深度學(xué)習(xí)在自然語言處理中的應(yīng)用
習(xí)在自然語言處理中的應(yīng)用")
自然語言處理是研究和實現(xiàn)人與計算機之間用自然語言進行有效通信的各種理論和方法。本文主要介紹深度學(xué)習(xí)在自然語言處理中的應(yīng)用。
自然語言處理簡介
自然語言處理是研究和實現(xiàn)人與計算機之間用自然語言進行有效通信的各種理論和方法。具體的任務(wù)包括:
- 問答系統(tǒng)(如Siri、Alexa和Cortana的功能)
- 情感分析(判斷某個句子表達的是正面還是負面情緒)
- 圖像-文字映射(看圖寫話)
- 機器翻譯(語言之間相互翻譯)
- 語音識別
- 句子成分分析
- 命名實體識別
傳統(tǒng)的NLP方法需要借助大量語言學(xué)的領(lǐng)域知識。理解音素和詞素等術(shù)語是基本功,有專門的語言培訓(xùn)課程。我們先來看看傳統(tǒng)的NLP方法是如何理解下面這個詞語:
![]()
假設(shè)我們的目標(biāo)是從該詞提取出一些信息(情感偏向、詞意等等)。根據(jù)語言學(xué)知識,該詞可以分割為下面三部分:

我們知道前綴”un”表示相反或是反面意思,后綴”ed”表明了詞的時態(tài)(過去式)。再通過識別詞干”interest”的意思,我們就很容易推導(dǎo)出這個單詞的含義和情感偏向了。似乎很簡單對吧?但是,當(dāng)真正去梳理英語里的所有前綴和后綴時,你會發(fā)現(xiàn)所有前綴和后綴組合很多很多,只有非常資深的語言學(xué)家才能理解它們的含義。
深度學(xué)習(xí)的介入
深度學(xué)習(xí)本質(zhì)上還是一種表示學(xué)習(xí)的方法。例如,CNN模型就是用一系列濾波器的組合來將對象劃分到不同類別。因此,作者認為我們也可以借用同樣的方法來表示單詞。
本文概述
作者按照構(gòu)建深度神經(jīng)網(wǎng)絡(luò)模型的基本順序來撰寫本文,然后結(jié)合近期的研究論文來討論一些實際應(yīng)用。也許,部分讀者在讀完全文之后還存在為啥要用RNN模型,或者為啥LSTM網(wǎng)絡(luò)會有效等等問題。但是,作者的初衷是希望大家對深度學(xué)習(xí)在自然語言處理領(lǐng)域的應(yīng)用能有一個感性的認識。
詞向量
既然深度學(xué)習(xí)方法喜歡用數(shù)學(xué)符號,那我們就把每個單詞表示為一個d維的向量。假設(shè) d=6。
![]()
該用什么數(shù)值來表示這個向量呢?我們希望這個向量能夠表示詞語的含義或者語義。一種方法是創(chuàng)建共現(xiàn)矩陣。假設(shè)現(xiàn)在有一句話:
![]()
我們希望將句子中的每個單詞都表示為一個向量:

共現(xiàn)矩陣的每個元素表示一個詞與另一個詞在整篇文檔中相鄰出現(xiàn)的次數(shù)。具體來說如下圖所示:
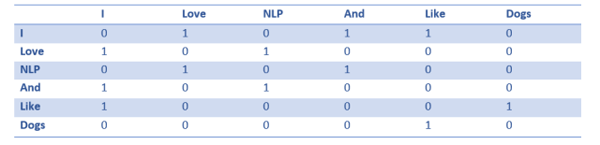
我們可以將共現(xiàn)矩陣的每一行當(dāng)做詞向量的初始值:

讀者們請注意,僅僅觀察這個簡單的矩陣,我們就能夠獲取很多有用的信息。例如,“love”和“like”兩個單詞與名詞性的單詞共現(xiàn)次數(shù)都是1(NLP和dogs),而且它們都與單詞“I”共現(xiàn)一次。這就意味著這兩個單詞很有可能屬于動詞。若我們手中的數(shù)據(jù)集足夠大,大家可以想象“like”與“love”的相似度會越來越高,同理其它近義詞的詞向量也會越來越相似,因為它們總是在相近的上下文中出現(xiàn)。
盡管我們找到了一個好的入手點,但是需要注意到這種向量表示方式的維度會隨著語料集的增長而呈線性增長。假如我們有一百萬個單詞(在NLP問題中并不算太多),就會得到一個 1000,000 x 1000,000 的矩陣,而且這個矩陣非常的稀疏。從存儲效率來說,這顯然不是一種好的表示方法。目前已經(jīng)有許多不錯的詞向量表示方法了,其中最著名的就是word2vec。
Word2Vec
詞向量方法的基本思想就是讓向量盡可能完整地表示該詞所包含的信息,同時讓向量維度保持在一個可控的范圍之內(nèi)(合適的維度是25~1000維之間)。
Word2vec的思想是預(yù)測某個中心詞附近其它詞語出現(xiàn)的概率。還是以之前的句子“I love NLP and I like dogs.”為例。我們首先觀察該句子的前三個單詞。因此窗口的寬度就是 m=3:

接著,我們的目標(biāo)就是根據(jù)中心詞“love”,預(yù)測它左右可能出現(xiàn)的詞。怎么實現(xiàn)呢?當(dāng)然先要定一個優(yōu)化目標(biāo)函數(shù)。假設(shè)確定了一個中心詞,我們定的這個函數(shù)要使得周圍詞語出現(xiàn)的對數(shù)概率值最大:
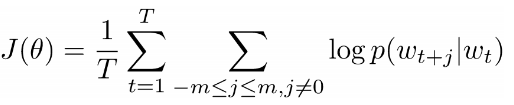
這個函數(shù)很重要,作者強調(diào)一定要認真理解。還是以“love”作為中心詞為例,目標(biāo)函數(shù)的含義就是累加左側(cè)“I”,“love”和右側(cè)“NLP”,“love”四個單詞的對數(shù)概率值。變量T表示訓(xùn)練語句的數(shù)量。下面的式子是對數(shù)函數(shù)的公式:
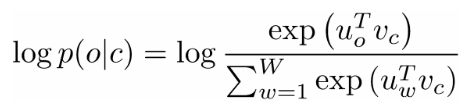
Vc是中心詞的詞向量。每個單詞有兩種表示向量(Uo和Uw)—— 一個用于此單詞作為中心詞的場景,另一個用于此單詞不是中心詞的場景。我們采用隨機梯度下降方法訓(xùn)練詞向量。這個過程是最令人費解的,如果讀者對上述解釋看得云里霧里,作者還向大家推薦了兩篇拓展閱讀文章,第一篇 (https://dzone.com/articles/natural-language-processing-adit-deshpande-cs-unde) 和第二篇 (https://www.youtube.com/watch?v=D-ekE-Wlcds)。
一句話總結(jié):在給出中心詞的情況下,Word2vec的目標(biāo)就是使得上下文詞語的對數(shù)函數(shù)值最大,優(yōu)化方法通常是SGD。
