













cinder-volume如何實現Active/Active高可用
一、分布式鎖介紹
1.1 何謂“鎖”?
鎖(Lock),在我們生活當中再熟悉不過了,它的主要作用就是鎖住某個物體或者某個區域空間,一方面阻止無鎖者進入查看受隱私保護的東西,二來阻止惡意者實施破壞。比如我們都會對手機加鎖來防止別人偷窺自己的隱私,我們通過鎖門來阻止壞人進入家里偷竊等等。
在計算機的世界,鎖同樣重要,并且功能和我們生活當中的鎖基本是一樣的,只是管理的對象不一樣而已。計算機的鎖是為了鎖住某個計算機資源或者數據,不允許其它用戶或者進程隨意訪問讀取,或者保護數據不被其它程序惡意篡改。除此之外,鎖還具有同步的功能,即保證A任務完成之后才能執行B任務,而不能順序顛倒,也不能在A完成到一半時,B就開始執行。
我們的服務器幾乎都是使用多用戶分時操作系統,意味著同一時間有多個用戶執行多個進程并且同時運行著,即使是同一進程,也有可能包含有多個線程跑著。如果我們不對一些互斥訪問的資源進行加鎖,勢必會亂套,試想下同時多個程序不加控制的使用同一臺打印機會造成什么惡果。除了資源,對數據的加鎖保護也同樣重要,如果沒有鎖,數據就會各種紊亂,比如你的記賬管理系統,開始總額有5000元,入賬5000元,此時總額應該就有10000元了,但還沒有來得及更新到數據庫中去,此時,你的另一個進程開始讀取總額,由于之前入賬的5000塊還沒有更新,取出來的總額還是原來的5000元,顯然讀取的這5000元是過時的老數據,在操作系統術語中稱為臟數據。更詭秘的是,此時你的第二個進程開始出賬3000塊,此時開始寫入剩余總額2000元。此時你的兩個進程可能同時在寫數據,假設你的進程一先寫完(寫入10000),你的第二個進程寫入2000元覆蓋掉了剛剛寫入的10000元,***你的總額為2000元,你剛剛入賬的5000元莫名其妙地蒸發了。以上情況就是事務處理中ACID的數據不一致性問題。
閱讀本文讀者只需要知道鎖的作用即可,更多關于并發控制的有關概念(比如幻讀、不可重復讀、原子性、持久性等)以及各種鎖的概念(互斥鎖、共享鎖、樂觀鎖、悲觀鎖、死鎖等)不是本文討論的重點,感興趣的讀者請自行Google之。
1.2 鎖的實現非權威解讀
生活當中的鎖原理其實很簡單,傳統的機械鎖可以當作是一種機關,通過匹配形狀齒輪觸發機關某個部位而解鎖。而現代的鎖原理更簡單,加鎖其實就是設置一種狀態,而要解除該狀態只需要比對信息,比如數字密碼、指紋等。
計算機中的鎖,根據運行環境可以大體分為以下三類:
- 同一個進程。此時主要管理該進程的多個線程間同步以及控制并發訪問共享資源。由于進程是共享內存空間的,一個最簡單的實現方式就是使用一個整型變量作為flag,這個flag被所有線程所共享,其值為1表示已上鎖,為0表示空閑。使用該方法的前提是設置(set)和獲取(get)這個flag變量的值都必須是原子操作,即要么成功,要么失敗,并且中間不允許有中斷,也不允許出現中間狀態。可幸的是,目前幾乎所有的操作系統都提供了此類原子操作,并已經引入了鎖機制,所以以上前提是可以滿足的。
- 同一個主機。此時需要控制在同一個操作系統下運行的多個進程間如何協調訪問共享資源。不同的進程由于不共享內存空間,因此不能通過設置變量來實現。既然內存不能共享,那磁盤是共享的,因此我們自然想到可以通過創建一個文件作為鎖標記。進程只需要檢查文件是否存在來判斷是否有鎖。
