百度新論文提出Gram-CTC:單系統(tǒng)語音轉(zhuǎn)錄達到最高水平
近日,百度硅谷 AI 實驗室劉海容、李先剛等人發(fā)表論文提出了一種新的語音識別模型 Gram-CTC,將語音識別的速度和準確率大大提高。據(jù)研究人員介紹,這一新方法可以顯著減少模型訓練與推理時間。在相同任務中,新模型的表現(xiàn)在單一模型對比中超過了微軟等公司的研究。點擊閱讀原文下載此論文。
在百度的研究發(fā)表之前,微軟曾在 2016 年 10 月宣布他們的多系統(tǒng)方法在 2000 小時的口語數(shù)據(jù)庫 switchboard 上測得 5.9% 的誤差率。后者被認為是對多系統(tǒng)方法潛力的探索,而百度的此次提出的單系統(tǒng)方法則更易于實用化。
CTC 端到端學習使用一個算法將輸入和輸出聯(lián)系起來,通常采用深層神經(jīng)網(wǎng)絡。這種方式推崇更少的人工特征設計,更少的中間單元。端到端學習的系統(tǒng)包括:基于 CTC 的語音識別,基于注意機制的機器翻譯,目前業(yè)界的很多產(chǎn)品中都能找到 CTC 的身影。
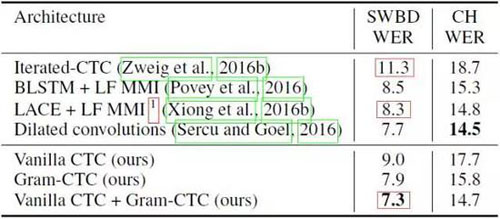
在 Fisher-Switchboard 基準測試上,百度的研究者使用域內(nèi)數(shù)據(jù)和此前已發(fā)表過的結(jié)果進行了比較,表中只列出了單一模型的結(jié)果。
在多種語言的語音識別中,Deep Speech 利用 CTC 損失呈現(xiàn)出一種端到端的神經(jīng)架構(gòu)。百度展示的 Gram CTC 能夠擴展 CTC 損失函數(shù),讓它自動發(fā)現(xiàn)并預測字段,而不是字符。
使用 Gram CTC 的模型可以用單一模型在 Fisher-Swbd 基準上實現(xiàn)超過以往任何其他模型的表現(xiàn),這說明使用 Gram-CTC 端到端的學習優(yōu)于基于上下文和相關(guān)音素的系統(tǒng),使用相同的訓練數(shù)據(jù)也能讓訓練速度加快兩倍。
針對同一段音頻,思考下文中可能出現(xiàn)的轉(zhuǎn)錄,它們對于語音轉(zhuǎn)錄來說都是可行的。
- recognize speech using common sense
- wreck a nice beach you sing calm incense
CTC 一次只能預測一個字符,假設輸入的對象之間相互獨立。為了讓兩種轉(zhuǎn)錄相似,CTC 必須要選擇兩個字符來補全空白,如下圖。

只使用 Option 2 的候選填補空白,我們即可達成***個目標,即「recognize speech …」;使用 Option 1 中的候選,我們會得到「wreck a nice beach …」。另外,從 Option 1 和 2 中共同選擇我們會得到很多種無意義的語句。
字段是介于字符和單詞之間的單元,如「ing」,「euax」,「sch」等(包含但不限于詞綴),雖然相同的字段可能會因為不同單詞或上下文情況出現(xiàn)不同的讀音,但字段在英語中通常傾向于同一個發(fā)音。在我們的例子中,我們也可以使用字段進行預測:

正如上圖所示,這種方法可以大量減少無意義的預測組合,此外,預測詞綴還具有以下優(yōu)點:
- 更易建模,因為字段比單個字母相對發(fā)音更進一步。
- 因為字段相對于字母反映了更長一段聲音,這種方法可以大大減少算法預測的步數(shù)。我們的模型減少了一半的時間步,訓練和推理速度大大加快。在同樣的硬件環(huán)境下,訓練 2000 小時數(shù)據(jù)集的時間從 9 小時縮短至 5 小時。
- 該模型可以學會識別相同發(fā)音的常見拼寫。在上面的例子中,「alm」和「omm」有非常接近的發(fā)音。在 CTC 中,這種識別很難;但在 Gram-CTC 中容易很多。
論文:Gram-CTC:用于序列標注的自動單元選擇和目標分解(Gram-CTC: Automatic Unit Selection and Target Decomposition for Sequence Labelling)

大多數(shù)已有的序列標注模型(sequence labelling model)都依賴一種目標序列到基本單元序列的固定分解。而這些方法都有兩個主要的缺點:1)基本單元的集合是固定的,比如語音識別中的單詞、字符與音素集合。2)目標序列的分解是固定的。這些缺點通常會導致建模序列時的次優(yōu)表現(xiàn)。在本論文中,我們拓展了流行的 CTC 損失標準來減緩這些限制,并提出了一種名為 Gram-CTC 的新型損失函數(shù)。在保留 CTC 的優(yōu)勢的同時,Gram-CTC 能自動地學習基礎(chǔ)單元(gram)的***集合,也能自動學習分解目標序列的最合適的方式。不像 CTC,Gram-CTC 使得該模型能在每個時間步驟上輸出字符的變量值,使得模型能捕捉到更長期的依存關(guān)系(dependency),并提升計算效率。我們證明此次提出的 Gram-CTC 在多種數(shù)據(jù)規(guī)模的大型詞匯語音識別任務上,既提升了 CTC 的表現(xiàn)又改進了 CTC 的效率。而且我們使用 Gram-CTC 也在標準的語音基準上得到了超越當前***的結(jié)果。