Hadoop平臺(tái)中SQL優(yōu)化的四個(gè)思路
要正確的優(yōu)化SQL,必須能快速定位性能瓶頸點(diǎn),或者說快速找到SQL主要的開銷所在。最慢的設(shè)備通常是瓶頸點(diǎn)的成因,如文件下載時(shí)的瓶頸點(diǎn)可能是網(wǎng)絡(luò)速度,本地文件復(fù)制時(shí)的瓶頸點(diǎn)可能在于硬盤性能。
為了快速找到SQL的性能瓶頸點(diǎn),首先需要讀者對(duì)各種設(shè)備的性能數(shù)據(jù)有一些基本的認(rèn)識(shí),如千兆網(wǎng)絡(luò)帶寬是1000Mbps,硬盤轉(zhuǎn)速為每分鐘7200/10000轉(zhuǎn)等。
下圖數(shù)據(jù)給出了一些當(dāng)前主流的計(jì)算機(jī)性能指標(biāo)。
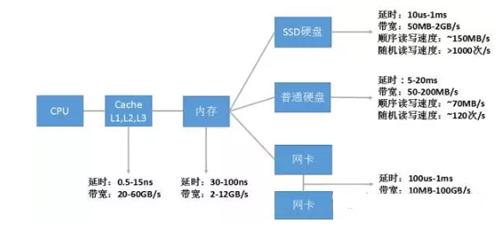
圖1 I/O各層次硬件性能匯總
如上圖所示,每種設(shè)備基本上都有兩個(gè)重要指標(biāo):
- 延時(shí)(響應(yīng)時(shí)間):反映硬件的突發(fā)處理能力。
- 帶寬(吞吐量):反映硬件持續(xù)處理能力。
通過比較這兩種指標(biāo),可以發(fā)現(xiàn)計(jì)算機(jī)各系統(tǒng)硬件性能從高到低依次為:CPU→Cache(L1-L2-L3)→內(nèi)存→SSD硬盤→網(wǎng)絡(luò)→硬盤。
比較性能之后,我們?cè)倏匆幌旅糠N硬件在Hadoop系統(tǒng)進(jìn)行SQL運(yùn)算時(shí)負(fù)責(zé)的主要工作:
CPU及內(nèi)存:緩存數(shù)據(jù)訪問、比較、排序、事務(wù)檢測(cè)、SQL解析、函數(shù)或邏輯運(yùn)算、JOIN、數(shù)據(jù)加解密、加解壓等;
網(wǎng)絡(luò):結(jié)果或者Shuffle數(shù)據(jù)的傳輸、SQL請(qǐng)求、遠(yuǎn)程數(shù)據(jù)訪問等;
硬盤:數(shù)據(jù)訪問、數(shù)據(jù)寫入、日志記錄、外排序、Shuffle等。
將以上陳列的各硬件性能指標(biāo)及其工作內(nèi)容結(jié)合考慮,在Hadoop集群中提升SQL的執(zhí)行性能就是要盡量做到以下四點(diǎn):
- 減少數(shù)據(jù)訪問(減少磁盤訪問)
- 減少中間結(jié)果量(減少網(wǎng)絡(luò)傳輸或磁盤訪問)
- 減少交互次數(shù)(減少網(wǎng)絡(luò)傳輸、減少調(diào)度開銷)
- 改進(jìn)算法,減少服務(wù)器CPU開銷(減少CPU及內(nèi)存開銷)
注:實(shí)際優(yōu)化時(shí),除了以上四點(diǎn)還應(yīng)注意任務(wù)分配要均勻且大小適中。
總而言之,優(yōu)化的基本思想就是反復(fù)迭代,合理利用資源,綜合平衡各種開銷,以求達(dá)到***效果。下面將簡(jiǎn)單介紹這四種優(yōu)化思路,以及分別可采用的方法。
1. 減少數(shù)據(jù)訪問
傳統(tǒng)關(guān)系型數(shù)據(jù)庫(kù)例如MySQL、Oracle等,通常通過提供索引來實(shí)現(xiàn)減少數(shù)據(jù)訪問、提升訪問速度,但是由于Hadoop不維護(hù)鍵(Key)的特性,因而SQL on Hadoop引擎一般不提供對(duì)傳統(tǒng)索引的支持,或者功能不像傳統(tǒng)索引一樣完備。
為了達(dá)到和索引相似的優(yōu)化目的,即加快過濾掃描,SQL on Hadoop產(chǎn)品通常提供其他功能用以彌補(bǔ)。以星環(huán)科技的Inceptor為例,其本身并沒有可用于控制的傳統(tǒng)意義上的索引,但是提供了分區(qū)、分桶,以及MinMaxFilter、BloomFilter以及RowFilter等用于批量過濾數(shù)據(jù)的過濾器。這些功能的原理通常是通過把相似、相關(guān)或者相等的數(shù)據(jù)進(jìn)行歸類以減少查詢搜索的范圍,或者建立基于列式存儲(chǔ)的掃描方式盡可能的減少無關(guān)數(shù)據(jù)的讀取。使用者需要結(jié)合實(shí)際語(yǔ)句,把這些功能進(jìn)行高效組合,合理運(yùn)用在刀刃上。
