Spark名詞解釋及關(guān)系
隨著對spark的業(yè)務(wù)更深入,對spark的了解也越多,然而目前還處于知道的越多,不知道的更多階段,當(dāng)然這也是成長最快的階段。這篇文章用作總結(jié)最近收集及理解的spark相關(guān)概念及其關(guān)系。
名詞
driver
driver物理層面是指輸入提交spark命令的啟動(dòng)程序,邏輯層面是負(fù)責(zé)調(diào)度spark運(yùn)行流程包括向master申請資源,拆解任務(wù),代碼層面就是sparkcontext。
worker
worker指可以運(yùn)行的物理節(jié)點(diǎn)。
executor
executor指執(zhí)行spark任務(wù)的處理程序,對java而言就是擁有一個(gè)jvm的進(jìn)程。一個(gè)worker節(jié)點(diǎn)可以運(yùn)行多個(gè)executor,只要有足夠的資源。
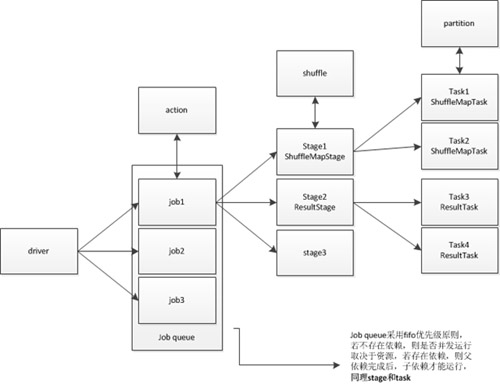
job
job是指一次action,rdd(rdd在這里就不解釋了)操作分成兩大類型,一類是transform,一類是action,當(dāng)涉及到action的時(shí)候,spark就會(huì)把上次action之后到本次action的所有rdd操作用一個(gè)job完成。
stage
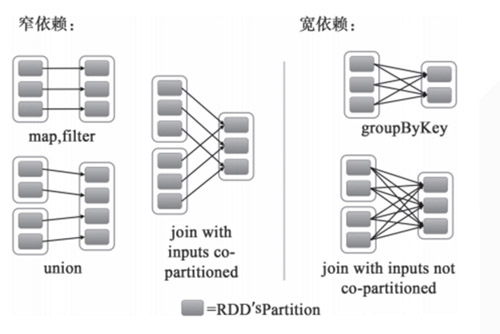
stage是指一次shuffle,rdd在操作的時(shí)候分為寬依賴(shuffle dependency)和窄依賴(narraw dependency),如下圖所示。而寬依賴就是指shuffle。
應(yīng)某人要求再解釋一下什么是窄依賴,就是父rdd的每個(gè)分區(qū)都只作用在一個(gè)子rdd的分區(qū)中,原話是這么說的 each partition of the parent RDD is used by at most one partition of the child RDD。
task
task是spark的最小執(zhí)行單位,一般而言執(zhí)行一個(gè)partition的操作就是一個(gè)task,關(guān)于partition的概念,這里稍微解釋一下。
spark的默認(rèn)分區(qū)數(shù)是2,并且最小分區(qū)也是2,改變分區(qū)數(shù)的方式有很多,大概有三個(gè)階段
1.啟動(dòng)階段,通過 spark.default.parallelism 來初始化默認(rèn)分區(qū)數(shù)
2.生成rdd階段,可通過參數(shù)配置
3.rdd操作階段,默認(rèn)繼承父rdd的partition數(shù),最終結(jié)果受shuffle操作和非shuffle操作的影響,不同操作的結(jié)果partition數(shù)不同
名詞關(guān)系
物理關(guān)系
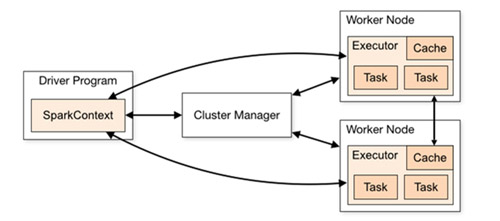
官網(wǎng)給出的spark運(yùn)行架構(gòu)圖
邏輯關(guān)系
下圖是總結(jié)的邏輯關(guān)系圖,如果有不對之處,還望提醒。