大數據的那些事(3):三駕馬車之坑人的MapReduce
在Google的三駕馬車里面,Google File System是永垂不朽的,也是基本上沒有人去做什么進一步的研究的。
BigTable是看不懂的,讀起來需要很多時間精力。
唯獨MapReduce,是霓虹燈前面閃爍的星星,撕逼戰斗的主角,眾人追捧和喊打的對象。自從MapReduce這個詞出來以后,不知道有多少篇論文發表出來,又不知道有多少口誅筆伐的文章。
我曾經在HANA篇里寫過圍繞MapReduce,Google和Michael StoneBraker等等database的元老之間的論戰。歡迎大家先讀讀這篇八卦文。為了避免重復,這篇文章里,我就不再展開這部分的話題了。
作為論文來說MapReduce嚴格的來講不能算作一篇論文,因為它講述了兩件不同的事情。其一是一個叫做MapReduce的編程模型。其二是大規模數據處理的體系架構的實現。
這篇論文將兩者以某種方式混雜在一起來達到不可告人的目的,并且把這個體系吹得非常的牛,但是卻并沒有討論一些Google內部造就知道的局限性,以我對某狗的某些表現來看,恐怕我的小人之心覺得有意為之的可能性比較大。
因此當智商比較低的Yahoo活雷鋒抄襲MapReduce的時候弄出的Hadoop是不倫不類,這才有了后來Hadoop V2以及Yarn的引進。當然這是后話。
作為同樣抄襲對象的微軟就顯得老道很多。微軟內部支撐大數據分析的平臺Cosmos是狠狠的抄襲了Google的File system卻很大程度上摒棄了MapReduce這個框架。
我們先看看作為編程模型的MapReduce。所謂MapReduce的意思是任何的事情只要都嚴格遵循Map Shuffle Reduce三個階段就好。
其中Shuffle是系統自己提供的而Map和Reduce則用戶需要寫代碼。Map是一個per record的操作。
任何兩個record之間都相互獨立。Reduce是個per key的操作,相同key的所有record都在一起被同時操作,不同的key在不同的group下面,可以獨立運行。
這就像是說我們有一把大砍刀,一個錘子。
世界上的萬事萬物都可以先砍幾刀再錘幾下,就能搞定。至于刀怎么砍,錘子怎么錘,那就算個人的手藝了。 從計算模型的角度來看,這個模型極其的粗糙。
所以現在連Google自己都不好意思繼續鼓吹MapReduce了。從做數據庫的人的角度來看這無非是一個select一個groupby,這些花樣197x的時候在SystemR里都被玩過了。數據庫領域玩這些花樣無數遍。真看不出有任何值得鼓吹的道理。
因此,在計算模型的角度上來說,我覺得Google在很大程度上誤導和夸大了MapReduce的實際適用范圍,也可能是自己把自己也給忽悠了。
在Google內部MapReduce最大的應用是作為inverted index的build的平臺。所謂inverted index是information retrieval里面一個重要的概念,簡單的講是從單詞到包含單詞的文本的一個索引。我們搜索internet,google需要爬蟲把網頁爬下來,然后建立出網頁里面的單詞到這個網頁的索引。
這樣我們輸入關鍵字搜索的時候,對應的頁面才能出來。也正因為是這樣,所以Google的論文里面用了word count這個例子。下圖是word count的MapReduce的一個示意圖。
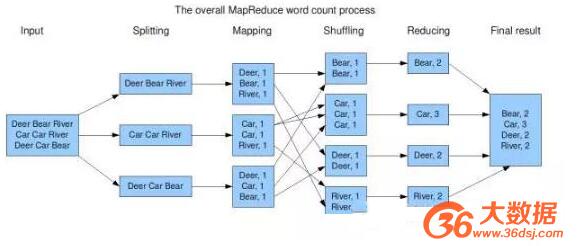
然而我們需要知道的是,Google后來公布的信息顯示它的廣告系統是一直運行在MySQL的cluster的,該做join的時候也是做join的。
MapReduce作為一個編程模型來說,顯然不是萬能的藥。可是因為編程模型涉及的是世界觀方法論的問題。
于是催生了無數篇論文,大致的套路都是我們怎么樣用MapReduce去解決這個那個問題。這些論文催生了無數PhD,幫助很多老師申請到了很多的錢。
我覺得很大程度上都掉進了google的神話和這個編程模型的坑。 MapReduce這篇論文的另外一個方面是系統實現。我們可以把題目寫成:如何用一堆廉價PC去穩定的實現超大規模的并行數據處理。
我想這無疑可以體現出這篇論文真正有意義的地方。的確,數據庫的工業界和學術界都玩了幾十年了,有哪個不是用高端的機器。
在MapReduce論文出來的那個時候,誰能處理1個PB的數據我給誰跪了。但是Google就能啊。我得意的笑我得意的笑。
所以Google以它十分牛逼的數據處理平臺,去吹噓那個沒有什么價值的編程模型。而數據庫的人以攻擊Google十分不行的編程模型,卻故意不去看Google那個十分強悍的數據處理平臺。
這場馮京對馬涼的比賽,我覺得毫無意義。 那么我們來看看為什么Google可以做到那么大規模的數據處理。
首先這個系統的第一條,很簡單,所有的中間結果可以寫入到一個穩定的,不因為單機的失敗而不能工作的分布式海量文件系統。GFS的偉大可見一斑。沒有GFS,玩你妹的MapReduce。沒有一個database廠商做出過偉大的GFS,當然也就沒辦法做出這么牛叉的MapReduce了。
這個系統的第二條也很簡單,能夠對單個worker進行自動監視和retry。這一點就使得單個節點的失敗不是問題,系統可以自動的進行管理。加上Google一直保持著絕不泄密的資源管理系統Borg。使得Google對于worker能夠進行有效的管理。
Borg這個系統存在有10多年了,但是Google故意什么都不告訴大家,論文里也假裝沒有。我第一次聽說是幾個從Google出來的人在Twitter想重新搞這樣一個東西。然而一直到以docker為代表的容器技術的出現,才使得大家知道google的Borg作為一個資源管理和虛擬化系統到底是怎么樣做的。
而以docker為代表的容器技術的出現也使得Borg的優勢不存在了。所以Google姍姍來遲的2015年終于發了篇論文。我想這也是Yahoo這個活雷鋒沒有抄好,而HadoopV2必須引入Yarn的很重要的原因。
解釋這么多,其實是想說明幾點,MapReduce作為編程模型,是一個很傻的模型。完全基于MapReduce的很多project都不太成功。
而這個計算模型最重要的是做inverted index build,這就使得Google長久以來宣揚的Join沒意義的論調顯得很作。另外隨著F1的披露,大家知道Google的Ads系統實際上長期運行在MySQL上,這也從側面反應了Google內部的一些情況和當初論文的高調宣揚之間的矛盾。
Google真正值得大家學習的是它怎么樣實現了大規模數據并發的處理。這個東西說穿了,一是依賴于一個很牛的文件系統,二是有著很好的自動監控和重試機制。
而MapReduce這個編程模型又使得這兩者的實現都簡化了。然而其中很重要的資源管理系統Borg又在當初的論文里被徹底隱藏起來了。我想,隨著各種信息的披露,我只能說一句,你妹的。
MapReduce給學術界掀起了一片灌水高潮,學術界自娛自樂的精神實在很值得敬佩。然而這個東西火得快,死的也快。所謂人怕出名豬怕撞。
同系列之: