













自動化機器學習將成為下一個AI研究主流?聽聽數(shù)據(jù)科學家怎么說
在過去的一年當中,自動化機器學習已經(jīng)成為一個眾人感興趣的話題。KDnuggets舉辦了一個關于該話題的博客大賽。結果喜人,有很多有意思的想法與項目被提出來了。一些自動化學習工具也引起了大家的興趣,受到了大家的追捧。
本篇文章的作者 Matthew Mayo 將會對自動化學習進行簡單的介紹,探討下一下它的合理性、采用情況,介紹下它現(xiàn)在使用的工具,討論下它預期的未來發(fā)展方向。
什么是自動化機器學習呢?
接下來我們要探討的是自動化機器學習屬于哪一類科學,以及它不屬于哪一類科學。
自動化機器學習并不屬于自動化數(shù)據(jù)科學。毫無疑問的是它與自動化數(shù)據(jù)科學有重復的部分。盡管如此,機器學習只是數(shù)據(jù)科學工具包中的一個工具。它無法對所有的數(shù)據(jù)科學任務起作用。例如,機器學習雖然適用于預測性的數(shù)據(jù)科學任務。但它并不適用于描述性分析的數(shù)據(jù)科學任務。
即使是那些預測性的數(shù)據(jù)科學任務,也不僅僅只包含預測。我們對自動化機器學習與自動化數(shù)據(jù)科學會產(chǎn)生了混淆,對此,數(shù)據(jù)科學家Sandro Saitta認為:
這種誤解來源于我們對完整的數(shù)據(jù)科學過程(例如:CRISP-DM)、準備數(shù)據(jù)的子過程(特征提取等等)以及建模(建模也被我們我們稱為機器學習)的混淆。
在讀到關于自動化數(shù)據(jù)科學與數(shù)據(jù)科學競賽的工具新聞的時候,沒有行業(yè)經(jīng)驗的人會很困惑,他們可能認為數(shù)據(jù)科學就是建模,這樣就可以完全自動化運行了。
他是完全正確的,不僅僅是詞義的問題。假如你想要對機器學習與數(shù)據(jù)科學有一個更加清晰的認識,那就讀讀這個。
此外,數(shù)據(jù)科學家、自動化機器學習的領軍人物Randy Olson認為我們要想得到高效的機器學習設計方案,我們必須做到以下幾點:
- 始終調整我們模型的超參數(shù)
- 始終嘗試不同的模型
- 始終對我們的數(shù)據(jù)進行大量的特征探索
假如我們將以上所說的東西都考慮進去,那么我們可以認為自動化機器學習的任務是選擇算法、超參調整、迭代建模以及模型評價,這樣的話,我們就可以以此來定義自動化機器學習了。自動化機器學習的定義是多種多樣的(對比一下數(shù)據(jù)科學,當你向十個人詢問什么是數(shù)據(jù)科學的時候,你會得到是十一種不同的回答。),但是我們卻可以說,這開了個好頭兒。
我們?yōu)槭裁葱枰?/strong>
盡管我們知道了自動化機器學習的概念,自動化機器學習對我們可能有好處,但是我們仍需要知道為什么機器學習會很難。
AI研究人員、斯坦福大學博士生S. Zayd Enam最近寫了一篇奇特的博客,博客的標題是《為什么機器學習這么“硬”?》,在這篇文章中,他寫道(注意粗體字):
機器學習仍然是相對很困難的問題。毫無疑問,通過研究來推進機器學習算法的進步會很困難。這需要創(chuàng)造力、實驗以及堅持。 由于現(xiàn)成的算法、模型可以很好的為你提供服務,這就阻礙了機器學習的發(fā)展。
請注意,盡管Enam主要提及的是機器學習的研究,但是他也提到了現(xiàn)成的算法在用例中的實現(xiàn)(見粗體字)。
緊接著Enam詳細闡述了機器學習的難題,并著重敘述了算法的特性(見粗體字):
機器學習的難題之一就是建立直覺。建立直覺的意思是采用某種工具來應對問題。 這就需要知道可用的算法、模型、風險權衡以及每一個限制條件。
……
困難在于機器學習基本上很難進行調試。對于機器學習來說,調試會在兩種情況下發(fā)生:1)你的算法不起作用了;2)你的算法效用不是很好。…… 算法一開始就起作用的情況很少,因此我們大部分時間都在用來創(chuàng)建算法。
Enam緊接著從算法研究層面闡述了框架問題。再次強調下,他所說的是應用算法。假如一個算法不起作用,或者性能不是很好,那么我們就需要對算法進行迭代,即再選擇與再定義。這就產(chǎn)生了自動化,因此也就有了自動化算法。
我以前對于自動化機器學習算法本質的理解是這樣的:
正如Sebastian Raschka描述的那樣,假如說計算機程序關于自動化的,那么機器學習可以看做是“關于自動化的自動化”。那么自動化機器學習就是關于自動化的自動化的自動化。程序通過管理重復的任務來減輕我們的壓力;機器學習幫助計算機如何***的處理這些重復的任務;自動化機器學習幫助計算機學習如何優(yōu)化上面的結果。
這種思想很有用處;盡管我們之前會擔心調參數(shù)、調超參數(shù)。自動化機器學習通過嘗試一些列不同的方法,最終會采用***的方式來調參,從而得到***的結果。
自動化機器學的理論基礎來源于這個想法:假如我們必須創(chuàng)建海量的機器學習模型、使用大量的算法、使用不同的超參數(shù)配置,那么我們就可以使用自動化的方式進行建模。同時也可以比較性能與準確度。
很簡單,對不對?