word2vec方法最吸引眼球的效果就是其能夠發(fā)現(xiàn)詞向量之間存在的線性關(guān)系。經(jīng)過訓(xùn)練,詞向量似乎可以捕捉到不同的語法和語義概念:
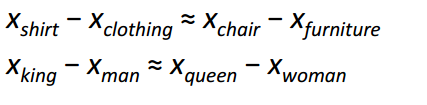
真是不可思議,如此簡單的目標(biāo)函數(shù)和優(yōu)化方法就能夠捕捉到這種線性關(guān)系。
循環(huán)神經(jīng)網(wǎng)絡(luò)
(Recurrent Neural Networks)
好了,現(xiàn)在我們已經(jīng)得到了詞向量,接下去就要把它們?nèi)谌氲窖h(huán)神經(jīng)網(wǎng)絡(luò)模型中。RNN現(xiàn)在已經(jīng)是NLP任務(wù)最常用的方法之一。RNN模型的優(yōu)勢之一就是可以有效利用之前傳入網(wǎng)絡(luò)的信息。下圖就是RNN模型的簡單示意圖:
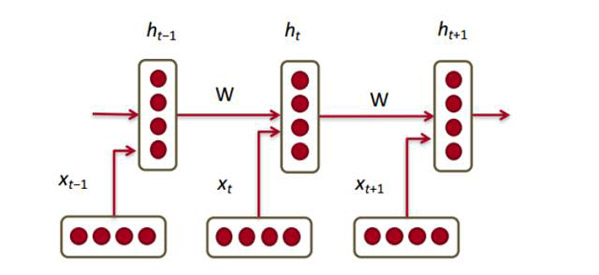
上圖底部,輸入的x是該詞的詞向量。每個向量x對應(yīng)一個隱層的向量h。下圖橙色框內(nèi)的是一個輸入單元:
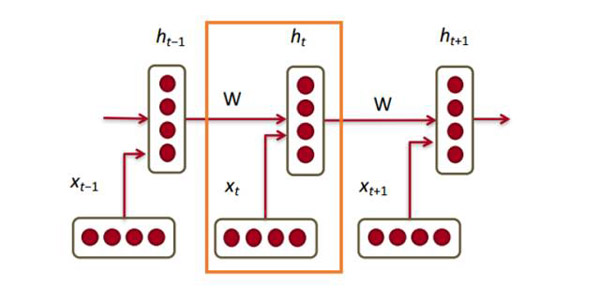
每個單元的隱層向量是當(dāng)前輸入詞向量和上一個隱層狀態(tài)的函數(shù),計算公式如下:
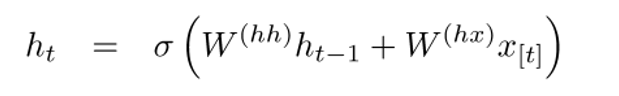
如果你仔細觀察,會發(fā)現(xiàn)公式中有兩個上標(biāo)不同的權(quán)重矩陣Whx和Whh,分別與輸入的詞向量和上一次的隱藏狀態(tài)相乘。這兩個權(quán)重矩陣是網(wǎng)絡(luò)的所有單元共享的。
這就是RNN模型的關(guān)鍵。仔細思考這個過程,它和傳統(tǒng)的兩層神經(jīng)網(wǎng)絡(luò)差別非常大。在傳統(tǒng)的兩層神經(jīng)網(wǎng)絡(luò)中,每層的權(quán)重矩陣各不相同(W1和W2),而在遞歸算機網(wǎng)絡(luò)中,整個序列共享同一個權(quán)重矩陣。
具體到某個單元,它的輸出值y是h和Ws的乘積,即另一個權(quán)值矩陣:
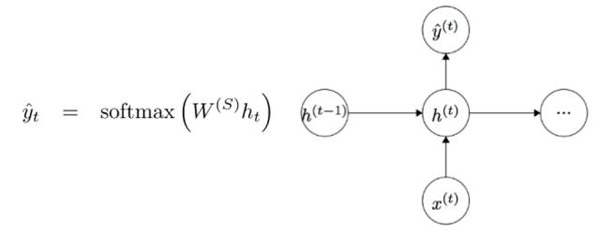
我們再來回顧一下RNN的優(yōu)點。RNN與傳統(tǒng)NN的最大區(qū)別在于RNN輸入的是一個序列(這里就是一系列單詞)。像CNN模型的輸入也只是一張單一的圖片,而RNN的輸入既可以是一句簡短的句子,也可以是一篇5個段落的文章。輸入序列的順序也會極大影響訓(xùn)練效果。理想情況下,隱藏狀態(tài)有望捕捉過去的信息(歷史輸入內(nèi)容)。
門控遞歸單元
(Gated Recurrent Units)
我們再來介紹門控遞歸單元。這種門控單元的目的是為RNN模型在計算隱層狀態(tài)時提供一種更復(fù)雜的方法。這種方法將使我們的模型能夠保持更久遠的信息。為什么保持長期依賴是傳統(tǒng)循環(huán)神經(jīng)網(wǎng)絡(luò)存在的問題呢?因為在誤差反向傳播的過程中,梯度沿著RNN模型由近及遠往回傳播。如果初始梯度是一個很小的數(shù)值(例如 < 0.25),那么在傳播到第三個或第四個模塊時,梯度將幾乎消失(多級梯度連乘),因此較靠前的單元的隱藏狀態(tài)得不到更新。
