究竟啥才是互聯(lián)網(wǎng)架構“高可用”
一、什么是高可用
高可用HA(High Availability)是分布式系統(tǒng)架構設計中必須考慮的因素之一,它通常是指,通過設計減少系統(tǒng)不能提供服務的時間。
假設系統(tǒng)一直能夠提供服務,我們說系統(tǒng)的可用性是100%。
如果系統(tǒng)每運行100個時間單位,會有1個時間單位無法提供服務,我們說系統(tǒng)的可用性是99%。
很多公司的高可用目標是4個9,也就是99.99%,這就意味著,系統(tǒng)的年停機時間為8.76個小時。
百度的搜索首頁,是業(yè)內公認高可用保障非常出色的系統(tǒng),甚至人們會通過www.baidu.com 能不能訪問來判斷“網(wǎng)絡的連通性”,百度高可用的服務讓人留下啦“網(wǎng)絡通暢,百度就能訪問”,“百度打不開,應該是網(wǎng)絡連不上”的印象,這其實是對百度HA***的褒獎。
二、如何保障系統(tǒng)的高可用
我們都知道,單點是系統(tǒng)高可用的大敵,單點往往是系統(tǒng)高可用***的風險和敵人,應該盡量在系統(tǒng)設計的過程中避免單點。方法論上,高可用保證的原則是“集群化”,或者叫“冗余”:只有一個單點,掛了服務會受影響;如果有冗余備份,掛了還有其他backup能夠頂上。
保證系統(tǒng)高可用,架構設計的核心準則是:冗余。
有了冗余之后,還不夠,每次出現(xiàn)故障需要人工介入恢復勢必會增加系統(tǒng)的不可服務實踐。所以,又往往是通過“自動故障轉移”來實現(xiàn)系統(tǒng)的高可用。
接下來我們看下典型互聯(lián)網(wǎng)架構中,如何通過冗余+自動故障轉移來保證系統(tǒng)的高可用特性。
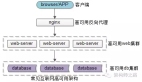
三、常見的互聯(lián)網(wǎng)分層架構
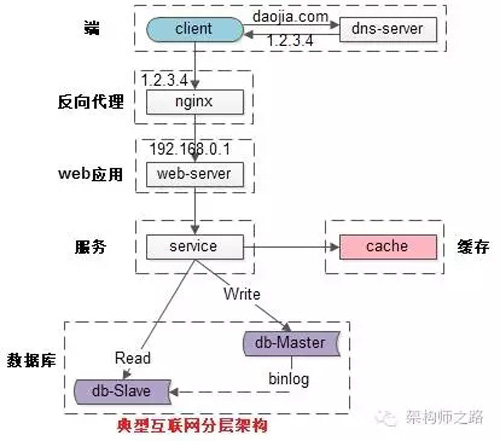
常見互聯(lián)網(wǎng)分布式架構如上,分為:
(1)客戶端層:典型調用方是瀏覽器browser或者手機應用APP
(2)反向代理層:系統(tǒng)入口,反向代理
(3)站點應用層:實現(xiàn)核心應用邏輯,返回html或者json
(4)服務層:如果實現(xiàn)了服務化,就有這一層
(5)數(shù)據(jù)-緩存層:緩存加速訪問存儲
(6)數(shù)據(jù)-數(shù)據(jù)庫層:數(shù)據(jù)庫固化數(shù)據(jù)存儲
整個系統(tǒng)的高可用,又是通過每一層的冗余+自動故障轉移來綜合實現(xiàn)的。
四、分層高可用架構實踐
【客戶端層->反向代理層】的高可用
