













如何構建用于檢測信用卡詐騙的機器學習模型?
機器學習是我們日常接觸到的許多產品的長期發展動力,從類似于Apple的Siri和Google的智能助手,到類似于亞馬遜的建議你買新產品的推薦引擎,再到Google和Facebook使用的廣告排名系統。最近,機器學習又由于“深度學習”的發展開始進入公眾視線,包括AlphaGo擊敗韓國圍棋大師李世石,并且在圖像識別和機器翻譯領域發布了令人印象深刻的新產品。
我們將介紹一些強大的,但是在機器學習中普遍適用的技術。閱讀之后,你應該具備在你自己的領域著手進行具體機器學習實驗的相應知識。
我們結合一個Python擴展的“案例研究”:我們可以如何構建用于檢測信用卡詐騙的機器學習模型?(雖然我們會使用詐騙檢測語言,所做的大部工作是在微小修改基礎上適用于其他分類問題,例如,廣告點擊預測。)隨著時間的推移,我們會遇到許多機器學習的關鍵思想和術語,包括邏輯回歸、決策樹、隨機森林、正向預測(True Positive)和負向預測(False Positive)、交叉驗證(cross-validation),以及受試者工作特征(Receiver Operating Characteristic,簡稱ROC)曲線和曲線以下區域(Area Under the Curve,簡稱AUC)曲線。
目標:信用卡詐騙
在線銷售產品的企業不可避免地需要應對欺詐行為。一個典型的欺詐交易,詐騙者使用偷來的信用卡號碼去在線網站購買商品。欺詐者稍后會在其他地方以打折形式銷售這些商品,中飽私囊,然而企業必須承擔“退款”成本。你可以從這里獲取信用卡詐騙的詳細內容。
讓我們假設自己是一個電子商務企業,并且已經應對詐騙有一些時間了,我們想要使用機器學習幫助解決問題。更具體地說,每次交易進行時,我們想要去預測是否可以證明是詐騙者(例如,是否授權的持卡人不是交易人),這樣我們可以相應地采取行動。這類機器學習問題被稱為分類,因為我們正在做的就是把每筆收入歸入欺詐或非欺詐這兩類中的其中一類。
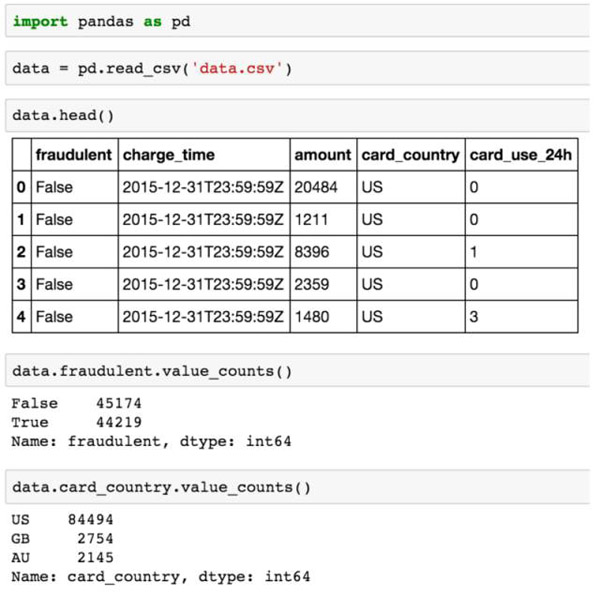
對于每一筆歷史付款,我們有一個布爾值指示表明這筆交易是否欺詐(fraudulent),以及一些我們認為可能表明欺詐的其他屬性,例如,以美元支付的金額(amount)、卡片開卡國家(card_country),以及這張卡片同一天內在我們企業的支付次數(card_use_24h)。因此,極有可能我們建立預測模型的數據看起來如以下CSV所示:
- fraudulent,charge_time,amount,card_country,card_use_24h
- False,2015-12-31T23:59:59Z,20484,US,0