對自動化機器學習工具進行比較
現(xiàn)在我們知道了自動化機器學習到底是什么了,以及我們要用它的原因。那我們我們該如何才能創(chuàng)造出一個自動化機器學習模型來?接下來要講解的是兩個自動機器學習工具包的概述,以及二者之間比較。這些工具包是使用python編寫而成的。這兩個工具使用不同的方式來達到相同的目的,也就是是機器學習過程的自動化。
Auto-sklearn
Auto-sklearn是自動化機器學習的工具包,我們用它來替換scikit-learn中的estimator。在最近由KDnuggets舉辦的機器學習博客大賽中,它取得了冠軍頭銜。
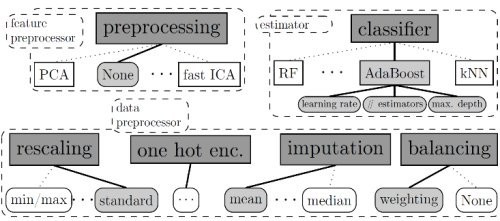
auto-sklearn使機器學習的使用者可以很輕松的進行算法選擇以及超參數(shù)的調整。它的優(yōu)勢就是在于使用貝葉斯優(yōu)化、元數(shù)據(jù)學習以及集合建設。要想了解更多關于auto-sklearn的背后技術,你可以閱讀這篇2015年發(fā)表在NIPS論文。
上面的信息是摘自項目的文檔說明,Auto-sklearn可以通過貝葉斯優(yōu)化方式將超參數(shù)***化,就是通過不斷迭代以下幾個步驟:
- 創(chuàng)建一個概率模型,來找到超參數(shù)設置與機器學習的表現(xiàn)之間的關系
- 使用這個模型來挑選出有用的超參數(shù)設置,通過權衡探索與開發(fā),進而繼續(xù)嘗試。探索指的是探索模型的未知領域;開發(fā)指的是重點從已知的空間中找到表現(xiàn)良好的部分。
- 設置好超參數(shù),然后運行機器學習算法。
下面將進一步闡明這個過程是如何進行的:
這個過程可以概括為聯(lián)合選擇算法、預處理方法以及超參數(shù)。具體如下:分類/回歸的選擇、預處理方法是***優(yōu)先級、分類超參數(shù)、被選擇方法的超參數(shù)會被激活。我們將使用貝葉斯優(yōu)化方法來搜索組合空間。貝葉斯優(yōu)化方法適用于處理高維條件空間。我們使用SMAC,SMAC是的基礎是隨機森林,它是解決這類問題的***方式。
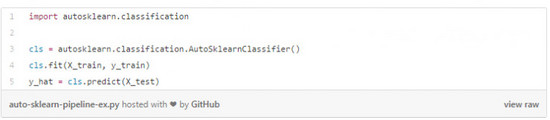
就實用性而言,由于Auto-sklearn直接替代scikit-learn的estimator,因此scikt-learn需要安裝這個功能,我們才能利用到這個優(yōu)勢。Auto-sklearn同樣也支持在分布式文件系統(tǒng)中進行并行計算,同時它也可以利用scikit-learn模型的持續(xù)特性。要想高效的使用Auto-sklearn替代estimator只需要4行代碼就可以了。作者這樣寫道:
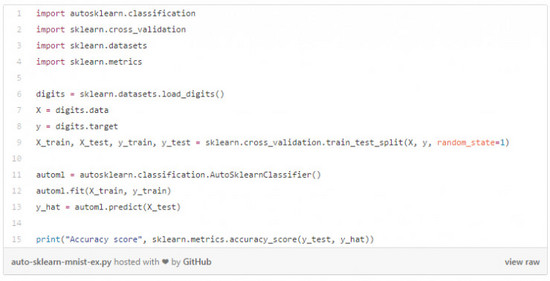
有一個更具魯棒性的示例(該示例使用了Auto-sklearn,并以MNIST數(shù)據(jù)集作為數(shù)據(jù)來源),如下:
需要注意的是,Auto-sklearn是ChaLearn AutoML challenge競賽中,auto單元與tweakathon tracks單元的雙料冠軍。
