













一個開源機器學習框架新手入門,Scikit-learn的那些事兒

對Python語言有所了解的科研人員可能都知道SciPy——一個開源的基于Python的科學計算工具包。基于SciPy,目前開發者們針對不同的應用領域已經發展出了為數眾多的分支版本,它們被統一稱為Scikits,即SciPy工具包的意思。而在這些分支版本中,最有名,也是專門面向機器學習的一個就是Scikit-learn。
Scikit-learn項目最早由數據科學家 D**id Cournapeau 在 2007 年發起,需要NumPy和SciPy等其他包的支持,是Python語言中專門針對機器學習應用而發展起來的一款開源框架。
和其他眾多的開源項目一樣,Scikit-learn目前主要由社區成員自發進行維護。可能是由于維護成本的限制,Scikit-learn相比其他項目要顯得更為保守。這主要體現在兩個方面:一是Scikit-learn從來不做除機器學習領域之外的其他擴展,二是Scikit-learn從來不采用未經廣泛驗證的算法。
本文將簡單介紹Scikit-learn框架的六大功能,安裝和運行Scikit-learn的大概步驟,同時為后續各更深入地學習Scikit-learn提供參考。原文來自infoworld網站的特約撰稿人Martin Heller,他曾在1986-2010年間做過長達20多年的數據庫、通用軟件和網頁開發,具有豐富的開發經驗。
Scikit-learn的六大功能
Scikit-learn的基本功能主要被分為六大部分:分類,回歸,聚類,數據降維,模型選擇和數據預處理。
分類是指識別給定對象的所屬類別,屬于監督學習的范疇,最常見的應用場景包括垃圾郵件檢測和圖像識別等。目前Scikit-learn已經實現的算法包括:支持向量機(SVM),最近鄰,邏輯回歸,隨機森林,決策樹以及多層感知器(MLP)神經網絡等等。
需要指出的是,由于Scikit-learn本身不支持深度學習,也不支持GPU加速,因此這里對于MLP的實現并不適合于處理大規模問題。有相關需求的讀者可以查看同樣對Python有良好支持的Keras和Theano等框架。
回歸是指預測與給定對象相關聯的連續值屬性,最常見的應用場景包括預測藥物反應和預測股票價格等。目前Scikit-learn已經實現的算法包括:支持向量回歸(SVR),脊回歸,Lasso回歸,彈性網絡(Elastic Net),最小角回歸(LARS ),貝葉斯回歸,以及各種不同的魯棒回歸算法等。可以看到,這里實現的回歸算法幾乎涵蓋了所有開發者的需求范圍,而且更重要的是,Scikit-learn還針對每種算法都提供了簡單明了的用例參考。
聚類是指自動識別具有相似屬性的給定對象,并將其分組為集合,屬于無監督學習的范疇,最常見的應用場景包括顧客細分和試驗結果分組。目前Scikit-learn已經實現的算法包括:K-均值聚類,譜聚類,均值偏移,分層聚類,DBSCAN聚類等。
數據降維是指使用主成分分析(PCA)、非負矩陣分解(NMF)或特征選擇等降維技術來減少要考慮的隨機變量的個數,其主要應用場景包括可視化處理和效率提升。
模型選擇是指對于給定參數和模型的比較、驗證和選擇,其主要目的是通過參數調整來提升精度。目前Scikit-learn實現的模塊包括:格點搜索,交叉驗證和各種針對預測誤差評估的度量函數。