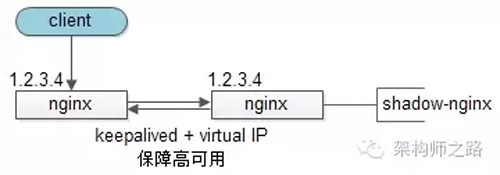
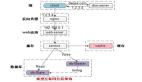
【客戶端層】到【反向代理層】的高可用,是通過反向代理層的冗余來實現(xiàn)的。以nginx為例:有兩臺nginx,一臺對線上提供服務,另一臺冗余以保證高可用,常見的實踐是keepalived存活探測,相同virtual IP提供服務。
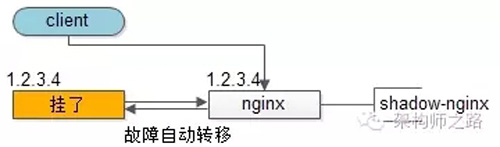
自動故障轉移:當nginx掛了的時候,keepalived能夠探測到,會自動的進行故障轉移,將流量自動遷移到shadow-nginx,由于使用的是相同的virtual IP,這個切換過程對調用方是透明的。
【反向代理層->站點層】的高可用
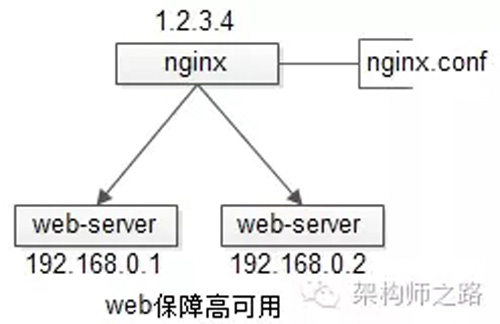
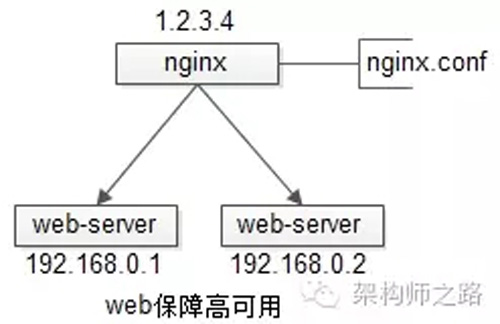
【反向代理層】到【站點層】的高可用,是通過站點層的冗余來實現(xiàn)的。假設反向代理層是nginx,nginx.conf里能夠配置多個web后端,并且nginx能夠探測到多個后端的存活性。
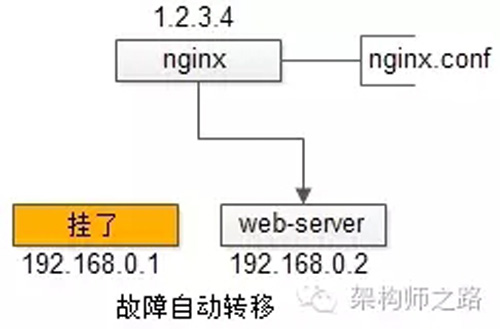
自動故障轉移:當web-server掛了的時候,nginx能夠探測到,會自動的進行故障轉移,將流量自動遷移到其他的web-server,整個過程由nginx自動完成,對調用方是透明的。
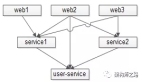
【站點層->服務層】的高可用
【站點層】到【服務層】的高可用,是通過服務層的冗余來實現(xiàn)的。“服務連接池”會建立與下游服務多個連接,每次請求會“隨機”選取連接來訪問下游服務。
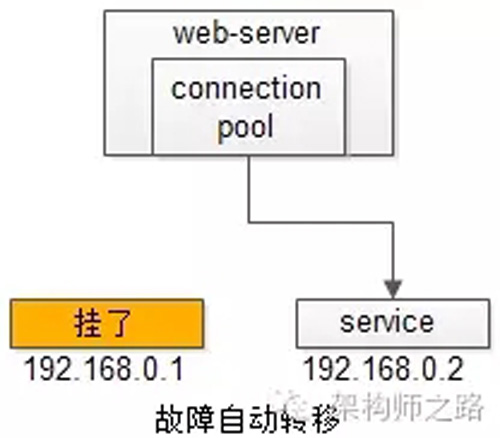
自動故障轉移:當service掛了的時候,service-connection-pool能夠探測到,會自動的進行故障轉移,將流量自動遷移到其他的service,整個過程由連接池自動完成,對調用方是透明的(所以說RPC-client中的服務連接池是很重要的基礎組件)。
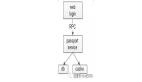
【服務層>緩存層】的高可用
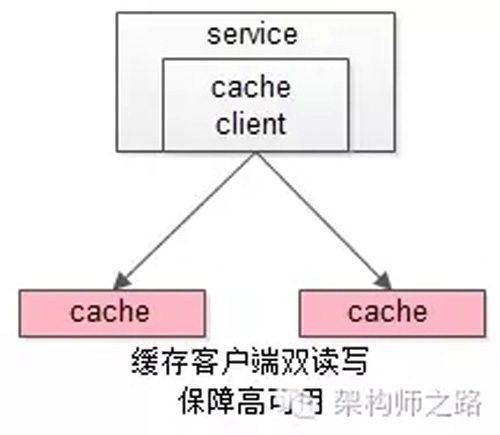
【服務層】到【緩存層】的高可用,是通過緩存數(shù)據(jù)的冗余來實現(xiàn)的。
緩存層的數(shù)據(jù)冗余又有幾種方式:***種是利用客戶端的封裝,service對cache進行雙讀或者雙寫。
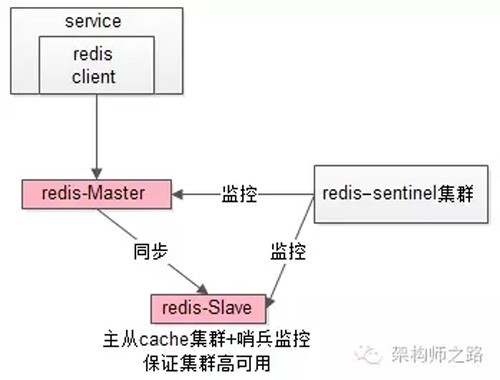