- 不同主機。此時通常跑的都是分布式應用,如何保證不同主機的進程同步和避免資源訪問沖突。有了前面的例子,相信很多人都想到了,使用共享存儲不就可以了,這樣不同主機的進程也可以通過檢測文件是否存在來判斷是否有鎖了。
以上介紹了鎖的非權威實現,為了解釋得更簡單通俗,其實隱瞞了很多真正實現上的細節,甚至可能和實際的實現方式并不一致。要想真正深入理解操作系統的鎖機制以及單主機的鎖機制實現原理,請查閱更多的文獻。本文接下來將重點討論分布式鎖,也就是前面提到的不同主機的進程間如何實現同步以及控制并發訪問資源。
1.3 分布式鎖以及DLM介紹
毫無疑問,分布式鎖主要解決的是分布式資源訪問沖突的問題,保證數據的一致性。前面提到使用共享存儲文件作為鎖標記,這種方案只有理論意義,實際上幾乎沒有人這么用,因為創建文件并不能保證是原子操作。另一種可行方案是使用傳統數據庫存儲鎖狀態,實現方式也很簡單,檢測鎖時只需要從數據庫中查詢鎖狀態即可。當然,可能使用傳統的關系型數據庫性能不太好,因此考慮使用KV-Store緩存數據庫,比如redis、memcached等。但都存在問題:
- 不支持堵塞鎖。即進程獲取鎖時,不會自己等待鎖,只能通過不斷輪詢的方式判斷鎖的狀態,性能不好,并且不能保證實時性。
- 不支持可重入。所謂可重入鎖就是指當一個進程獲取了鎖時,在釋放鎖之前能夠***次重復獲取該鎖。試想下,如果鎖是不可重入的,一個進程獲取鎖后,運行過程中若再次獲取鎖時,就會不斷循環獲取鎖,可實際上鎖就在自己的手里,因此將***進入死鎖狀態。當然也不是沒法實現,你可以順便存儲下主機和進程ID,如果是相同的主機和進程獲取鎖時則自動通過,還需要保存鎖的使用計數,當釋放鎖時,簡單的計數-1,只有值為0時才真正釋放鎖。
另外,鎖需要支持設置最長持有時間。想象下,如果一個進程獲取了鎖后突然掛了,如果沒有設置最長持有時間,鎖就永遠得不到釋放,成為了該進程的陪葬品,其它進程將永遠獲取不了鎖而陷入***堵塞狀態,整個系統將癱瘓。使用傳統關系型數據庫可以保存時間戳,設置失效時間,實現相對較復雜。而使用緩存數據庫時,通常這類數據庫都可以設置數據的有效時間,因此相對容易實現。不過需要注意不是所有的場景都適合通過鎖搶占方式恢復,有些時候事務執行一半掛了,也不能隨意被其它進程強制介入。
支持可重入和設置鎖的有效時間其實都是有方法實現,但要支持堵塞鎖,則依賴于鎖狀態的觀察機制,如果鎖的狀態一旦變化就能立即通知調用者并執行回調函數,則實現堵塞鎖就很簡單了。慶幸的是,分布式協調服務就支持該功能,Google的Chubby就是非常經典的例子,Zookeeper是Chubby的開源實現,類似的還有后起之秀etcd等。這些協調服務有些類似于KV-Store,也提供get、set接口,但也更類似于一個分布式文件系統。以Zookeeper為例,它通過瞬時有序節點標識鎖狀態,請求鎖時會在指定目錄創建一個瞬時節點,節點是有序的,Zookeeper會把鎖分配給節點最小的服務。Zookeeper支持watcher機制,一旦節點變化,比如節點刪除(釋放鎖),Zookeeper會通知客戶端去重新競爭鎖,從而實現了堵塞鎖。另外,Zookeeper支持臨時節點的概念,在客戶進程掛掉后,臨時節點會自動被刪除,這樣可實現鎖的異常釋放,不需要給鎖增加超時功能了。
以上提供鎖服務的應用我們通常稱為DLM(Distributed lock manager),對比以上提到的三種類型的DLM:
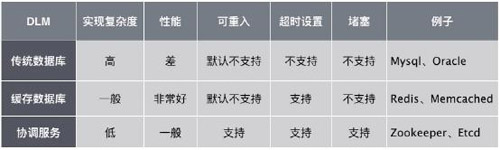
注: 以上支持度僅考慮最簡單實現,不涉及高級實現,比如傳統數據庫以及緩存數據庫也是可以實現可重入的,只是需要花費更多的工作量。
二、OpenStack Tooz項目介紹
2.1 Tooz為何而生?
前面介紹了很多實現分布式鎖的方式,但也只是提供了實現的可能和思路,而并未達到拿來即用的地步。開發者仍然需要花費大量的時間完成對分布式鎖的封裝實現。使用不同的后端,可能還有不同的實現方式。如果每次都需要重復造輪子,將浪費大量的時間,并且質量難以保證。
你一定會想,會不會有人已經封裝了一套鎖管理的庫或者框架,只需要簡單調用lock、trylock、unlock即可,不用關心底層內部實現細節,也不用了解后端到底使用的是Zookeeper、Redis還是Etcd。curator庫實現了基于Zookeeper的分布式鎖,但不夠靈活,不能選擇使用其它的DLM。OpenStack社區為了解決項目中的分布式問題,開發了一個非常靈活的通用框架,項目名為Tooz,它實現了非常易用的分布式鎖接口,本文接下來將詳細介紹該項目。
2.2 Tooz
Tooz是一個python庫,提供了標準的coordination API。最初由eNovance幾個工程師編寫,其主要目標是解決分布式系統的通用問題,比如節點管理、主節點選舉以及分布式鎖等,更多Tooz背景可參考Distributed group management and locking in Python with tooz。Tooz抽象了高級接口,支持對接十多種DLM驅動,比如Zookeeper、Redis、Mysql、Etcd、Consul等,其官方描述為:
- The Tooz project aims at centralizing the most common distributed primitives like group membership protocol, lock service and leader ?election by providing a coordination API helping developers to build distributed applications.
使用Tooz也非常方便,只需要三步:
1.與后端DLM建立連接,獲取coordination實例。
2.聲明鎖名稱,創建鎖實例
3.使用鎖
官方給出了一個非常簡單的實例,如下:
- from tooz import coordination
- coordinator = coordination.get_coordinator('zake://', b'host-1')
- coordinator.start()
- # Create a lock
- lock = coordinator.get_lock("foobar")
- with lock:
- ...
- print("Do something that is distributed")
- coordinator.stop()
由于該項目***是由Ceilometer項目core開發者發起的,因此tooz***在Ceilometer中使用,主要用在alarm-evaluator服務。目前Cinder也正在使用該庫來實現cinder-volume的Active/Active高可用,將在下文重點介紹。
三、分布式鎖在Cinder中的應用
3.1 Cinder之傷
Cinder是OpenStack的核心組件之一,為云主機提供可擴展可伸縮的塊存儲服務,用于管理volume數據卷資源,類似于AWS的EBS服務。cinder-volume服務是Cinder最關鍵的服務,負責對接后端存儲驅動,管理volume數據卷生命周期,它是真正干活的服務。
顯然volume數據卷資源也需要處理并發訪問的沖突問題,比如防止刪除一個volume時,另一個線程正在基于該volume創建快照,或者同時有兩個線程同時執行掛載操作等。cinder-volume也是使用鎖機制實現資源的并發訪問,volume的刪除、掛載、卸載等操作都會對volume加鎖。在OpenStack Newton版本以前,Cinder的鎖實現都是基于本地文件實現的,該方法在前面已經介紹過,只不過并不是根據文件是否存在來判斷鎖狀態,而是使用了Linux的flock工具進行鎖管理。Cinder執行加鎖操作默認會從配置指定的lockpath目錄下創建一個命名為cinder-volume_uuid-{action}的空文件,并對該文件使用flock加鎖。flock只能作用于同一個操作系統的文件鎖,即使使用共享存儲,另一個操作系統也不能判斷是否有鎖,一句話說就是Cinder使用的是本地鎖。
我們知道OpenStack的大多數無狀態服務都可以通過在不同的主機同時運行多個實例來保證高可用,即使其中一個服務掛了,只要還存在運行的實例就能保證整個服務是可用的,比如nova-api、nova-scheduler、nova-conductor等都是采用這種方式實現高可用,該方式還能實現服務的負載均衡,增加服務的并發請求能力。而極為不幸的是,由于Cinder使用的是本地鎖,導致cinder-volume服務長期以來只能支持Active/Passive(主備)HA模式,而不支持Active/Active(AA,主主)多活,即對于同一個backend,只能同時起一個cinder-volume實例,不能跨主機運行多個實例,這顯然存在嚴重的單點故障問題,該問題一直以來成為實現Cinder服務高可用的痛點。