數據預處理是指數據的特征提取和歸一化,是機器學習過程中的***個也是最重要的一個環節。這里歸一化是指將輸入數據轉換為具有零均值和單位權方差的新變量,但因為大多數時候都做不到精確等于零,因此會設置一個可接受的范圍,一般都要求落在0-1之間。而特征提取是指將文本或圖像數據轉換為可用于機器學習的數字變量。
需要特別注意的是,這里的特征提取與上文在數據降維中提到的特征選擇非常不同。特征選擇是指通過去除不變、協變或其他統計上不重要的特征量來改進機器學習的一種方法。
總結來說,Scikit-learn實現了一整套用于數據降維,模型選擇,特征提取和歸一化的完整算法/模塊,雖然缺少按步驟操作的參考教程,但Scikit-learn針對每個算法和模塊都提供了豐富的參考樣例和詳細的說明文檔。
安裝和運行Scikit-learn
如前所述,Scikit-learn需要NumPy和SciPy等其他包的支持,因此在安裝Scikit-learn之前需要提前安裝一些支持包,具體列表和教程可以查看Scikit-learn的官方文檔: http://scikit-learn.org/stable/install.html ,以下僅列出Python、NumPy和SciPy等三個必備包的安裝說明。
Python:https://www.python.org/about/gettingstarted/
NumPy:http://www.numpy.org/
SciPy:http://www.scipy.org/install.html
假定已經完整安裝了所有支持包,那么利用安裝Scikit-learn只需要簡單的一條簡單的pip命令(也可以用conda命令,詳見官方文檔):
- $ sudo pip install -U scikit-learn
這里加上sudo是為了避免安裝過程中出現一些權限問題,如果用戶已經確保了管理員權限也可以省略。
當然,開發者也可以選擇自己到GitHub開源平臺上下載Scikit-learn的源代碼,解壓后在根目錄鍵入make自行編譯和連接可執行文件,效果是一樣的。另外,為了確保測試方便,高級用戶還可以選擇安裝針對Python的測試框架nose,安裝方法詳見其官方說明: http://nose.readthedocs.io/en/latest/ 。
通過Jupyter Notebook工具運行Scikit-learn樣例的過程也很簡單,用戶只需要在官方給出的樣例庫: http://scikit-learn.org/stable/auto_examples/index.html#general-examples 選擇一個樣例,然后在頁面中下載其Python源碼和IPython notebook文件,借著通過Jupyter Notebook工具運行就可以了。假如選擇了交叉驗證預測的樣例,那么其運行情況的截圖如下所示。
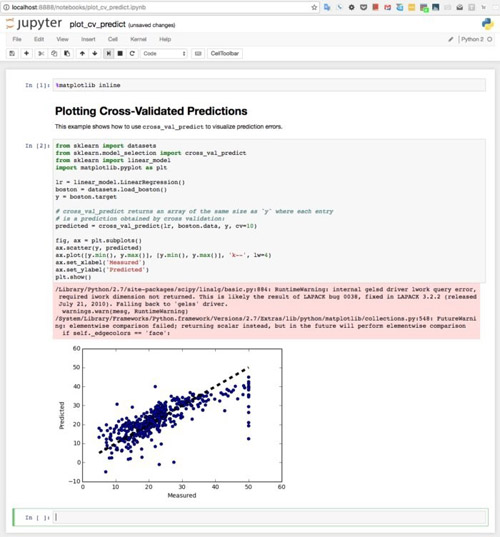
原作者在這里表示,Scikit-learn是他測試過的最簡單易用的機器學習框架。他表示,Scikit-learn樣例的運行結果和文檔描述一模一樣,API接口的設計合理且一致性高,而且幾乎不存在“阻抗不匹配”的數據結構,使用這種功能完善且幾乎沒有Bug的開源框架進行機器學習研究,無疑是一件值得高興的事。