在傳統(tǒng)的RNN模型中,隱藏狀態(tài)向量的計算公式如下:
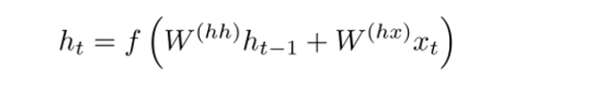
而GRU采取了另一種計算方式。計算過程被分為三塊:更新門,重置門和一個新的記憶存儲器。兩個門都是輸入詞向量與上一步隱藏狀態(tài)的函數(shù):
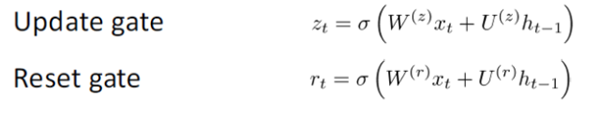
其實,關(guān)鍵的差別之處就在于不同的門有不同的權(quán)重矩陣,通過公式中的上標(biāo)加以區(qū)分。更新門的符號是Wz和Uz,重置門的符號是WT和UT。
新存儲器的計算公式如下:
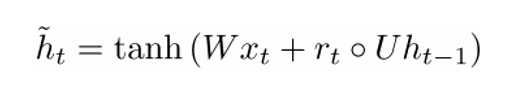
式子中的空心點表示逐元素相乘 (https://en.wikipedia.org/wiki/Hadamard_product_%28matrices%29)。
如果仔細觀察公式,大家會發(fā)現(xiàn)如果重置門單元的輸出值接近于0,那么整一項的值都接近于0,相當(dāng)于忽略了ht-1步的狀態(tài)。此時,模型只考慮當(dāng)前的輸入詞向量xt。
h(t)的最終形式如下公式所示:
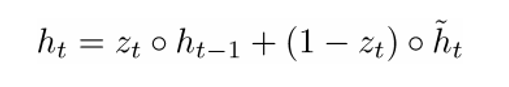
h(t)函數(shù)由三部分組成:更新門,重置門和一個記憶存儲器。當(dāng)zt接近于1時,新的隱藏狀態(tài)ht幾乎完全依賴于上一次的狀態(tài),因為(1-zt)接近0,后一項的乘積也接近于0。當(dāng)zt接近于0時,情況則相反。
長短期記憶單元
(Long Short-Term Memory Units)
如果大家已經(jīng)理解了GRU的原理,那么就能很容易理解LSTM。LSTM同樣也是由多個門控模塊組成:
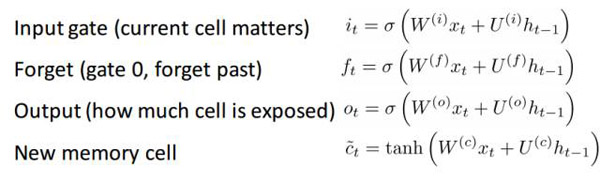
顯然,LSTM引入的信息更多。由于LSTM可以被看作是GRU思路的引申,因此,作者不打算再做太深入的分析,讀者若想要理解每一扇門和每一個公式的來龍去脈,Chris Olah撰寫了一篇精彩的文章 (http://colah.github.io/posts/2015-08-Understanding-LSTMs/)。這是目前為止介紹LSTM的最精彩的教程,一定會對大家理解各個單元的原理有著很大的幫助。
LSTM和GRU對比
我們先來探討兩者的相似之處。原作者認為,這兩種模型都具有保持序列數(shù)據(jù)長期信息依賴的特殊能力。長期信息指的是兩個詞語或者短語之間間隔很遠,但是它們之間的關(guān)系對理解句子又至關(guān)重要。LSTM和GRU都是通過門控模塊來捕捉或是選擇性忽略這些依賴關(guān)系。