緩存層也可以通過支持主從同步的緩存集群來解決緩存層的高可用問題。
以redis為例,redis天然支持主從同步,redis官方也有sentinel哨兵機制,來做redis的存活性檢測。
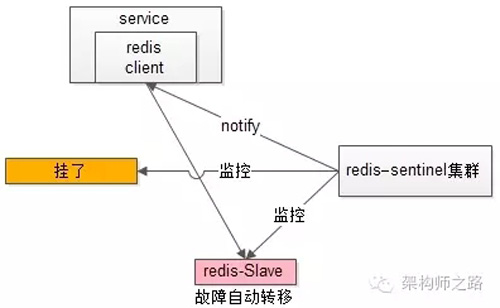
自動故障轉移:當redis主掛了的時候,sentinel能夠探測到,會通知調用方訪問新的redis,整個過程由sentinel和redis集群配合完成,對調用方是透明的。
說完緩存的高可用,這里要多說一句,業(yè)務對緩存并不一定有“高可用”要求,更多的對緩存的使用場景,是用來“加速數(shù)據(jù)訪問”:把一部分數(shù)據(jù)放到緩存里,如果緩存掛了或者緩存沒有***,是可以去后端的數(shù)據(jù)庫中再取數(shù)據(jù)的。
這類允許“cache miss”的業(yè)務場景,緩存架構的建議是:
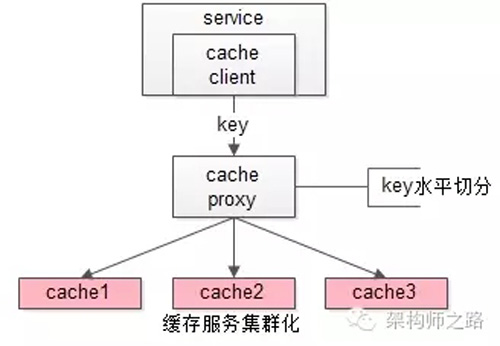
將kv緩存封裝成服務集群,上游設置一個代理(代理可以用集群冗余的方式保證高可用),代理的后端根據(jù)緩存訪問的key水平切分成若干個實例,每個實例的訪問并不做高可用。
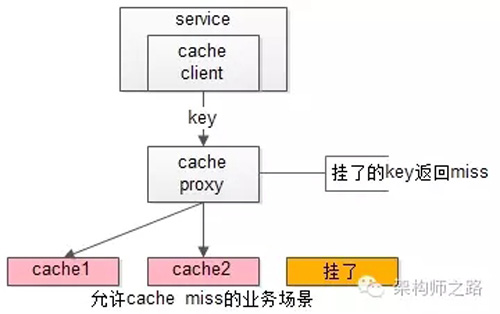
緩存實例掛了屏蔽:當有水平切分的實例掛掉時,代理層直接返回cache miss,此時緩存掛掉對調用方也是透明的。key水平切分實例減少,不建議做re-hash,這樣容易引發(fā)緩存數(shù)據(jù)的不一致。
【服務層>數(shù)據(jù)庫層】的高可用
大部分互聯(lián)網(wǎng)技術,數(shù)據(jù)庫層都用了“主從同步,讀寫分離”架構,所以數(shù)據(jù)庫層的高可用,又分為“讀庫高可用”與“寫庫高可用”兩類。
【服務層>數(shù)據(jù)庫層“讀”】的高可用

【服務層】到【數(shù)據(jù)庫讀】的高可用,是通過讀庫的冗余來實現(xiàn)的。
既然冗余了讀庫,一般來說就至少有2個從庫,“數(shù)據(jù)庫連接池”會建立與讀庫多個連接,每次請求會路由到這些讀庫。

自動故障轉移:當讀庫掛了的時候,db-connection-pool能夠探測到,會自動的進行故障轉移,將流量自動遷移到其他的讀庫,整個過程由連接池自動完成,對調用方是透明的(所以說DAO中的數(shù)據(jù)庫連接池是很重要的基礎組件)。
【服務層>數(shù)據(jù)庫層“寫”】的高可用
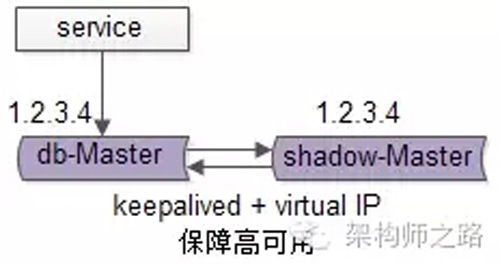
【服務層】到【數(shù)據(jù)庫寫】的高可用,是通過寫庫的冗余來實現(xiàn)的。
