













TensorFlow調試程序介紹
我們懷著激動的心情與大家分享 TensorFlow 調試程序 (tfdbg),這個工具可以簡化 TensorFlow 中對機器學習 (ML) 模型的調試。
TensorFlow 是 Google 的開源 ML 內容庫,基于數據流圖表。一個典型的 TensorFlow ML 程序包括兩個獨立的階段:
- 利用內容庫的 Python API 將 ML 模型設置為數據流圖表;
- 利用 Session.run() 方法在圖表上訓練或執行推理。
如果在第二階段(即 TensorFlow 運行時)出現錯誤和缺陷,將難以進行調試。
要了解出現這種情況的原因,請注意對標準 Python 調試程序而言,Session.run() 調用實際上是單個語句,它并不會公開運行中圖表的內部結構(節點及其連接)和狀態(節點的輸出數組 或 張量)。gdb 等較低級別的調試程序在組織堆疊框架和變量值時無法令其與 TensorFlow 圖表操作產生關聯。專業級運行時調試程序是 TensorFlow 用戶最常提出的功能請求之一。
tfdbg 滿足了這一運行時調試需求。讓我們通過一段簡短的代碼來了解 tfdbg 的實用效果,這段代碼的作用是建立并運行一個簡單的 TensorFlow 圖表,以通過梯度下降法擬合一個簡單的線性方程。
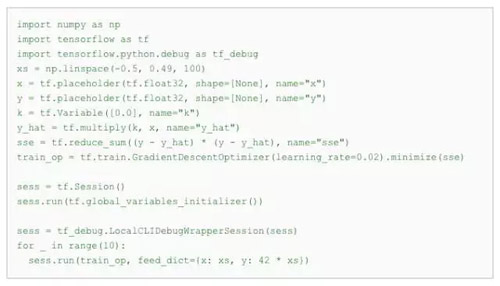
正如本例中突出顯示的線條所示,會話對象包裝成一個用于調試的類 (LocalCLIDebugWrapperSession),因此調用 run() 方法會啟動 tfdbg 的命令行界面 (CLI)。您可以利用鼠標點擊或命令執行一遍連續運行調用,檢查圖表的節點及其屬性,通過中間張量列表將圖表中所有相關節點完整的執行歷史記錄可視化。通過使用 invoke_stepper 命令,您可以讓 Session.run() 調用在“步進器模式”下執行,在這種模式下,您可以步進到自己選擇的節點,觀察并修改其輸出,然后再執行進一步的分步調試,其運行方式與調試過程語言(例如 gdb 或 pdb)類似。
在開發 TensorFlow ML 模型時一類經常遇到的問題是,因溢出、除零、log(0) 等錯誤而導致出現無效數值(無窮大和 NaN)。在大型 TensorFlow 圖表中,查找此類節點的根源可能既繁瑣又耗時。借助于 tfdbg CLI 及其條件斷點支持,您可以快速找到引發問題的根源節點。
與打印選項等替代性調試選項相比,tfdbg 需要改動的代碼行數更少,提供的圖表覆蓋范圍更大,并且提供的調試體驗交互性更強。它可以加快您的模型開發速度和調試工作流執行速度。它還提供了其他功能,例如離線調試從服務器環境轉儲的張量并將其與 tf.contrib.learn 集成。首先,請訪問此文檔。這篇研究論文對 tfdbg 的設計做了更詳盡的展示。
使用 tfdbg 時要求安裝的*** TensorFlow 版本為 0.12.1。要報告錯誤,請在 TensorFlow 的 GitHub 問題頁面上設立問題。如需獲得一般使用幫助,請在 StackOverflow 上使用 tensorflow 標記發帖提問。
【本文是51CTO專欄機構“谷歌開發者”的原創稿件,轉載請聯系原作者(微信公眾號:Google_Developers)】