- False,2015-12-31T23:59:59Z,1211,US,0
- False,2015-12-31T23:59:59Z,8396,US,1
- False,2015-12-31T23:59:59Z,2359,US,0
- False,2015-12-31T23:59:59Z,1480,US,3
- False,2015-12-31T23:59:59Z,535,US,3
- False,2015-12-31T23:59:59Z,1632,US,0
- False,2015-12-31T23:59:59Z,10305,US,1
- False,2015-12-31T23:59:59Z,2783,US,0
有兩個重要的細節我們會在討論里跳過,但是我們需要牢記于心,因為它們同樣重要,甚至超過我們在這里介紹的模型構建問題。
首先,確定我們認為存在詐騙行為的特征是一個數據科學問題。在我們的例子中,我們已經確認支付的金額、這張卡片是在哪個國家發行的,以及過去一天里我們收到的卡片交易次數等作為特征,我們認為這些特征可能可以有效預測詐騙。一般來說,你將需要花費許多時間查看這些數據,以決定什么是有用的,什么是沒有用的。
其次,計算特征值的時候存在數據基準問題:我們需要所有歷史樣本值用于訓練模型,但是我們也需要把他們的實時付款值加進來,用以正確地對新的交易加入訓練。當你開始擔憂詐騙之前,你已經維持和記錄了過去24小時滾動記錄的信用卡使用次數,這樣如果你發現特征是有利于詐騙檢測的,你將會需要在生產環境和批量環境中分別在計算中使用它們。依賴于定義的不同特征,結果很有可能是不一樣的。
這些問題合在一起通常被認為是特征工程,并且通常是工業級機器學習領域最常涉及(有影響)的部分。
邏輯回歸
讓我們以一個最基本的模型開始,一個線性模型。我們將會發現系數a、b、...、z,如下
![]()
對于每一筆支付,我們會將amount、card_country和card_use_24h的值代入到上面的公式中,如果概率大于0.5,我們會“預測”這筆支付是欺詐的,反之我們將會預測它是合法的。
在我們討論如何計算a、b、...、z之前,我們需要解決兩個當前問題:
概率(欺詐)需要在0和1之間的一個數字,但是右側的數量可以任意大(絕對值),取決于amount和 card_use_24h的值(如果那些特征的值足夠大,并且a或者b至少有一個非零)。
card_country不是一個數字,它從許多值中取其一(例如US、AU、GB,以及等等)。這些特征被稱為分類的,并且需要在我們可以訓練模型之前進行適當地“編碼”。
Logit函數