以mysql為例,可以設置兩個mysql雙主同步,一臺對線上提供服務,另一臺冗余以保證高可用,常見的實踐是keepalived存活探測,相同virtual IP提供服務。
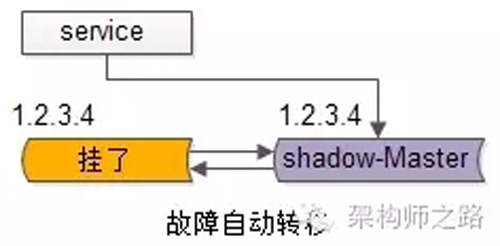
自動故障轉移:當寫庫掛了的時候,keepalived能夠探測到,會自動的進行故障轉移,將流量自動遷移到shadow-db-master,由于使用的是相同的virtual IP,這個切換過程對調用方是透明的。
五、總結
高可用HA(High Availability)是分布式系統(tǒng)架構設計中必須考慮的因素之一,它通常是指,通過設計減少系統(tǒng)不能提供服務的時間。
方法論上,高可用是通過冗余+自動故障轉移來實現(xiàn)的。
整個互聯(lián)網(wǎng)分層系統(tǒng)架構的高可用,又是通過每一層的冗余+自動故障轉移來綜合實現(xiàn)的,具體的:
(1)【客戶端層】到【反向代理層】的高可用,是通過反向代理層的冗余實現(xiàn)的,常見實踐是keepalived + virtual IP自動故障轉移
(2)【反向代理層】到【站點層】的高可用,是通過站點層的冗余實現(xiàn)的,常見實踐是nginx與web-server之間的存活性探測與自動故障轉移
(3)【站點層】到【服務層】的高可用,是通過服務層的冗余實現(xiàn)的,常見實踐是通過service-connection-pool來保證自動故障轉移
(4)【服務層】到【緩存層】的高可用,是通過緩存數(shù)據(jù)的冗余實現(xiàn)的,常見實踐是緩存客戶端雙讀雙寫,或者利用緩存集群的主從數(shù)據(jù)同步與sentinel保活與自動故障轉移;更多的業(yè)務場景,對緩存沒有高可用要求,可以使用緩存服務化來對調用方屏蔽底層復雜性
(5)【服務層】到【數(shù)據(jù)庫“讀”】的高可用,是通過讀庫的冗余實現(xiàn)的,常見實踐是通過db-connection-pool來保證自動故障轉移
(6)【服務層】到【數(shù)據(jù)庫“寫”】的高可用,是通過寫庫的冗余實現(xiàn)的,常見實踐是keepalived + virtual IP自動故障轉移
前段時間,受@謝工 邀請,在GitChat平臺首發(fā)《究竟啥才是互聯(lián)網(wǎng)架構“高可用”》。
12月01日周四晚8點30分,在微信群進行了針對該文章的的主題交流。以下是主持人@赫陽 整理的問題精華,記錄下了我和讀者之間關于高可用架構的問答精彩片段。
問答中所有文章都是可以直接點擊跳轉的喲。
問:在緩存層rehash過程中必然會有臟數(shù)據(jù)。一致性hash實際上只能減少rehash的成本,不能消滅臟數(shù)據(jù),這種臟數(shù)據(jù)有沒有辦法避免?
