漫談四種神經網絡序列解碼模型以及示例代碼
以下為漫談,即瞎聊,利用通俗的語言來談談神經網絡模型中4種序列解碼模型,主要是從整體概念和思路上進行通俗解釋幫助理解。預警,以下可能為了偷懶就不貼公式了,一些細節也被略過了,感興趣的可以直接去閱讀原文[1][2][3]。
[1] Sequence to Sequence Learning with Neural Networks
[2] Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
[3] Neural Machine Translation by Jointly Learning to Align and Translate
利用神經網絡進行序列編碼的模型主要為RNN,目前比較火的一些變種模型有LSTM和GRU,只是cell單元不同而已。以下統統用RNN來代表。
編碼模型比較簡單,如下圖所示,輸入文本{X1-X6}經過循環迭代編碼,在每個時刻得到當前時刻的一個隱層狀態,最后序列結束后進行特征融合得到句子的表示。注意,一種比較常用的方式是將編碼模型最后一個時刻的隱層狀態做為整個序列的編碼表示,但是實際應用中這種效果并不太好,因而我們的圖例中直接采用了整個序列隱層編碼進行求和平均的方式得到序列的編碼向量。
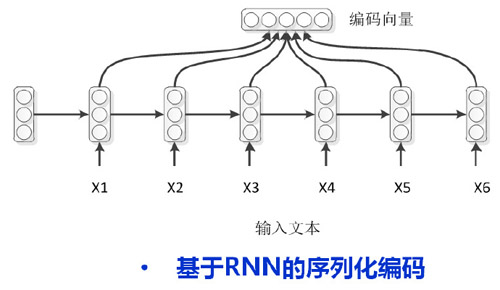
早期的一些任務主要是做一些主題分類、情感檢測等等分類任務,那么在編碼向量上面添加一個softmax就可以解決問題。但是對于機器翻譯和語音識別等問題則需要進行序列化解碼。
注意到,編碼時RNN每個時刻除了自己上一時刻的隱層狀態編碼外,還有當前時刻的輸入字符,而解碼時則沒有這種輸入。那么,一種比較直接的方式是把編碼端得到的編碼向量做為解碼模型的每時刻輸入特征。如下圖所示:
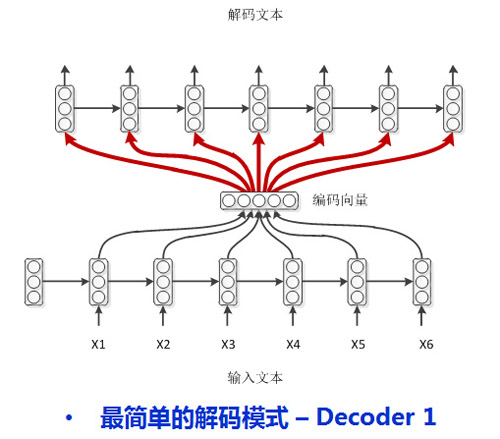
簡單直觀而且解碼模型和編碼模型并沒有任何區別,然而學者感覺該模型并不優雅,那么接下來我們就來介紹一些精巧點的吧。
我們用考試作弊來做為一個通俗的例子來解釋一下模型。
首先我們假設輸入文本是所學課本,編碼端則是對課本的理解所整理的課堂筆記。解碼端的隱層神經網絡則是我們的大腦,而每一時刻的輸出則是考試時要寫在卷子上的答案。在上面最簡單的解碼模型中,可以考慮成是考試時一邊寫答案一邊翻看課堂筆記。如果這是一般作弊學生的做法,學霸則不需要翻書,他們有一個強大的大腦神經網絡,可以記住自己的課堂筆記。解碼時只需要回顧一下自己前面寫過什么,然后依次認真的把答案寫在答卷上,就是下面這種模型了[1]:
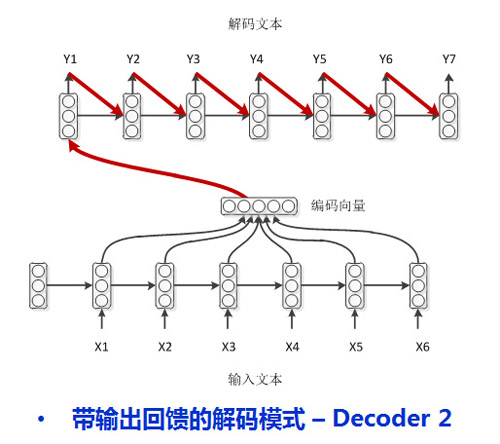
還有很多學弱,他們不只需要作弊,而且翻看筆記的時候還需要回顧自己上一時刻寫在答卷上的答案(學弱嘛,簡直弱到連自己上一時刻寫在答卷上的文字都記不住了),就是下面的答題模式了[2]:
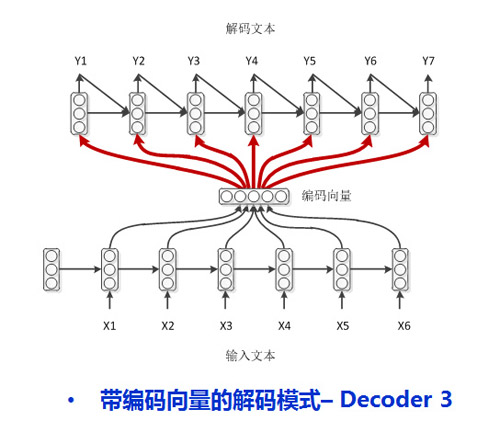
然而學渣渣也是存在的,他們不只需要作弊,不只需要回顧自己上一時刻卸載答卷上的答案,還需要老師在課本上畫出重點才能整理出自己的課題筆記(這就是一種注意力機制Attention,記筆記的時候一定要根據考題畫出重點啊!),真的很照顧渣渣了,他們的答題模式如下[3]:
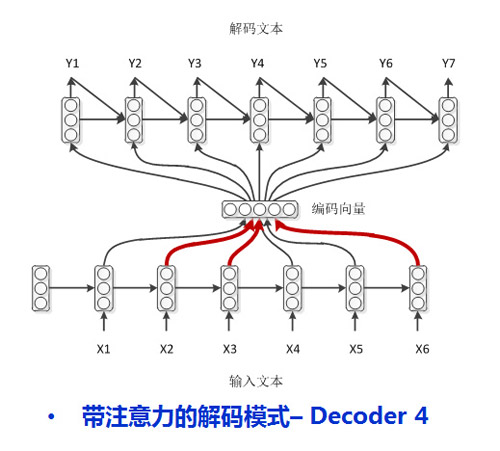
可見,除了學霸以外,其他人都作弊了,在答題的時候翻看課堂筆記(很多文獻中叫這種解碼模型結構為peek(偷看),是不是很像在作弊?),而且學渣渣還去找過老師給畫過重點,有了清楚的重點之后就不用翻書偷看了,瞄一眼就可以了,文獻中叫glimpse(一瞥),是不是很像?
如果我們將他們的大腦網絡設定為同樣結構的話(將他們的IQ強制保持一致),肯定是作弊的同學得分最高了,學霸模式好吃虧啊。我們來簡單做一個模型測試。
測試數據:
輸入序列文本 = [‘1 2 3 4 5’
, ‘6 7 8 9 10′
, ’11 12 13 14 15′
, ’16 17 18 19 20′
, ’21 22 23 24 25’]
目標序列文本 = [‘one two three four five’
, ‘six seven eight nine ten’
, ‘eleven twelve thirteen fourteen fifteen’
, ‘sixteen seventeen eighteen nineteen twenty’
, ‘twenty_one twenty_two twenty_three twenty_four twenty_five’]
設定一些參數如下:
–
(‘Vocab size:’, 51, ‘unique words’)
(‘Input max length:’, 5, ‘words’)
(‘Target max length:’, 5, ‘words’)
(‘Dimension of hidden vectors:’, 20)
(‘Number of training stories:’, 5)
(‘Number of test stories:’, 5)
–
觀察訓練過程:
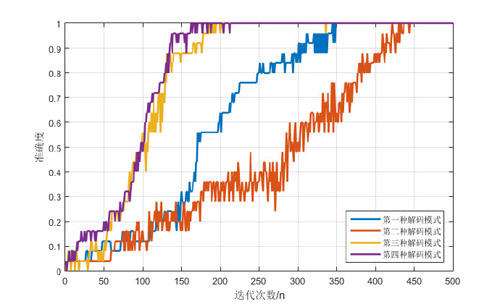
其中,第一種解碼模型為 普通作弊,第二種解碼模型為 學霸模式,第三種解碼模型為 學弱作弊,第四種解碼模型為 學渣作弊。
可以看到在IQ值(解碼模型的神經網絡結構)相同的情況下,學渣作弊模式答題(訓練收斂速度)更快,而學霸模式答題最慢。
文章[1]中已經提到過,想通過學霸模式達到一個好的性能需要模型隱層有4000個節點(學霸的IQ果然是高的,有一顆強大的大腦網絡)。
可以想想,在課本內容很多很多時,學霸也會累的,而且學弱們你們確定課上能聽懂嗎?學渣就會笑啦,因而老師給他們畫重點了!!!!