為了解決問題(1),我們會建立一個稱為詐騙者的log-odds模型,而不是直接通過p = Probability(fraud)構建模型,所以我們的模型就變成

如果一個事件發生的概率為p,它的可能性是p / (1 - p),這就是為什么我們稱公式左邊為“對數幾率(log odds)”或者“logit”。
考慮到a、b、...、z這些值和特征,我們可以通過反轉上面給出的公式計算預測詐騙概率,得到以下公式
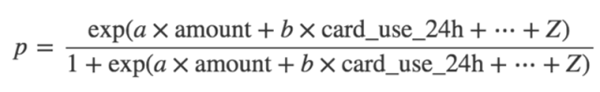
詐騙p的概率是線性函數的轉換函數L=a x amount + b x card_use_24h + …,看起來如下所示:
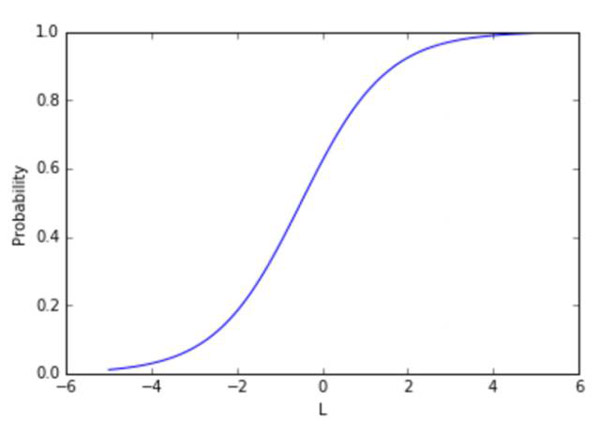
不考慮線性函數的值,sigmoid映射為一個在0和1之間的數字,這是一個合法的概率。
分類變量
為了解決問題(2),我們會使用分類變量 card_country(拿N個不同值中的1個)并且擴展到N-1“虛擬”變量。這些新的特征是布爾型格式,card_country = AU、card_country = GB等等。我們只是需要N-1“虛擬”,因為當N-1虛擬值都是false的時候N值是必然包含的。為了簡單起見,讓我們假設card_country可以僅僅使用AU、GB和US三個值中的一個。然后我們需要兩個虛擬變量去對這個值進行編碼,并且我們想要去適配的模型(例如,發現系數值)是:
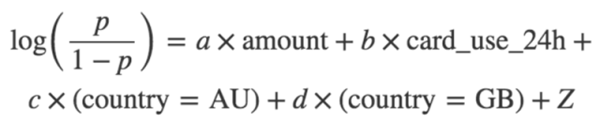
模型類型被稱為一個邏輯回歸。
擬合模型
我們如何確定a、b、c、d和Z的值?讓我們以隨機選擇a、b、c、d和Z的方式開始。我們可以定義這套猜測的可能性如:
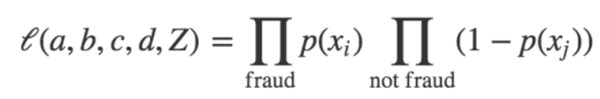
也就是說,從我們的數據集里取出每一個樣本,并且計算詐騙p的預測概率,提供給猜測a、b、c、d和Z(每個樣本的特征值)的值使用:
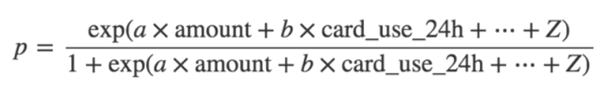
對于每個實際上是欺詐的樣本,我們希望p比較接近1,而對于每一個不是詐騙的樣本,我們希望p接近0(所以1-p應該接近1)。因此,我們對于所有欺詐樣本采用p產品,對于所有非欺詐樣本采用1-p產品,用以得到評估,猜測a、b、c、d和Z有多好。我們想讓似然函數盡可能大(例如,盡可能地接近1)。開始我們的猜測,我們迭代地調整a、b、c、d和Z,提高可能性,直到我們發現不可以再通過擾動系數提升它的值。一種常用的優化方式是隨機梯度下降。
Python實現
