資本布局的人工智能其實是人工智障?3分鐘看懂啥叫機器學習
本文長度為2300字,建議閱讀3分鐘
好奇寶寶想知道人工智能的機器學習究竟是怎么學習的?本文用漫畫讓你看懂人工智能內部的工作原理。
最近,富士康放出話來,它的工廠夜間已經不需要開燈了——因為一個工人都不需要,干活的全是人工智能機器。
幾乎所有大佬都在談論人工智能。

似乎這個世界再也不需要人類了。

你可能聽了一百遍人工智能,不過到底人工智能是個什么鬼,所謂人工智能的機器學習究竟是怎么學習的?它和你之前玩過的小霸王游戲機究竟有什么區別?
今天,我們用漫畫
來直接讓你看懂
人工智能內部的工作原理
▼
我們所舉的例子是機器學習中的有監督學習。
人工智能機器學習分為有監督學習,無監督學習,強化學習和蒙特卡洛樹等。這一句你看不懂完全可以忽略,因為不影響下面的解釋。
我就是傳說中的大boss,人工智能!怕了吧!

其實,人工智能基本等于人工智障!人類一目了然的事情,它得算半天,而且未必能搞定。

首先,我們來說說,人工智能和傳統計算機原理之間的關系。
最傳統的計算機,就是這玩意——
它的工作原理就是有一個確定的輸入,就有一個確定的輸出。
對于機器,原理也一樣。比如這個

但人類,被輸入一個刺激后,其實是往往這樣的
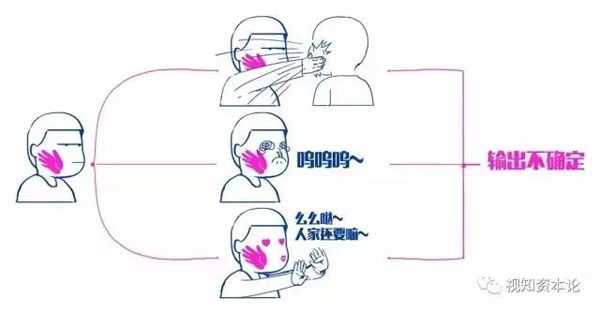
在現實世界中,我們看到女朋友的臉,無論她化了什么樣的妝,你一眼就能認出來。
但傳統計算機的單一輸入值,單一確定輸出的模式,就傻眼了。

但怎么讓機器模仿出人的輸入輸出能力,有類似人類的智能。這就是人工智能問題的核心。
其實,要做的就是對復雜的輸入信號進行分解計算,對計算中的不同因子進行不同的處理,無論輸入的有怎樣變化,都能做出大致合理的輸出。
用專業的說法,就是在輸入輸出之間的隱藏層進行一系列權重調整,建立一個模型。
這樣無論人臉加上什么偽裝,只要落在一個范圍內,機器都能認出這張臉。

這時候,機器就變得像人一樣能認人了,就成了人工智能。
▼
看到這兒,其實你就比百分九十以上的人更了解人工智能了。但人工智能怎么具體調整權重,我們可以講個機器人按臉殺人的故事。
***步先要讓機器可以認出人臉。

所以我們要拿很多包含人臉的圖片喂給它:

臉上不同的部位分別被抽象為一組數字,比如鼻子可以極度簡化為為長度和寬度兩個數據

然后發送給程序去處理——人工神經網絡現在特別流行,我們就用它好了。這些數字的流動,的確有點像人類腦神經的工作方式:
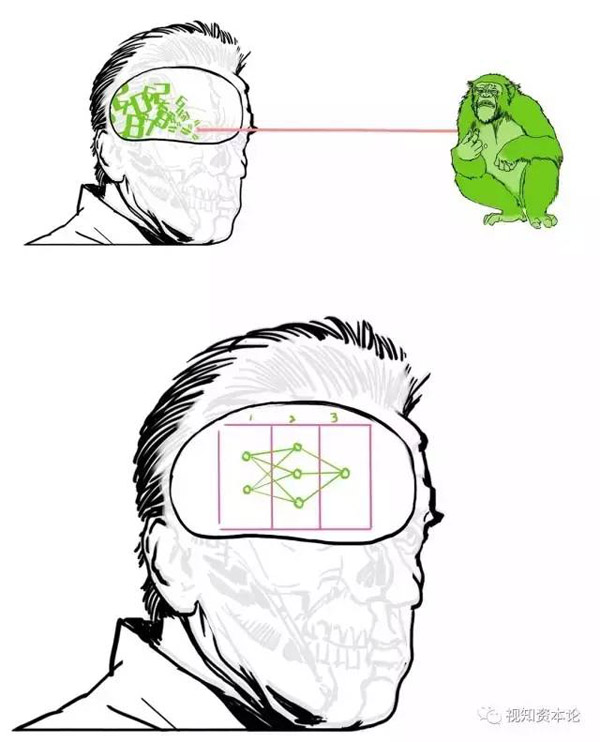
這個圖看起來不知所謂,其實特別簡單,就是挨個把輸入的數字乘以那些系數,***加起來。
對,這些系數就是所謂的“權重”。
輸出層輸出的就是一個普通的數字。我們給他設定一個閾值,比如20;把牙齒,鼻子和眼睛都算出來,等于28,大于20,就判定輸入的是人臉。