更深入地學習Scikit-learn
如前所述,Scikit-learn針對每個算法和模塊都提供了豐富的參考樣例和詳細的說明文檔,據官方的統計大約有200多個。而且為了清晰明白,絕大多數樣例都至少給出了一張由Matplotlib繪制的數據圖表。這些都是官方提供的學習Scikit-learn框架最直接有效的學習材料。
針對科學數據處理的應用場景,官方還給出了一個更為詳細和全面的參考教程:A tutorial on statistical-learning for scientific data processing,其中包括統計學習、監督學習、模型選擇和無監督學習等若干部分,內容覆蓋全面,講解細致,并且使用了真實的數據、代碼和圖表。
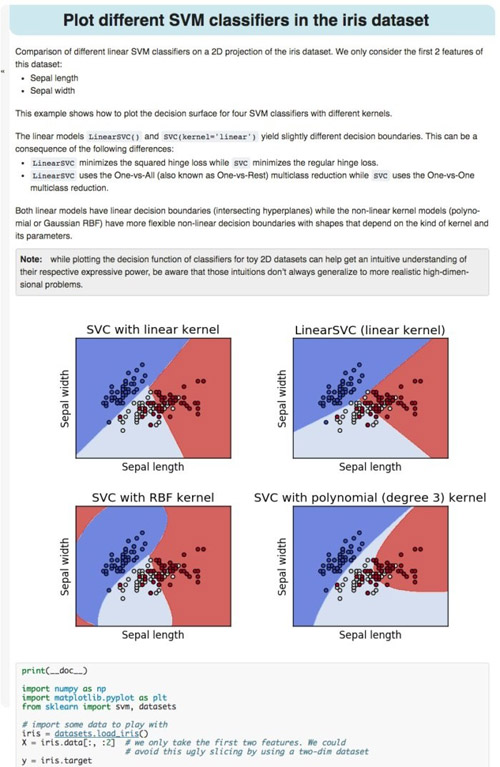
另外,教程中還調用了與文本相關的樣例,例如下圖所示的四個不同SVM分類器的比較。
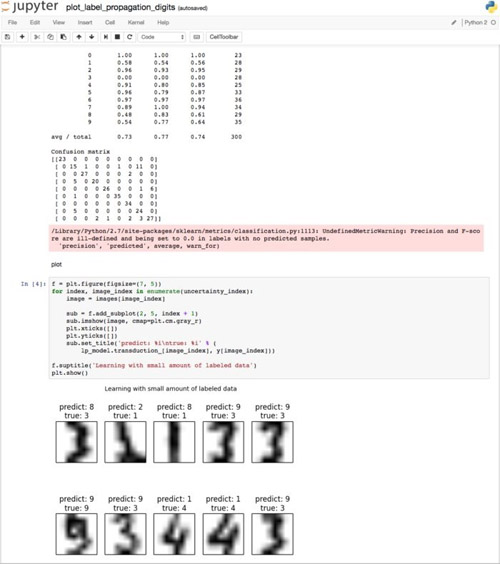
這里需要指出的是,雖然運行Scikit-learn官方給出的樣例后通常都能得到一致的結果,但大多數情況下系統都會拋出警告信息。作者認為拋出警告信息的原因來自兩個方面:一是蘋果vecLib框架本身對Scikit-learn支持不好(作者用的是MacOS),二是樣例中使用的Python版本可能是早期的版本,而實際運行中是***的版本。例如下圖中是使用Python 2.7.10版本拋出的警告信息,而Scikit-learn官方頁面上并沒有出現。
總體上來說,作為專門面向機器學習的Python開源框架,Scikit-learn可以在一定范圍內為開發者提供非常好的幫助。它內部實現了各種各樣成熟的算法,容易安裝和使用,樣例豐富,而且教程和文檔也非常詳細。
另一方面,Scikit-learn也有缺點。例如它不支持深度學習和強化學習,這在今天已經是應用非常廣泛的技術,例如準確的圖像分類和可靠的實時語音識別和語義理解等。此外,它也不支持圖模型和序列預測,不支持Python之外的語言,不支持PyPy,也不支持GPU加速。
看到這里可能會有人擔心Scikit-learn的性能表現,這里需要指出的是:如果不考慮多層神經網絡的相關應用,Scikit-learn的性能表現是非常不錯的。究其原因,一方面是因為其內部算法的實現十分高效,另一方面或許可以歸功于Cython編譯器:通過Cython在Scikit-learn框架內部生成C語言代碼的運行方式,Scikit-learn消除了大部分的性能瓶頸。
應該明確的一點是:雖然概括地說Scikit-learn并不適合深度學習問題,但對于某些特殊場景而言,使用Scikit-learn仍然是明智的選擇。例如要創建連接不同對象的預測函數時,或者在未標記的數據集中為了訓練模型對不同的對象進行分類時,面對這些場景Scikit-learn只通過普通的舊機器學習模型就能很好地解決,而并不需要建立數十層的復雜神經網絡。
就好像喜歡Scala語言的人會選擇Spark ML,喜歡繪制圖表和偶爾編寫少量Python/R語言代碼的人會選擇微軟Cortana和Azure一樣,對于那些Python語言的死忠粉而言,Scikit-learn可能是各種機器學習庫中的***選擇。