現在我們將會使用標準的Python開源工具實踐我們剛剛討論完的原理。我們將會使用pandas,它給Python帶來了類似于R語言的大規模數據科學的API(R-like data frames),以及scikit-learn,它是一個熱門的機器學習包。讓我們對之前描述過的CSV文件命名為“data.csv”;我們可以上傳數據并看一下下面的代碼:
我們可以使用如下代碼編碼card_country成為合適的虛擬變量
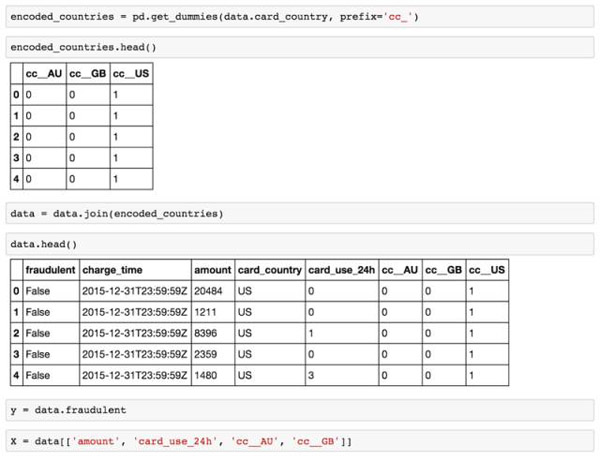
現在大規模數據幀數據擁有了所有我們需要的數據、虛擬變量以及所有用于訓練我們的模型的數據。我們對目標進行切分(在這種欺詐情況下嘗試預測變量)以及用scikit需要的屬性作為不同的輸入參數。
在進行模型訓練之前,我們還有一個問題需要討論。我們希望我們的模型歸納充分,例如,當對付款進行分類時應該是準確的,它應該是我們之前沒有見過的方式,而不應該僅僅是之前見過那些在支付時計算的特殊模式。為了確保不會在現有的數據中過度擬合模型成為噪聲,我們將會分割數據為兩個訓練集,一個訓練集會被用來評估模型參數(a、b、c、d和Z)以及驗證集(也被叫做測試集),另一個數據集會被用來計算模型性能指標(下一章我們會介紹)。如果一個模型是過度擬合的,它會在訓練集上表現良好(因為它會在該集合中學習模式),但是在驗證集上表現較差。還有其他的交叉驗證方式(例如,k-fold交叉驗證),但是“測試訓練”分離會適合我們這里的目的。
我們使用sckit可以很輕松地分割數據為訓練和測試集,如下:

在這里例子中,我們會使用數據的2/3用于訓練模型,數據的1/3用于驗證模型。我們現在準備去訓練模型,在此它只是個瑣碎小事:
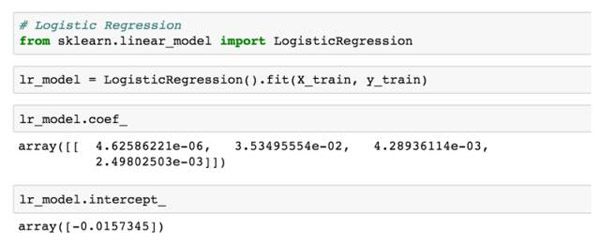
該擬合函數運行擬合程序(***化上面提到的似然函數),然后我們可以針對a、b、c、d(在coef_)和Z(在intercept_)的值查詢返回的對象。因此我們的最終模型是
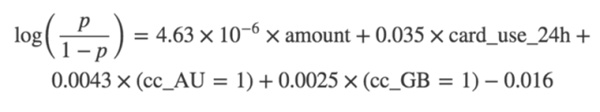
評價模型表現
一旦訓練了模型之后,我們就需要去確定這個模型在預測感興趣的變量上究竟有多好了(在本例子中,該布爾值表明該支付是否存在欺詐)。回想一下我們曾經說過希望對支付按照欺詐進行分類,如果概率(欺詐)大于0.5,我們希望將其歸類為合法的。針對一個模型和一個分類規則的性能評定方式,通常使用兩個變量,如下所示:
假陽性率:所有合法費用中被錯誤地分類為欺詐的那部分,以及
真陽正率(也被稱為召回率或者敏感性指標),所有欺詐收入中被正確地分類為欺詐的那部分。
評估分類性能有很多方式,我們會鎖定這兩個變量。