最近Kdnuggets舉辦了自動化數(shù)據(jù)科學與機器學習博客大賽,Auto-sklearn研發(fā)團隊提交的一篇博文在本次大賽中獲獎,你可以 點擊這里 進行閱讀,同樣也可以 點擊這里 來閱讀對他們的的采訪。Auto-sklearn是由Freiburg大學研發(fā)出來的。
Auto-sklearn已經(jīng)被托管到GitHub上了,你可以找到相關文檔以及API。
TPOT
TPOT被認為是“你的數(shù)據(jù)科學助手”(要注意,不是“你的數(shù)據(jù)科學替代品”)。它是一個Python的工具。通過使用“遺傳編程來自動的創(chuàng)建與優(yōu)化機器學習管道”。TPOT與Auto-sklearn類似,與scikit-learn協(xié)同工作。就像是scikit-learn的包裝器。
在本文中,我們曾提到過,這兩個工具使用不同的方式,達到相似的目標。二者都是開源的,都是使用python編寫而成的,都宣稱通過使用自動化機器學習的方式簡化了機器學習的過程。然而Auto-sklearn使用的是貝葉斯優(yōu)化,TPOT使用的卻是遺傳編程。
盡管兩者使用的方法不同,但是二者的最終結果卻是相同的:自動化超參數(shù)選擇,用一系列算進行建模,對大量特征的探索,這些都導致了迭代建模以及模型進化。
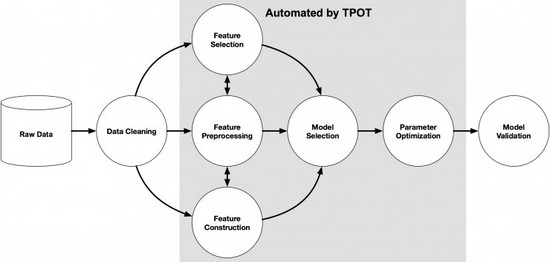
TPOT的真正好處之一就是使用scikit-learn的管道,產(chǎn)生可以準備運行的、獨立的Python代碼。這個代碼代表著所有備選模型中表現(xiàn)***的模型。我們就可以修改與審查這份代碼。這份代碼并不會是最終的模型,而是可以當做是我們尋找***模型的有效起點。
下面是一個關于TPOT的例子,該案例使用MNIST數(shù)據(jù)集:
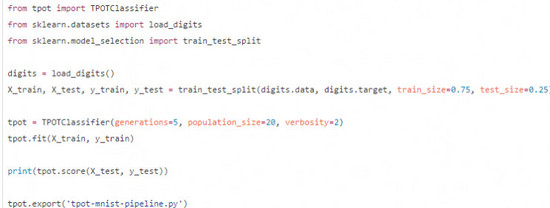
這次運行的結果正確率達到了98%,同時pyhton代碼也就是我們所說的管道也會被導入到tpot-mnist-pipeline.py文件當中,如下所示:
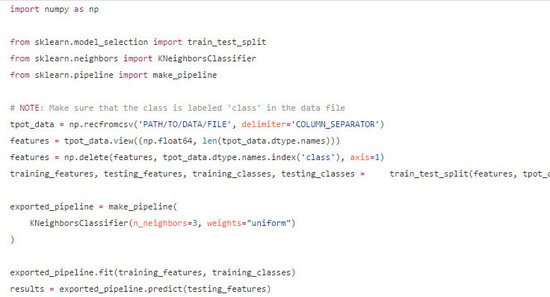
我們可以 在GitHub上找到TPOT的源代碼 ,以及說明文檔。
TPOT的領軍人物Randy Olson在Kdnuggets上寫過一篇關于TPOT 與AutoML(自動化機器學習)的文章,你可以 點擊這里 找到該文章。也會在這里找到對Randy的采訪。
TPOT是由賓夕法尼亞大學生物醫(yī)學信息學研究所研究出來的,由NIH資助。
當然,自動化機器學習不僅僅只有這兩個工具。還有其他的工具,像Hyperopt (Hyperopt-sklearn)、 Auto-WEKA,以及Spearmint等等。我打賭在未來幾年,大量相關的額外項目將會出現(xiàn),這些項目中既會包含研究項目,也會包含工業(yè)項目。
自動化機器學習的未來
自動化機器學習的未來在哪里?