答:如文章《究竟啥才是互聯(lián)網(wǎng)架構“高可用”》所述,如果沒有高可用需求,一臺 cache 掛了,不宜做rehash,會產生臟數(shù)據(jù)。此時對掛掉cache的key可以直接返回 cache miss。
問:從您后面的回答來看,這其實也是“降級”的一種,這樣以后是直接把請求打到后端的數(shù)據(jù)庫上么?還是直接拋棄請求?如果發(fā)生雪崩效應,miss的請求越來越多,如果miss的都打庫的話,庫馬上就會掛了。這一塊老師能再展開講一講么?
答:打到數(shù)據(jù)庫上,cache集群的份數(shù)和數(shù)據(jù)庫能抗多少讀有關。理論上1-2份掛掉,數(shù)據(jù)庫能抗住。58的做法,有一個 backup mc集群,有掛了可以頂上,不建議rehash。高可用的代價是冗余,冗余有成本和復雜性,一致性問題 cache 我文章中***那種 cache 服務集群化,是比較好的方案(配上backup 集群)。
問:服務層到數(shù)據(jù)層,如果寫是通過冗余寫入保證高可用,那么根據(jù)CAP, 一致性很大可能上是不能保證的。 如何能保證基本一致性的情況的下,保證數(shù)據(jù)層的高可用?
答:根據(jù)CAP理論,一般來說,一致性和可用性取其一,其實最終一致就行。保證了高可用,得犧牲一些一致性,以主從數(shù)據(jù)庫為例,可能在主從數(shù)據(jù)同步時間窗口內,會從從庫讀到舊數(shù)據(jù)。
問:你對時間管理和自我實現(xiàn)有沒有什么格外經(jīng)驗,貼之前的文章也行,想學習下。
答:時間管理個人經(jīng)驗,工作時關閉朋友圈、qq、各種群、郵件提醒等,它們是影響效率的主要矛盾。
自我實現(xiàn)?還在努力編碼、寫文章自我實現(xiàn)中。在百度的一段工作經(jīng)歷讓我印象很深刻,周圍比我牛逼的同事比我努力,一直努力向他們學習。
問:其實***問題我的意思是,如果不允許 cache miss 的 case 下怎么做rehash且盡可能少臟數(shù)據(jù)?