理想情況下,假陽性率將會接近0并且真陽正率會接近1。當我們改變概率閾值時我們把一筆費用分類為欺詐的(上面我們說是0.5,但是我們可以選擇0和1之間的任何值,越小的值意味著我們更加積極地標記支付為欺詐的,而高的值意味著我們更加保守),假陽性率和真陽正率勾畫了一個曲線,這個曲線依賴于我們的模型有多好。我們稱之為受試者工作特征曲線(ROC曲線),可以使用scikit很容易計算出來:
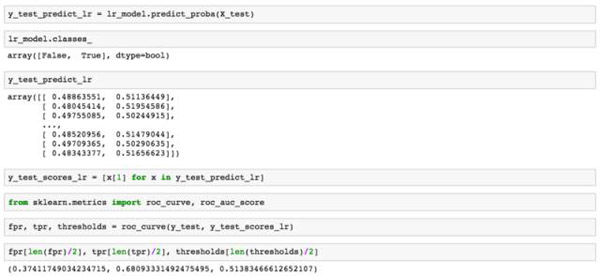
變量fpr、tpr和閾值包含了所有ROC曲線的數據,但是我們挑選了一些有針對性的樣本:如果概率(欺詐)大于0.514,而假陽性率是0.374,真陽性率是0.681時,我們假定該費用為欺詐。我們所選的ROC曲線及描繪點為:
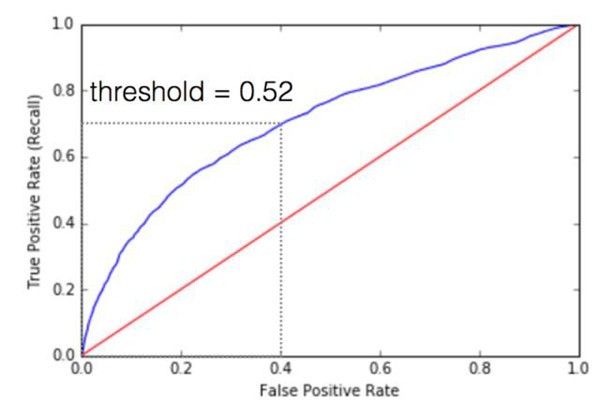
模型性能較好,越接近ROC曲線(上面藍色的線),越會緊靠圖形左上方的邊框。注意ROC曲線可以告訴你模型有多好,可以使用一個AUC數計算,或者查看曲線下的面積。AUC值越接近于1,模型性能越好。

當然,當你把模型值放入生產環境并使用它時,你通常會需要去通過我們上面采用的方式,即比較他們的閾值方式采取行動輸出概率模型,如果概率(欺詐)>0.5,我們認為一筆費用被假設為是欺詐的。因此,對于一個特定的應用程序,模型性能對應于ROC曲線上的一個點,曲線整體再一次僅僅控制了假陽性率和真陽正率之間的交易平衡,例如,政策選擇范圍內的處置方式不同。
決策樹與隨機森林
上述的邏輯回歸模型是線性機器學習模型的一個示例。想象一下,我們有的每一筆支付示例是空間里的一個點,這個點的坐標就是特征值。如果我們僅僅有兩個特征值,每個示例點會是X-Y平面上的一個點。如果在我們可以使用線性函數把無欺詐樣本和欺詐者樣本區分開時,通常類似于邏輯回歸的線性模型就能較好地運行,這意味著幾乎所有欺詐樣本處于一條線的一邊,而幾乎所有的非欺詐樣本處于這條線的另一邊。
通常情況下,預測特征和目標變量之間的關系,我們試圖預測這個關系是非線性的,在這種情況下,我們需要使用非線性模型計算關系。一個強有力的、較為直觀的非線性模型是決策樹,如下所示:
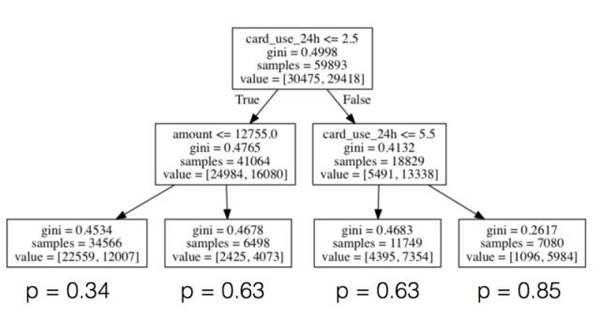
對于每個節點,我們將特定特征的值和一些閾值進行比較,根據比較結果分出向左還是向右。我們繼續以這種方式(類似一個于二十問的游戲,雖然數目不需要二十層深度),直到我們到達樹木的樹葉。樹葉由我們訓練集里的所有的樣本組成,比較這棵樹上的每一個節點的滿意路徑,示例樹葉上欺詐那一部分被模型報告預測的概率判定為欺詐。當我們有新的樣本需要被分類時,直到到達樹葉之前,我們生成它的特征并且開始玩“二十問的游戲”,然后預測欺詐的可能性,并描述如下。