2. 返回更少的數(shù)據(jù)
返回更少的數(shù)據(jù)就是要求在構(gòu)造SQL語(yǔ)句時(shí),只SELECT需要的列。因?yàn)槊總€(gè)字段的提取都是一個(gè)復(fù)雜的解析過程,且占用內(nèi)存,所以為了減少不必要的查詢時(shí)間,請(qǐng)讀者***僅返回需要的字段。比如減少“SELECT *”的使用,因?yàn)榇蠖鄶?shù)情況是不需要所有字段的數(shù)據(jù)的。
【例1】如果某用戶提交了這樣的語(yǔ)句,但是實(shí)際需要的只有id、name兩個(gè)字段:
- SELECT * FROM product WHERE company_id = 456723
- LIMIT 100;
為了加快執(zhí)行速度,建議將語(yǔ)句寫為:
- SELECT id, name FROM product
- WHERE company_id = 456723
- LIMIT 10;
另外若SELECT的結(jié)果是用于判斷某些條件是否成立,例如EXISTS操作,就更加沒必要返回所有數(shù)據(jù):
【例2】某個(gè)包含關(guān)聯(lián)的語(yǔ)句,在優(yōu)化調(diào)整前,EXISTS內(nèi)部返回了滿足條件的所有字段值:
- SELECT … FROM table_name_2 WHERE
- … EXISTS (
- SELECT * FROM table_name_1
- WHERE table_name_1.col1 = table_name_2.col1
- );
但是EXISTS的返回僅用于判斷滿足條件的記錄存在與否,所以EXISTS內(nèi)部無需返回所有字段。因此可以將EXISTS子句中的“SELECT *”優(yōu)化為“SELECT 1”:
- SELECT … FROM table_name_2 WHERE
- … EXISTS (
- SELECT 1 FROM table_name_1
- WHERE table_name_1.col1 = table_name_2.col1
- );
3. 減少交互次數(shù)
減少交互次數(shù)就是減少網(wǎng)絡(luò)通信的交互次數(shù)。這里分享與此相關(guān)的三種優(yōu)化情況。
Batch DML
批量方式處理DML可以大幅度減少和服務(wù)器的交互次數(shù)。Inceptor數(shù)據(jù)庫(kù)訪問框架提供了批量提交的接口以服務(wù)于大量插入數(shù)據(jù)。當(dāng)用戶一次性往一個(gè)表中插入1000萬(wàn)條數(shù)據(jù)時(shí),試想如果采用普通的Insert,將和服務(wù)器發(fā)生1000萬(wàn)次交互,按每秒鐘向數(shù)據(jù)庫(kù)服務(wù)器提交10000次估算,完成所有工作需要消耗1000秒。但是如果采用批量提交模式,每1000條提交一次,和服務(wù)器的交互次數(shù)就減少至1萬(wàn)次,交互次數(shù)大大減少,耗時(shí)縮短為原來的千分之一。
采用Batch操作雖然不會(huì)大量減少數(shù)據(jù)庫(kù)服務(wù)器的物理I/O,但是會(huì)大幅減少客戶端與服務(wù)端的交互次數(shù),從而降低多次發(fā)起的網(wǎng)絡(luò)延時(shí)開銷,以及數(shù)據(jù)庫(kù)的CPU開銷。
In List
進(jìn)行數(shù)據(jù)掃描時(shí),有時(shí)會(huì)遇到這樣的情況:到手多個(gè)ID,需要查詢與這些ID相關(guān)的記錄。有兩種方式實(shí)現(xiàn):?jiǎn)螚l提交或者批量提交。
單條處理就是采用一個(gè)ID發(fā)一個(gè)請(qǐng)求的方式傳送給數(shù)據(jù)庫(kù):
- for: var in ids[] do begin
- SELECT * FROM table_name WHERE id=:var;
- end;
這種方法會(huì)增加與服務(wù)器的交互次數(shù),顯然和減少交互次數(shù)的思想背道而馳,固然是不推薦的。建議用ID InList的方式批量提交,可以把多次交互壓縮在一次訪問中完成,加速查詢:
- SELECT * FROM table_name
- WHERE id IN ids[];
使用存儲(chǔ)過程