這差不多是一種很原始的人工神經網絡,叫做感知機。
不過現在的神經網絡會引入一種叫做激活函數的東西,把這種一刀切的智障變成一個稍稍聰明一點的樣子:
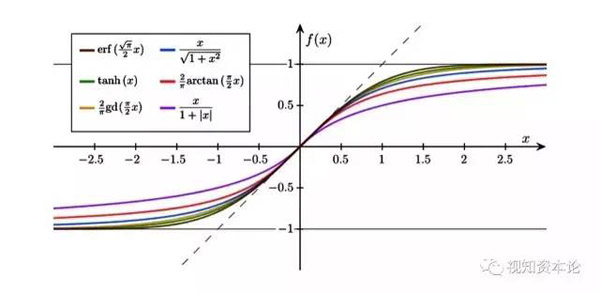
這個圖像有什么意義呢?
就是把一個簡單到***的“是不是”的問題,轉化為有“百分之多少”的概率問題。看上去是不是智能了不少?

同時,聰明的你一定發現了,決定成效的關鍵其實就是那些“權重”。
怎么獲得恰當的權重組合?
這就是機器學習的意義:讓機器自己根據每一次考試的結果去修正自己的權重。
慢著,它自己怎么知道對錯?

這還是要人類事先給這些照片進行分類:哪些是人,哪些是狗,哪些是ET……
這就好像人類在給他出有標準答案的考試,所以叫做“有監督學習”。

然后我們只要不斷重復這個過程,權重就會逐漸調整到更恰當的組合,輸出結果就會越來好,判斷越來越準。
如此不斷重復同一過程,達到改進的方式,就叫做“迭代”。

只要我們的神經網絡設計的沒問題,最終,就可以準確識別出人類。

現在***進的算法,已經可以達到各種狀況下98%以上的正確率了!

這整個過程就叫做“訓練”。
我們用來訓練它的圖片和每張圖片對應的標簽,就叫做“訓練集”。
▼
一般介紹人工智能文章到這里就不會再往深里說了,如果繼續往下看,你對人工智能的了解就會遠遠99.99%的人類。
所以,你做好準備成為磚家了嗎?
首先,大家***奇的應該是:程序到底怎么調整權重的?

這個被稱作“反向傳播”的過程是這樣的:在每一次訓練中,我們都要確定程序給出的結論錯的有多遠。
我們已經說過,程序的猜測和答案都可以轉化為數值

把所有的錯的平方都加起來,再平均一下,就得到一個“損失函數”。
損失函數當然越小越好,這代表我們的神經網絡更厲害。
我們一開始可能在山頂,這意味著“損失”特別大,所以我們要盡快下山止損。

怎么做呢?一種最常用的也很有效的辦法就是,永遠選擇最陡的路線,這樣很容易就會到達某個山谷。
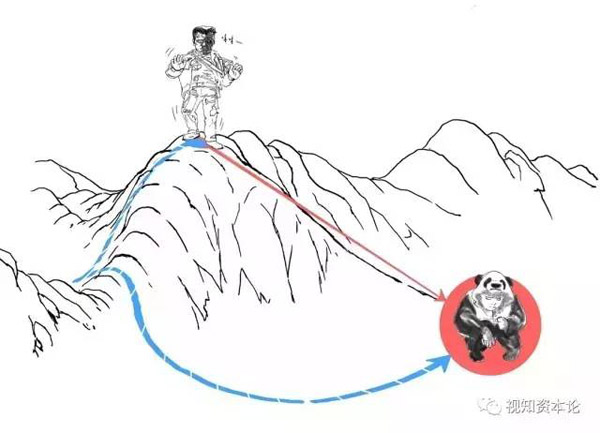
當損失函數達到某個最小值,不怎么變化了,就說明訓練差不多了。這種方法就被叫做“梯度下降”。
具體而言,其實就是求導數:

看到這個公式有沒有一點想崩潰的感覺?