答:不允許cache miss,就做cache 高可用,cache高可用也如文章,有幾種實現(xiàn)方式。cache 一致性,見《緩存與數(shù)據(jù)庫一致性保證》,這篇文章會對你有幫助。
問:我看了不少的大型網(wǎng)站的構架演進,都是從all in one然后慢慢變成服務化的系統(tǒng)。既然,前人開路,我們后人已經(jīng)知道最終架構,那能不能一步到達這個服務化的系統(tǒng)?很多人給出不能的理由是一開始就搭建這樣的架構成本太高,要先發(fā)展業(yè)務再治理。但是在我看來,很多東西都可以自動化了,只要幾行命令就可以把一整套基礎架構搭好了,比如 jenkins 自動化集成+部署、大數(shù)據(jù)分析平臺kafka+spark+zookeeper+Hadoop 等,剩下就是在在這上面寫業(yè)務應用了及根據(jù)業(yè)務具體情況調參數(shù)了。正因如此,我不是很認同“成本高”這個觀點。請問,到底能不能一步到達最終的服務化的系統(tǒng),跳到中間的演化過程?為什么?也許有人會說了,適合的架構才是好的架構,你業(yè)務量現(xiàn)在還達不到,就沒必要做成和淘寶,58的架構。我想說,如果搭建和他們類似的架構的成本很低,那我為什么不搭建?簡單的說,問題是:能不能跳過大多公司的架構演化過程,直接搭建最終架構?
答:架構設計多想一步,不建議想太遠,如果回到10年前58同城重新創(chuàng)業(yè),估計架構還會是當初那個樣子,而不是現(xiàn)在一樣。
不建議跳過演化,架構是支持業(yè)務,不同階段業(yè)務需求不同,架構不同,***架構演化。架構師之路公眾號這篇文章《好架構是進化來的》可能會對你有幫助。
問:服務層到數(shù)據(jù)庫讀的高可用與服務層到數(shù)據(jù)庫寫的高可用 的取舍原則應該遵循哪些方面考慮?想請沈老師的提出一下見解,看看是否給我思考的思路一致?
答:《DB主從一致性架構優(yōu)化4種方法》這篇文章中有詳細的介紹。
問:如何避免服務掛掉之后,rpc client在轉移server的時候導致集群中的驚群效應?
答:我的理解,是不存在驚群的,假設原來5個服務10條連接,現(xiàn)在一個服務掛了,變成4個服務8條連接,只要負載分配策略是隨機的,流量依然是隨機的。
問:58到家在灰度發(fā)布和A/B是怎么樣的一個落地方案?
答:灰度發(fā)布是APP的灰度發(fā)布?還是類似推薦算法的AB測,多個算法同時運行?還是服務的平滑升級?對于***個,常見方法是渠道包,越獄包。對于第二個,需要有推薦算法分流平臺支持。對于第三個,web/service的升級,間隔重啟過程中,要切走流量,保證所有用戶不受影響。
以webserver平滑重啟為例,一般從nginx層切走一天tomcat的流量,這一臺升級站點重啟,nginx流量再切回,這么平滑。
問:58是否也做了分中心的建設,中心和中心的內部調用是否是rpc這種方式,又有那些場景是用消息調用,那些用rpc服務,怎么考量的,***有舉例?
答: 58沒有做多機房架構,《從IDC到云端架構遷移之路》這篇文章,講了同城機房遷移過程中,一段時間多機房的一些經(jīng)驗。原則是:不能做到完全不跨機房,就減少跨機房,“同連”架構,具體可以看文章。
問: 對于內存計算怎么看,目前redis功能太低級,內存計算同時勢必要讀取緩存信息,是否可以在內存計算中就把緩存的事情做了,還是緩存就是緩存,只做這一件事情?
答:不太清楚問題是想問什么,mc支持kv,redis支持一些數(shù)據(jù)結構,還有主從,還支持落地(不建議用),功能我倒是覺得太強大了,cache就是cache,做計算不合適,計算還是業(yè)務服務層自己做吧。
問:關于緩存和數(shù)據(jù)庫分布式后,重新分區(qū)后的數(shù)據(jù)遷移是否有好的方案?
答:這篇文章《58怎么玩數(shù)據(jù)庫架構》講了數(shù)據(jù)庫擴容,一種秒級擴容,一種遷數(shù)據(jù)擴容(不停服務),或許有幫助。緩存的擴容,可以二倍擴容,如果像我文章中proxy+cache集群的架構,擴容其實對調用方是透明的。
問:你的文章介紹了每個層級和階段的高可用方案和設計原則,我關心的是有了這些方案和原則設計出來的東西怎么檢驗,設計檢驗方案的思路和原則?