雖然我們不會去深究樹是如何生成的細節內容(雖然,簡單來說我們就是為每一個節點選擇特征和閾值,***化信息增益或者辨別力概念,即上述圖表中報告的基尼系數,并在達到預先指定的一些停止標準前一直進行遞歸),使用scikit訓練決策樹模型就像訓練邏輯回歸一樣容易(或者事實上在任何其他模型上):
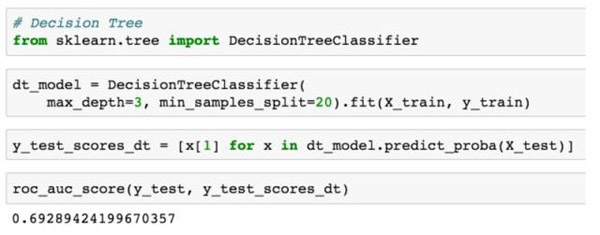
決策樹的一個問題是它們很容易被過度擬合,一棵很深的樹的每個葉子僅僅是訓練數據里的一個示例,通常會計算每個樣本的噪音,并且可能不是常見趨勢,但是隨機森林模型可以幫助解決這個問題。在一個隨機森林中,我們訓練大量的決策樹,但是每棵樹的訓練僅僅是我們現有的數據的一個子集,并且當構建每棵樹時我們僅僅考慮了切分的子集特征。所預測的欺詐的概率是森林里所有樹所生產的平均概率。僅基于數據子集對每棵樹進行訓練,僅將特征的子集作為每個節點的分離候選來考慮,減少樹木之間的相關性,讓過度擬合更少一些。
綜上所述,當特征和目標變量之間的關系是線性時,像邏輯回歸這樣的線性模型是適當的,或者當你希望分離任務特征對預測的影響(因為這樣可以直接讀取回歸系數)。另一方面,像決策樹這樣的非線性模型和隨機森林是很難解釋的,但是他們可以被用來計算更復雜的關系。
產品化機器學習模型
訓練一個機器學習模式可以被認為僅僅是使用機器學習解決業務問題過程的***步。正如上面描述的,模型訓練通常必須在特征工程開始工作前完成。一旦有了模型就需要去產品化它了,也就是說,讓這個模型可以用于生產環境并可以采取適當的行動(例如,阻止被評估為欺詐的交易)。
雖然我們不會在這里談論細節,但是產品化會引入許多挑戰,例如,你可以使用Python部署模型,但是你的生產環境軟件棧使用的是Ruby。如果出現這種情況,你將會需要讓你的模型通過一定格式的序列化形式從Python轉為Ruby,并且讓你生產環境的Ruby代碼讀取序列化,或者使用面向服務的系統架構實現從Python到Ruby的服務請求,二選一。
對于完全不同性質的問題,你也會想要在生產環境下維持度量模型性能(與驗證數據的大量計算不同)。依賴于你如何使用模型,這個過程可能比較困難,因為僅僅使用模型去控制行為的方式可以導致你沒有數據計算你的度量。本系列的其他文章將會考慮一些這類問題。
支撐材料
包含所有的示例代碼的Jupyter筆記、模型訓練樣本數據可以"閱讀原文“的原文鏈接中找到。
作者介紹
Michael Manapat (@mlmanapat) ,在Stripe負責領導機器學習產品開發工作,包括Stripe Radar。在加入Stripe之前,他是Google的一名工程師,同時也是哈佛大學應用數學專業博士后研究員和講師。他從麻省理工大學(MIT)獲得了數學專業博士學位。

