兩者的差異之處在于門的數(shù)量,GRU有兩扇門,LSTM有三扇門。門的數(shù)量也會影響到輸入單詞之間的非線性關(guān)系,并且影響最終的計算結(jié)果。GRU也不具有LSTM模型的記憶單元。
寫在閱讀論文之前
要提醒大家一點,NLP領(lǐng)域還有很多很多其它種類的深度學(xué)習(xí)模型,有時候遞歸神經(jīng)網(wǎng)絡(luò)和卷積神經(jīng)網(wǎng)絡(luò)也會用在NLP任務(wù)中,但沒有RNN這么廣泛。
不錯,我們現(xiàn)在已經(jīng)對深度學(xué)習(xí)在自然語言處理領(lǐng)域的應(yīng)用有了清晰的認識,接下來一起就讀幾篇論文吧。NLP領(lǐng)域的方向很多(例如機器翻譯、問答系統(tǒng)等等),我們可以挑選閱讀的文獻也很多,作者從中挑選了三篇具有代表性的。
記憶網(wǎng)絡(luò)(Memory Networks)
原作者挑選的第一篇論文 (http://colah.github.io/posts/2015-08-Understanding-LSTMs/) 是問答領(lǐng)域非常有影響力的一篇文章。此文的作者是Jason Weston, Sumit Chopra, 和 Antoine Bordes,此文介紹了一類稱作記憶網(wǎng)絡(luò)的模型。
直觀的想法是,為了準(zhǔn)確地回答一個文本的問題,我們需要以某種方式來存儲初始信息。如果問大家,“RNN指的是什么”?認真閱讀了文章前半部分的讀者一定能夠回答。只不過大家可能要花幾秒鐘的時間去前文中查找相關(guān)段落。我們暫且不知道人類大腦執(zhí)行這一行為的機制是什么,但一般認為大腦中有一塊區(qū)域來存儲這些信息。
此篇文章所介紹的記憶網(wǎng)絡(luò)獨特之處在于它有一塊可以讀寫的關(guān)聯(lián)記憶區(qū)域。CNN模型、強化學(xué)習(xí)以及傳統(tǒng)的神經(jīng)網(wǎng)絡(luò)都沒有這種記憶功能。也許是因為問答系統(tǒng)重度依賴長期的上下文信息,比如要追溯事件發(fā)生的時間線。對于CNN和強化學(xué)習(xí)而言,它們通過訓(xùn)練不同的濾波器或是狀態(tài)到行為的映射關(guān)系,已經(jīng)將“記憶”體現(xiàn)在權(quán)值矩陣中。乍一看,RNN和LSTM符合要求,但是一般也無法記憶歷史的輸入內(nèi)容(對于問答系統(tǒng)至關(guān)重要)。
網(wǎng)絡(luò)結(jié)構(gòu)
我們一起看看網(wǎng)絡(luò)是如何處理初始輸入內(nèi)容的。和大多數(shù)機器學(xué)習(xí)算法一樣,此方法首先也是將輸入內(nèi)容映射成特征表示。映射的方法可以是詞向量、成分標(biāo)注或者語法分析等等。
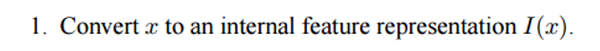
下一步,根據(jù)特征表示I(x)更新記憶內(nèi)容m,以反饋新輸入內(nèi)容x引入的信息。
![]()
我們可以把m看成是若干個mi組成的數(shù)組。每個獨立的mi又可以視為m、特征表示I(x)和其本身的函數(shù)G。記憶內(nèi)容的更新是通過G函數(shù)完成。第三步和第四步是讀取記憶信息,根據(jù)問題生成特征表示o,然后將其解碼輸出得到最終的答案r。