Inceptor支持存儲(chǔ)過程,合理的利用存儲(chǔ)過程有助于提高系統(tǒng)性能。存儲(chǔ)過程是由SQL語(yǔ)句組成的完成特定功能的代碼塊。每個(gè)代碼塊在創(chuàng)建時(shí)都需要命名,用戶通過訪問對(duì)應(yīng)名稱調(diào)用它們。存儲(chǔ)過程中的代碼都是已經(jīng)編譯過的,所以調(diào)用的時(shí)候可以跳過編譯階段直接執(zhí)行,而且由于其直接存儲(chǔ)在數(shù)據(jù)庫(kù)中,可以避免SQL語(yǔ)句的重復(fù)傳輸。
總體而言使用存儲(chǔ)過程有以下兩方面的好處:
減少編譯次數(shù)提高了執(zhí)行效率。
在網(wǎng)絡(luò)交互中代替了大量的SQL語(yǔ)句,使用者只需傳遞一些必要參數(shù),幫助減少網(wǎng)絡(luò)通信量,提升通信效率。
4. 減少數(shù)據(jù)庫(kù)服務(wù)器
CPU運(yùn)算SQL中會(huì)包含各種各樣的操作和計(jì)算要求CPU參與運(yùn)算,其中有一些計(jì)算并非必須,可以人為避免。例如,進(jìn)行對(duì)比運(yùn)算時(shí),對(duì)于不匹配的類型,系統(tǒng)要對(duì)操作數(shù)進(jìn)行類型轉(zhuǎn)換,導(dǎo)致加重CPU負(fù)擔(dān)。所以,對(duì)于數(shù)字和日期類型,建議用戶在執(zhí)行計(jì)算前先進(jìn)行類型轉(zhuǎn)換,使各操作數(shù)的類型匹配,或者建表時(shí)盡可能的把字段規(guī)劃成相同的數(shù)據(jù)類型。
另外,對(duì)于SQL中的邏輯運(yùn)算符,Inceptor通常對(duì)普通比較運(yùn)算符(如等于、不等)有較好的表現(xiàn),但是對(duì)于服務(wù)器CPU需求量很高的操作,需要用戶保持警惕。如LIKE操作,該模糊查詢對(duì)CPU的要求一般較高,特別是檢查的記錄有上萬(wàn)條及以上時(shí),系統(tǒng)表現(xiàn)比較糟糕。建議用戶根據(jù)業(yè)務(wù)語(yǔ)義盡量用In-List實(shí)現(xiàn)LIKE,在In-List中包含LIKE所有可能的匹配選項(xiàng)。
【例3】如下所示模糊查詢語(yǔ)句:
- SELECT * FROM table_name
- WHERE column_name LIKE ‘%abc%’;
若已知該列字段值僅有三種取值‘cabc’、‘abce’、‘cabe’,上面的語(yǔ)句可以等價(jià)為這樣的表達(dá)方式:
- SELECT * FROM table_name
- WHERE column_name IN (‘cabc’, ‘abce’, ‘cabe’);
【例4】如果In-List數(shù)據(jù)可用一條SELECT語(yǔ)句查詢得到,***讓一張中間小表作為In列表內(nèi)部數(shù)據(jù),然后采用內(nèi)外查詢關(guān)聯(lián)的方式進(jìn)行檢索:
- SELECT * FROM table_name
- WHERE column_name IN (
- SELECT col_name FROM tbl WHERE gender = ‘f’
- );
總結(jié)本文分享了四種在Hadoop平臺(tái)中常用的SQL優(yōu)化思路,實(shí)際上每種思路在具體應(yīng)用時(shí)都可以引申出很多不同的方法,介紹這些思路的目的在于為用戶在選擇SQL優(yōu)化手段時(shí)提供一些明確方向。
***大致總結(jié)一下這些優(yōu)化思路的適用場(chǎng)合:
- 在過濾掃描階段考慮如何減少數(shù)據(jù)訪問;
- 構(gòu)造SELECT子句時(shí)應(yīng)思考應(yīng)該如何減少返回?cái)?shù)據(jù);
- 當(dāng)執(zhí)行涉及向服務(wù)器發(fā)起交互請(qǐng)求的操作時(shí),應(yīng)當(dāng)選擇減少交互次數(shù)的合適方法;
- 必要時(shí)進(jìn)行人工處理以減少不必要的CPU計(jì)算。
如果用戶能夠考慮并兼顧這四個(gè)方面,相信由此構(gòu)造的SQL語(yǔ)句會(huì)在Hadoop平臺(tái)中有更好的執(zhí)行性能。