答:不是特別理解這個“怎么檢驗”,高可用上線前完全是可測的。例如nigix層高可用,做keepalived+vip后,干掉一臺,測試下能否繼續(xù)服務。
問:我想了解云環(huán)境下數(shù)據(jù)庫高可用怎么做?沒有vip怎么做?他們提供的負載,用起來有限制。比如mha不能做到vip漂移。
答:云端兩種方式,以阿里云為例。一種ECS+自搭建DB+購買阿里云類似vip的服務,一種用直接用rds高可用數(shù)據(jù)。印象中阿里云只有主庫提供rds高可用,從庫貌似不高可用(需要數(shù)據(jù)庫連接池自己實現(xiàn))。58到家目前使用阿里云,兩種方式都有用。
問:使用微服務的方式后如何保證某個服務的版本更新后,對其他各個服務之間的影響能盡可能小?
答:和服務化粒度有關,粒度越粗越耦合,一個地方升級影響其他。粒度越細,越不影響。這篇文章《微服務架構多“微”才合適》對你或許有幫助。
問:架構高可用就是否架構師和運維人員的事情?開發(fā)人員有能做和需要注意的?
答:我的理解,不適合存在專職架構師負責架構設計,開發(fā)人員負責編碼,本身架構就是 技術人 設計的,rd、dba、op等一起,高可用是大家的事情,只是說可能有個經(jīng)驗稍微豐富的研發(fā)(暫且叫架構師)牽頭來梳理和設計。
問:請問老師分布式系統(tǒng)里面唯一全局ID的生成規(guī)則有什么好的方式么?
答:請看這篇文章《細聊分布式ID生成方法》。
問: 從高程轉向架構師需要提高那方面的能力,在提高系統(tǒng)設計能力方面有什么建議?
答:這個問題有點泛,這篇文章或許有幫助(非我原創(chuàng))《互聯(lián)網(wǎng)架構師必備技能》。
問:假如我之前5個機器能支撐10w用戶,突然有一臺機器斷電了,然后流量分散到其他4臺,那么這4臺都超過***值了,就會掛了,也就是驚群效應,是否做拒絕策略,具體的落地怎么去做?
答:1)如果流量能抗住,直接分配沒問題。2)如果流量超出余下系統(tǒng)負載,要做降級,最簡單的方法就是拋棄請求,只為一部分用戶提供服務,而不是超出負載直接掛掉,這樣所有用戶都服務不了=> 服務自身需要做自我保護。
問:類似支付寶750積分這樣的灰度,類似運營可以配置策略這種方式來控制不同的人根據(jù)不同的策略,接觸的服務類型都是不一樣,這種的話具體的落地該如何去做呢?
答:這樣的灰度,就是不同的用戶的界面、功能、算法都不一樣的,需要系統(tǒng)支持(開關、流量策略、分流、不同實現(xiàn)),《58同城推薦系統(tǒng)架構設計與實現(xiàn)》這篇文章中“分流”的部分,應該會有幫助。
問:請問web集群中的數(shù)據(jù)同步,如果涉及跨機房,有什么好的方法盡量避免跨不同區(qū)域機房的數(shù)據(jù)同步和復制中的可靠性,或有其他更好的方法避免跨機房間的數(shù)據(jù)交互嗎?
答:這是多機房的問題,后續(xù)在多機房架構的文章中在具體闡述。多機房架構常見三個方案:
1)冷備(強烈不推薦);
2)偽多機房(跨機房讀主庫數(shù)據(jù));
3)多機房多活(入口流量切分+雙機房數(shù)據(jù)同步)。
問:58的服務降級如何做的?
答:不說結合業(yè)務的降級(跳過非關鍵路徑),通用的系統(tǒng)層面的降級,常見做法是設置隊列,超出負載拋棄請求。這個方案是不好的,當一個上游請求變大,會是的所有上游排隊,拋棄請求,都受影響。
58服務治理一般這么做:針對不同調用方,限定流量;一個調用方超量,只拋棄這個調用方的請求,其他調用方不受影響。
末了,希望文章的思路是清晰的,希望大家對高可用的概念和實踐有個系統(tǒng)的認識,感謝大家。
【本文為51CTO專欄作者“58沈劍”原創(chuàng)稿件,轉載請聯(lián)系原作者】