本博文中測試的示例代碼見【Github地址】:
- # -*- encoding:utf-8 -*-
- “”"
- 測試Encoder-Decoder 2016/03/22
- “”"
- from keras.models import Sequential
- from keras.layers.recurrent import LSTM
- from keras.layers.embeddings import Embedding
- from keras.layers.core import RepeatVector, TimeDistributedDense, Activation
- from seq2seq.layers.decoders import LSTMDecoder, LSTMDecoder2, AttentionDecoder
- import time
- import numpy as np
- import re
- __author__ = ’http://jacoxu.com’
- def pad_sequences(sequences, maxlen=None, dtype=’int32′,
- padding=’pre’, truncating=’pre’, value=0.):
- ”’Pads each sequence to the same length:
- the length of the longest sequence.
- If maxlen is provided, any sequence longer
- than maxlen is truncated to maxlen.
- Truncation happens off either the beginning (default) or
- the end of the sequence.
- Supports post-padding and pre-padding (default).
- # Arguments
- sequences: list of lists where each element is a sequence
- maxlen: int, maximum length
- dtype: type to cast the resulting sequence.
- padding: ’pre’ or ’post’, pad either before or after each sequence.
- truncating: ’pre’ or ’post’, remove values from sequences larger than
- maxlen either in the beginning or in the end of the sequence
- value: float, value to pad the sequences to the desired value.
- # Returns
- x: numpy array with dimensions (number_of_sequences, maxlen)
- ”’
- lengths = [len(s) for s in sequences]
- nb_samples = len(sequences)
- if maxlen is None:
- maxlen = np.max(lengths)
- # take the sample shape from the first non empty sequence
- # checking for consistency in the main loop below.
- sample_shape = tuple()
- for s in sequences:
- if len(s) > 0:
- sample_shape = np.asarray(s).shape[1:]
- break
- x = (np.ones((nb_samples, maxlen) sample_shape) * value).astype(dtype)
- for idx, s in enumerate(sequences):
- if len(s) == 0:
- continue # empty list was found
- if truncating == ’pre’:
- trunc = s[-maxlen:]
- elif truncating == ’post’:
- trunc = s[:maxlen]
- else:
- raise ValueError(‘Truncating type ”%s” not understood’ % truncating)
- # check `trunc` has expected shape
- trunc = np.asarray(trunc, dtype=dtype)
- if trunc.shape[1:] != sample_shape:
- raise ValueError(‘Shape of sample %s of sequence at position %s is different from expected shape %s’ %
- (trunc.shape[1:], idx, sample_shape))
- if padding == ’post’:
- x[idx, :len(trunc)] = trunc
- elif padding == ’pre’:
- x[idx, -len(trunc):] = trunc
- else:
- raise ValueError(‘Padding type ”%s” not understood’ % padding)
- return x
- def vectorize_stories(input_list, tar_list, word_idx, input_maxlen, tar_maxlen, vocab_size):
- x_set = []
- Y = np.zeros((len(tar_list), tar_maxlen, vocab_size), dtype=np.bool)
- for _sent in input_list:
- x = [word_idx[w] for w in _sent]
- x_set.append(x)
- for s_index, tar_tmp in enumerate(tar_list):
- for t_index, token in enumerate(tar_tmp):
- Y[s_index, t_index, word_idx[token]] = 1
- return pad_sequences(x_set, maxlen=input_maxlen), Y
- def tokenize(sent):
- ”’Return the tokens of a sentence including punctuation.
- >>> tokenize(‘Bob dropped the apple. Where is the apple?’)
- ['Bob', 'dropped', 'the', 'apple', '.', 'Where', 'is', 'the', 'apple', '?']
