵值對文件,json,xml,html,csv以外,就是大量的日志文件了,也可以選擇的相關庫或者自行分析讀取, 進一步就可能進入到NLP的領域了。
媒體文件讀取
媒體文件中的數據內容一般不是文本,是經過編碼是數據,例如圖片,音頻,以及視頻文件,為了簡化可以暫不考慮其中的字幕情況。
圖片文件
圖片由各種各樣的格式即數據內容的編解碼方式,在python 中一般使用PIL 庫對圖片文件進行讀取或者進一步的處理,示例代碼如下:
- from PIL import Image
- im = Image.open('/home/abel/abc.jpg')
- w, h = im.size
- im.thumbnail((w/2, h/2))
- im.save('/home/abel/abc_thumbnail.jpg', 'jpeg')
這個一個獲取一個圖片文件縮略圖的小例子。 PIL是很強大的,提供了幾乎所有的圖像基本操作,例如改變圖像大小,旋轉圖像,圖像格式轉換,色場空間轉換,圖像增強,直方圖處理,插值和濾波等等。當然,其他的一些科學計算庫也提供了很多圖像處理的功能,例如大名鼎鼎的OpenCV, 具體可以參見《7行python代碼的人臉識別》一文。
音頻MP3
和圖片文件一樣, 音頻文件的編解碼格式同樣很多。以MP3為例,只要了解了MP3文件的編碼格式,就可以通過Python直接對MP3中的文件信息進行讀取了。如果不重復造輪子的話,python 對音頻的支持庫也有很多。就MP3而言,可以使用python 中的eye3D(http://http://eyed3.nicfit.net) 庫來讀取MP3 中的相關信息, 示例代碼如下:
- import eyed3
- f_mp3 = eyed3.load("/users/hecom/xiangwang.mp3")
- print f_mp3.tag.title
- print f_mp3.info.time_secs
技術演進日新月異,老碼農曾經使用過的PyMedia 好像很久沒人維護了,至于mp3 文件的播放,可以使用的庫同樣很多,例如mp3play,pyaudio以及pygame等。對于音頻文件的進一步處理一般就要涉及的語音識別和語音合成了。
視頻MP4
視頻可以粗略地看成音頻、圖片乃至文字的混合體了。在Python 中讀取并處理視頻文件,一般可以使用MoviePy庫(https://github.com/Zulko/moviepy)。MoviePy是可用于視頻編輯的基本操作(像剪切,合并,插入標題),視頻合成(又名非線性編輯),視頻處理,或者創建高級的效果。它可以讀取和寫入的最普通的視頻格式,包括GIF。 示例代碼如下:
- from moviepy.editor import *
- video = VideoFileClip("mybaby.mp4").subclip(50,60)
- txt_clip = ( TextClip("My Son 2002",fontsize=70,color='white')
- .set_position('center')
- .set_duration(10) )
- result = CompositeVideoClip([video, txt_clip])
- result.write_videofile("mybaby_edited.mp4",fps=25)
這個小例子是將一個MP4提取其中50秒至60秒之間的數據并增加上一點文本信息生成一個新的MP4文件。MoviePy中提供了很多視頻處理的方法和示例,并且能與PIL,OpenCV,scikit Image,matplotlib等混合使用。另外,關于視頻的攝取,python中也是有vediocapture庫的。
帶格式編碼的文檔讀取
我們常見的另一類文檔如PDF,word,excel等也是一種混合文檔,里面一般以文本為主,主要在顯示方式上作了規則限定,文檔中包含了關于顯示格式的大量信息。當然,這些文檔還可以嵌入媒體文件。粗淺地解釋一下,為了理解的方便,可以把這些帶格式編碼的文檔看作瀏覽器和html文本的結合體,這樣文件中的某些邏輯處理就可以想象成JavaScript的相關操作了。
PDF文件
PDF是一種非常好用的格式,它能夠解析并顯示與圖片結合在一起的文本,并且具備一般性的不可編輯。在Python 中一般可以通過pdfminer(http://www.unixuser.org/~euske/python/pdfminer/) 或者pypdf 來讀取pdf文件中的內容, 官網給出的示例代碼如下:
- from pdfminer.pdfparser import PDFParser
- from pdfminer.pdfdocument import PDFDocument
- from pdfminer.pdfpage import PDFPage
- from pdfminer.pdfpage import PDFTextExtractionNotAllowed
- from pdfminer.pdfinterp import PDFResourceManager
- from pdfminer.pdfinterp import PDFPageInterpreter
- from pdfminer.pdfdevice import PDFDevice
- # Open a PDF file.
- fp = open('mypdf.pdf', 'rb')
- # Create a PDF parser object associated with the file object.
- parser = PDFParser(fp)
- # Create a PDF document object that stores the document structure.
- # Supply the password for initialization.
- document = PDFDocument(parser, password)
- # Check if the document allows text extraction. If not, abort.
- if not document.is_extractable:
- raise PDFTextExtractionNotAllowed
- # Create a PDF resource manager object that stores shared resources.
- rsrcmgr = PDFResourceManager()
- # Create a PDF device object.
- device = PDFDevice(rsrcmgr)
- # Create a PDF interpreter object.
- interpreter = PDFPageInterpreter(rsrcmgr, device)
- # Process each page contained in the document.
- for page in PDFPage.create_pages(document):
- interpreter.process_page(page)
除此之外,還可以采用命令行———— pdf2txt 直接調用pdf文件進行文本轉換。
word 文件
word文檔幾乎是最常見的辦公文件了,但是.docx文件的結構比較復雜,一般分為三層:
- Docment對象表示整個文檔;
- Docment包含了Paragraph對象的列表,Paragraph對象用來表示文檔中的段落;
- 一個Paragraph對象包含Run對象的列表。
在python中 一般可以采用python-docx 庫對word文件進行讀寫,簡化起見,如果只關心word文件中的文本信息的話,示例代碼如下:
- import docx
- doc = docx.Document('/home/abel/test.docx')
- paras = doc.paragraphs
- text_in_doc =[]
- for each_p in paras:
- text_in_doc.append(each_p.text)
Python DocX目前是Python OpenXML的一部分,可以用它打開Word 2007及以后的文檔,而用它保存的文檔可以在Microsoft Office 2007/2010, Microsoft Mac Office 2008, Google Docs, OpenOffice以及Apple iWork 08中打開。
Excel 文件
python處理excel文件主要的第三方庫有xlrd、xlwt、xluntils和pyExcelerator等,還有人在這之上封裝了很多更方便實用的庫。這里使用樸實的xlrd(https://github.com/python-excel/xlrd/)來讀取excel文件,示例代碼如下:
- import xlrd
- myworkbook = xlrd.open_workbook('test.xls') # 打開xls文件
- table = myworkbook.sheet_by_name(u'Sheet1')
- nrows = table.nrows
- for i in range(nrows):
- print table.row_values(i)[:10]
這個小例子讀取了test.xls 文件,打印出來Sheet1中各行的前十列。xlrd 是有局限的,無法讀取excel中的一些對象,如:
- 圖表,圖片,宏以及其他的嵌入對象
- VBA,超鏈接,數據驗證
- 公式(結果除外),條件的格式化,注釋等等
好在,我們關注的是excel中的數據內容,以便進行數據分析,這些局限無傷大雅。
一句話小結
文件數據源的讀取是數據分析的入口,使用Python可以方便快捷地讀取各種文件格式中的內容,為進一步的數據分析或者數據清洗提供了簡潔方式。
【本文來自51CTO專欄作者“老曹”的原創文章,作者微信公眾號:喔家ArchiSelf,id:wrieless-com】






