函數(shù)R可以是一個RNN模型,將特征表示轉(zhuǎn)化為我們?nèi)祟惪勺x的文字答案。
針對第三步,我們希望O模塊輸出的特征表示是最匹配該問題的答案。那么,這個問題將與各個記憶單元逐一比較,計算它們之間的匹配得分。
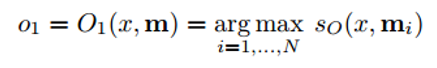
最后,用argmax函數(shù)選出得分最高的一項(或者多項)。計算得分的方法就是將問題的embedding向量與各個記憶單元的特征表示向量相乘(細節(jié)請參見論文 https://arxiv.org/pdf/1410.3916v11.pdf)。這個過程與計算兩個詞向量的相似度類似。輸出的表示特征o再被送入RNN或是LSTM模型,生成最終我們可讀的答案。
整個訓(xùn)練過程屬于監(jiān)督式學(xué)習(xí),訓(xùn)練數(shù)據(jù)包括問題、原始語料、經(jīng)過標(biāo)記的答案。目標(biāo)函數(shù)如下圖所示:
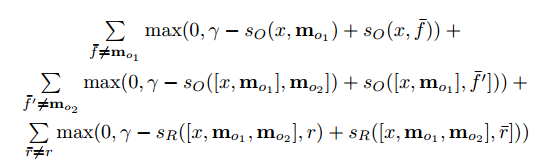
更多的相關(guān)資料可以參見下面幾篇論文:
- End-to-End Memory Networks https://arxiv.org/pdf/1503.08895v5.pdf
- Dynamic Memory Networks https://arxiv.org/pdf/1506.07285v5.pdf
- Dynamic Coattention Networks https://arxiv.org/pdf/1611.01604v2.pdf
情感分析的樹形LSTM模型
下一篇論文 (https://arxiv.org/pdf/1503.00075v3.pdf) 主要內(nèi)容是介紹情感分析的方法,分析某個短語是否包含正面或是負面的情緒。《心理學(xué)大辭典》中認為:“情感是人對客觀事物是否滿足自己的需要而產(chǎn)生的態(tài)度體驗”。LSTM是目前情感分析最常用的網(wǎng)絡(luò)結(jié)構(gòu)。Kai Sheng Tai, Richard Socher, 和 Christopher Manning所發(fā)表的這篇論文介紹了一種新穎的方法將LSTM網(wǎng)絡(luò)串聯(lián)成非線性的結(jié)構(gòu)。
這種非線性排列的動機源自自然語言所具有的屬性,即詞語序列構(gòu)成短語。而詞語的排列順序不同,構(gòu)成的短語含義也不相同,甚至與單個詞語的含義完全相反。為了體現(xiàn)這一特點,LSTM單元構(gòu)成的網(wǎng)絡(luò)必須呈樹狀結(jié)構(gòu)排列,不同的單元受其子節(jié)點的影響。
網(wǎng)絡(luò)結(jié)構(gòu)
樹形LSTM與標(biāo)準(zhǔn)型網(wǎng)絡(luò)結(jié)構(gòu)的差異之一是后者的隱藏狀態(tài)是當(dāng)前輸入與上一步隱藏狀態(tài)的函數(shù),而前者的隱藏狀態(tài)則是當(dāng)前輸入與其子節(jié)點的隱藏狀態(tài)的函數(shù)。