如果還沒有徹底崩潰,就稍微解釋一下吧:
這個式子的意思就是,把某個權重減少這么多,損失函數對相應權重的偏導數乘以α。
至于怎么求這個偏導數的數值……你確定你真的想知道?

而這個α呢,也很重要,叫做“學習速率”。
它的意思是:發現錯誤之后,改變的幅度太大或太小都不好。比如學開車,轉彎
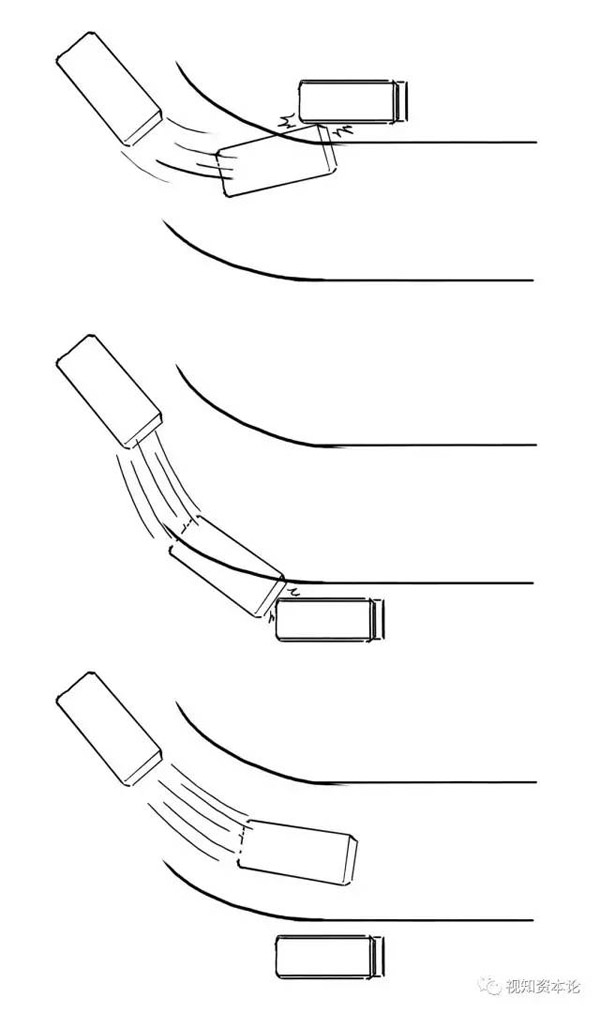
至于改的幅度(系數)多大***,這就要靠悟了。

▼
好吧,說了這么難的東西,再來點八卦吧。
為啥要讓人工智能殺那么多猩猩、海豚、蜥蜴?
因為如果沒有這些負樣本,人工智能隨手一抓都是對的。

這樣,就不存在學習和積累經驗(調整權重)的過程,也不會有在現實世界中真正找到人臉的能力。
不要被那些所謂人工智能專家神神鬼鬼的術語所迷惑,其實人工神經網絡的有監督學習的整個過程,無非就是在做自動化的回歸分析罷了。
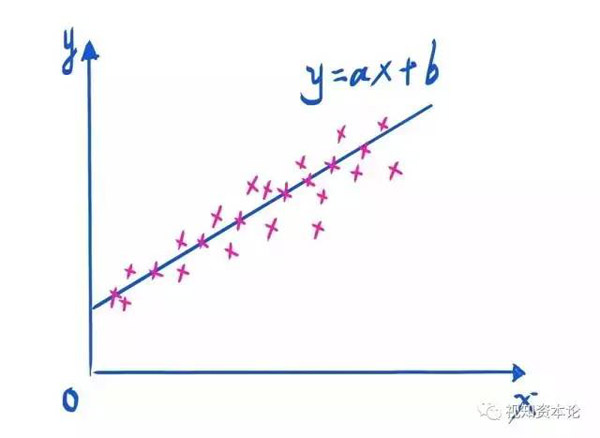
從最簡單的一元線性回歸到多元非線性回歸,就是越來越看起來越來越智能的過程。人工智能的專家也是這么循序漸進掌握機器學習的。
▼
***,如果你能堅持到這里...
恭喜,你已經成為半個機器學習的專家了!
如果大家喜歡,我們下次再來講講其他人工智能的技術,比如無監督學習、強化學習!
參考資料:
- 斯坦福大學公開課:《機器學習》
- FaceNet: A Unified Embedding for Face Recognition and Clustering, Florian Schroff,Dmitry Kalenichenko,James Philbin,Google Inc.
- Efficient BackProp, Yann LeCun,Leo Bottou
- 《人工智能時代》,杰瑞·卡普蘭
- 《心靈、語言和社會》,約翰·塞爾