- ”’
- return [x.strip() for x in re.split('(\W )?', sent) if x.strip()]
- def main():
- input_text = ['1 2 3 4 5'
- , '6 7 8 9 10'
- , '11 12 13 14 15'
- , '16 17 18 19 20'
- , '21 22 23 24 25']
- tar_text = ['one two three four five'
- , 'six seven eight nine ten'
- , 'eleven twelve thirteen fourteen fifteen'
- , 'sixteen seventeen eighteen nineteen twenty'
- , 'twenty_one twenty_two twenty_three twenty_four twenty_five']
- input_list = []
- tar_list = []
- for tmp_input in input_text:
- input_list.append(tokenize(tmp_input))
- for tmp_tar in tar_text:
- tar_list.append(tokenize(tmp_tar))
- vocab = sorted(reduce(lambda x, y: x | y, (set(tmp_list) for tmp_list in input_list tar_list)))
- # Reserve 0 for masking via pad_sequences
- vocab_size = len(vocab) 1 # keras進行embedding的時候必須進行len(vocab) 1
- input_maxlen = max(map(len, (x for x in input_list)))
- tar_maxlen = max(map(len, (x for x in tar_list)))
- output_dim = vocab_size
- hidden_dim = 20
- print(‘-’)
- print(‘Vocab size:’, vocab_size, ’unique words’)
- print(‘Input max length:’, input_maxlen, ’words’)
- print(‘Target max length:’, tar_maxlen, ’words’)
- print(‘Dimension of hidden vectors:’, hidden_dim)
- print(‘Number of training stories:’, len(input_list))
- print(‘Number of test stories:’, len(input_list))
- print(‘-’)
- print(‘Vectorizing the word sequences…’)
- word_to_idx = dict((c, i 1) for i, c in enumerate(vocab)) # 編碼時需要將字符映射成數字index
- idx_to_word = dict((i 1, c) for i, c in enumerate(vocab)) # 解碼時需要將數字index映射成字符
- inputs_train, tars_train = vectorize_stories(input_list, tar_list, word_to_idx, input_maxlen, tar_maxlen, vocab_size)
- decoder_mode = 1 # 0 最簡單模式,1 [1]向后模式,2 [2] Peek模式,3 [3]Attention模式
- if decoder_mode == 3:
- encoder_top_layer = LSTM(hidden_dim, return_sequences=True)
- else:
- encoder_top_layer = LSTM(hidden_dim)
- if decoder_mode == 0:
- decoder_top_layer = LSTM(hidden_dim, return_sequences=True)
- decoder_top_layer.get_weights()
- elif decoder_mode == 1:
- decoder_top_layer = LSTMDecoder(hidden_dim=hidden_dim, output_dim=hidden_dim
- , output_length=tar_maxlen, state_input=False, return_sequences=True)
- elif decoder_mode == 2:
- decoder_top_layer = LSTMDecoder2(hidden_dim=hidden_dim, output_dim=hidden_dim
- , output_length=tar_maxlen, state_input=False, return_sequences=True)
- elif decoder_mode == 3:
- decoder_top_layer = AttentionDecoder(hidden_dim=hidden_dim, output_dim=hidden_dim
- , output_length=tar_maxlen, state_input=False, return_sequences=True)
- en_de_model = Sequential()
- en_de_model.add(Embedding(input_dim=vocab_size,
- output_dim=hidden_dim,
- input_length=input_maxlen))
- en_de_model.add(encoder_top_layer)
- if decoder_mode == 0:
- en_de_model.add(RepeatVector(tar_maxlen))
- en_de_model.add(decoder_top_layer)
- en_de_model.add(TimeDistributedDense(output_dim))
- en_de_model.add(Activation(‘softmax’))
- print(‘Compiling…’)
- time_start = time.time()
- en_de_model.compile(loss=’categorical_crossentropy’, optimizer=’rmsprop’)
- time_end = time.time()
- print(‘Compiled, cost time:%fsecond!’ % (time_end - time_start))
- for iter_num in range(5000):
- en_de_model.fit(inputs_train, tars_train, batch_size=3, nb_epoch=1, show_accuracy=True)
- out_predicts = en_de_model.predict(inputs_train)
- for i_idx, out_predict in enumerate(out_predicts):
- predict_sequence = []
- for predict_vector in out_predict:
- next_index = np.argmax(predict_vector)
- next_token = idx_to_word[next_index]
- predict_sequence.append(next_token)
- print(‘Target output:’, tar_text[i_idx])
- print(‘Predict output:’, predict_sequence)
- print(‘Current iter_num is:%d’ % iter_num)
- if __name__ == ’__main__‘:
- main()