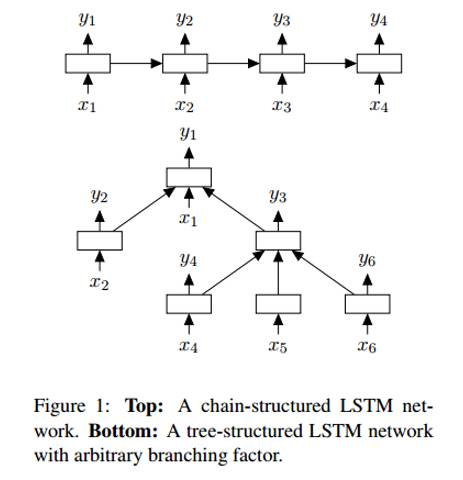
由于網(wǎng)絡(luò)結(jié)構(gòu)的改變,訓(xùn)練的方法也有所變化,具體細節(jié)可以參考這篇文章 (https://arxiv.org/pdf/1503.00075v3.pdf)。作者的關(guān)注點在于為何這種模型的效果比線性LSTM更好。
基于樹形的結(jié)構(gòu),每個獨立單元的狀態(tài)與其所有子節(jié)點的隱藏狀態(tài)都相關(guān)。這一點很重要,因為因為每個節(jié)點可以區(qū)別對待其子節(jié)點。在訓(xùn)練過程中,網(wǎng)絡(luò)模型能學(xué)到某些特殊單詞(比如“not”和“very”)對整句話的情感分析相當(dāng)重要。若模型能給予這部分節(jié)點更大的權(quán)重,最終取得的效果也將更好。
神經(jīng)機器翻譯
作者挑選的最后一篇論文 (https://arxiv.org/pdf/1609.08144v2.pdf) 是關(guān)于機器翻譯的。該文的作者是谷歌的機器學(xué)習(xí)大牛們,Jeff Dean, Greg Corrado, Orial Vinyals等人,這篇文章介紹了支撐谷歌翻譯服務(wù)的基礎(chǔ)系統(tǒng)。該系統(tǒng)相比之前谷歌所用的系統(tǒng),翻譯的平均錯誤率降低了60%。
傳統(tǒng)的自動翻譯方法包括多種短語匹配方法。這種方法需要大量的語言學(xué)的領(lǐng)域知識,而且最終其設(shè)計方案被證明過于脆弱,缺乏泛化能力。傳統(tǒng)方法存在的問題之一,就是它會試圖一塊一塊地翻譯輸入的句子。事實證明,最有效的方法(即神經(jīng)機器翻譯的技術(shù))是一次翻譯整個句子,從而譯文顯得更自然流暢。
網(wǎng)絡(luò)結(jié)構(gòu)
該論文介紹了一種深度LSTM神經(jīng)網(wǎng)絡(luò),包括8個編碼和解碼層,實現(xiàn)端到端的訓(xùn)練過程。這套系統(tǒng)可以拆分為三部分:編碼RNN,解碼RNN和注意力模塊。從宏觀來說,編碼器將輸入的句子表示為向量的形式,解碼器生成輸出表示,注意力模塊則是在解碼階段告訴解碼器該聚焦哪部分內(nèi)容(這就是利用句子整體語境的思想來源):
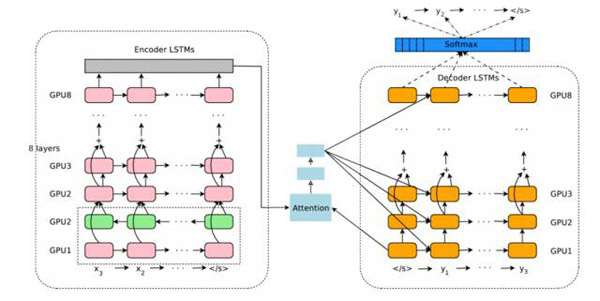
論文的剩余部分主要討論大規(guī)模部署這套系統(tǒng)所面臨的挑戰(zhàn),包括計算資源消耗、延遲,以及高并發(fā)量等等。
總結(jié)
筆者認為,今后深度學(xué)習(xí)會在客戶服務(wù)機器人、機器翻譯以及復(fù)雜的問答系統(tǒng)發(fā)揮作用。特別感謝Richard Socher以及斯坦福CS224D課程 (http://cs224d.stanford.edu/index.html) 老師提供的精彩課堂和幻燈片。