我最近公開地進行過以下陳述(根據(jù)我的文章《2017年機器學習預測》):
自動化機器學習將變成重要的技術。在外人看來,它可能不如深度神經(jīng)網(wǎng)絡。但是自動化機器學習對于機器學習、人工智能以及數(shù)據(jù)科學都產(chǎn)生了深遠的影響。這種影響極有可能在2017年顯示出來。
在同一篇文章當中,Randy Olson也表達了在2017年他對自動化機器學習的期望。此外Randy在最近的采訪中有更加詳細地闡述了他的預測:
在不久的將來,我認為自動化機器學習將會替代機器學習的建模過程:一旦數(shù)據(jù)集擁有相對清晰的格式,那么自動化機器學習將會比99%的人類更快地設計與優(yōu)化機器學習管道。
……
我可以很確定地認為自動化機器學習系統(tǒng)將會成為機器學習的主流。
但是自動化機器學習是否會替代數(shù)據(jù)科學家?Randy繼續(xù)說道:
我并不認為自動化機器學習的目標是為了替代數(shù)據(jù)科學家,就像是智能代碼自動完成工具的目標并不是來替代程序員一樣。相反,對于我來說,自動化機器學習的的目標是為了減輕數(shù)據(jù)科學家的壓力,使他們不必將大量的精力耗費在重復與耗時的任務上(比如說機器學習的管道設計與超參數(shù)的***化)。這樣他們就可以將時間投入到無法進行自動化的任務當中去。
這種思想十分好。auto-sklearn的開發(fā)人員也同樣認同他的觀點:
我們發(fā)展自動化機器學習方法是為了向數(shù)據(jù)科學家提供幫助,而不是代替他們。這些方法使數(shù)據(jù)科學家擺脫了討厭復雜的任務(比如說超參數(shù)優(yōu)化),機器可以很好地解決這些任務。然而數(shù)據(jù)分析與結論獲取的工作仍然需要人類專家來完成。在未來,理解應用程序領域的數(shù)據(jù)科學家仍然極其的重要。
這聽起來十分的鼓舞人心:數(shù)據(jù)科學家不會被大量替換,自動化機器學習是為了幫助他們更好的工作。這并不是說自動化機器學習已經(jīng)很***了。在我們提到自動機器學習是否還有進步空間的時候,Auto-sklearn團隊如是說:
盡管有一些方法可以用來調試機器學習管道的超參數(shù),但是目前為止很少有工作能發(fā)現(xiàn)新管道。Auto-sklearn以固定的順序使用一系列的預定義的預處理器與分類器。假如一個方法對于找到新管道很有效,那么這個方法將會很有用處。當然,人們可以繼續(xù)這種思路,并嘗試自動尋找新的算法。最近,已經(jīng)有幾篇論文這樣做了。比如說Learning to learn by gradient descent by gradient descent.(雷鋒網(wǎng)此前也有提及這篇論文,它獲得了RedditML小組評選的“年度***論文標題獎”)
自動化機器學習的發(fā)展方向在哪里?很難說清楚。毋庸置疑的是,遲早會出現(xiàn)。盡管不是所有的數(shù)據(jù)科學家都熟知自動化機器學習,但是熟知自動化機器學習將會使你獲益匪淺。別忘了,假如你能夠在大多數(shù)人意識到之前就去學習自動化機器學習,駕馭科技浪潮,你就不會因未來的不確定性而擔心你的工作了。你對于這些技術的駕馭利用將會幫助你在未來更好的工作。而我也再想不出比這個更好的理由來學習自動化機器學習了。
