因為cinder-volume不支持多實例,為了避免該服務掛了導致Cinder服務不可用,需要引入自動恢復機制,通常會使用pacemaker來管理,pacemaker輪詢判斷cinder-volume的存活狀態,一旦發現掛了,pacemaker會嘗試重啟服務,如果依然重啟失敗,則嘗試在另一臺主機啟動該服務,實現故障的自動恢復。該方法大多數情況都是有效的,但依然存在諸多問題:
- 在輪詢服務狀態間隔內掛了,服務會不可用。即不能保證服務的連續性和服務狀態的實時性。
- 有時cinder-volume服務啟動和停止都比較慢,導致服務恢復時間較長,甚至出現超時錯誤。
- 不支持負載均衡,極大地限制了服務的請求量。
- 有時運維不當或者pacemaker自身問題,可能出現同時起了兩個cinder-volume服務,出現非常詭秘的問題,比如volume實例刪不掉等。
總而言之,cinder-volume不支持Active/Active HA模式是Cinder的一個重大缺陷。
3.2 Cinder的"進化"
玩過三國殺的都知道,很多武將最開始都比較脆弱,經過各種虐殺后會觸發覺醒技能,又如pokemon完成一次進化,變得異常強大。cinder-volume不支持AA模式一直受人詬病,社區終于在Newton版本開始討論實現cinder-volume的AA高可用,準備引入分布式鎖替代本地鎖,這可能意味著Cinder即將完成一次功能突發變強的重大進化。
Cinder引入分布式鎖,需要用戶自己部署和維護一套DLM,比如Zookeeper、Etcd等服務,這無疑增加了運維的成本,并且也不是所有的存儲后端都需要分布式鎖。社區為了滿足不同用戶、不同場景的需求,并沒有強制用戶部署固定的DLM,而是采取了非常靈活的可插除方式,使用的正是前面介紹Tooz庫。當用戶不需要分布式鎖時,只需要指定后端為本地文件即可,此時不需要部署任何DLM,和引入分布式鎖之前的方式保持一致,基本不需要執行大的變更。當用戶需要cinder-volume支持AA時,可以選擇部署一種DLM,比如Zookeeper服務。
Cinder對Tooz又封裝了一個單獨的coordination模塊,其源碼位于cinder/coordination.py,需要使用同步鎖時,只需要在函數名前面加上@coordination.synchronized裝飾器即可(有沒有突然想到Java的synchronized關鍵字 ),方便易用,并且非常統一,而不像之前一樣,不同的函數需要加不同的加鎖裝飾器。比如刪除volume操作的使用形式為:
- @coordination.synchronized('{volume.id}-{f_name}')
- @objects.Volume.set_workers
- def delete_volume(self, context, volume, unmanage_only=False,
- cascade=False):
- ...
后端的不同主機置于一個cluster中,只有在同一個cluster的主機存在鎖競爭,不同cluster的主機不存在鎖競爭。
不過截至到剛剛發布的Ocata版本,cinder-volume的AA模式還正處于開發過程中,其功能還沒有完全實現,還不能用于生產環境中部署。我們期待cinder-volume能夠盡快實現AA高可用功能,云極星創也會持續關注該功能的開發進度,并加入社區,與更多開發者一起完善該功能的開發。
四、總結
本文首先介紹了分布式鎖的概念,詳細介紹了分布式鎖多種實現方式以及它們的優缺點。然后介紹了OpenStack Tooz項目,該項目實現了分布式鎖的通用框架,支持對接不同的DLM。***介紹了Openstack Cinder實現高可用的痛點問題以及討論了社區當前正如何使用分布式鎖來實現cinder-volume服務的AA高可用模式。
參考文獻
1.Building a Distributed Lock Revisited: Using Curator's InterProcessMutex.
3 .并發控制.
5 Distributed group management and locking in Python with tooz.
6 Cinder Volume Active/Active support - Manager Local Locks.
7 etcd API: Waiting for a change.
8 The Chubby lock service for loosely-coupled distributed systems.
10 A Cinder Road to Active/Active HA.
【本文是51CTO專欄作者“付廣平”的原創文章,如需轉載請通過51CTO獲得聯系】











