借助 Redis ,讓 Spark 提速 45 倍!
一些內存數(shù)據(jù)結構比其他數(shù)據(jù)結構來得更高效;如果充分利用Redis,Spark運行起來速度更快。
Apache Spark已逐漸儼然成為下一代大數(shù)據(jù)處理工具的典范。通過借鑒開源算法,并將處理任務分布到計算節(jié)點集群上,無論在它們在單一平臺上所能執(zhí)行的數(shù)據(jù)分析類型方面,還是在執(zhí)行這些任務的速度方面,Spark和Hadoop這一代框架都輕松勝過傳統(tǒng)框架。Spark利用內存來處理數(shù)據(jù),因而速度比基于磁盤的Hadoop大幅加快(快100倍)。
但是如果得到一點幫助,Spark可以運行得還要快。如果結合Spark和Redis(流行的內存數(shù)據(jù)結構存儲技術),你可以再次大幅提升處理分析任務的性能。這歸功于Redis經(jīng)過優(yōu)化的數(shù)據(jù)結構,以及它在執(zhí)行操作時,能夠盡量降低復雜性和開銷。通過借助連接件訪問Redis數(shù)據(jù)結構和API,Spark可以進一步加快速度。
提速幅度有多大?如果Redis和Spark結合使用,結果證明,處理數(shù)據(jù)(以便分析下面描述的時間序列數(shù)據(jù))的速度比Spark單單使用進程內存或堆外緩存來存儲數(shù)據(jù)要快45倍――不是快45%,而是快整整45倍!
為什么這很重要?許多公司日益需要分析交易的速度與業(yè)務交易本身的速度一樣快。越來越多的決策變得自動化,驅動這些決策所需的分析應該實時進行。Apache Spark是一種出色的通用數(shù)據(jù)處理框架;雖然它并非***實時,還是往更及時地讓數(shù)據(jù)發(fā)揮用途邁出了一大步。
Spark使用彈性分布式數(shù)據(jù)集(RDD),這些數(shù)據(jù)集可以存儲在易失性內存中或HDFS之類的持久性存儲系統(tǒng)中。RDD不會變化,分布在Spark集群的所有節(jié)點上,它們經(jīng)轉換化可以創(chuàng)建其他RDD。
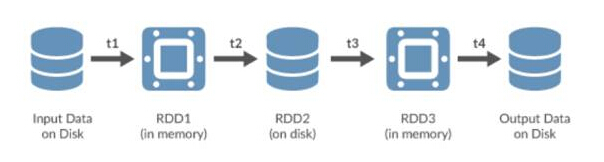
Spark RDD
RDD是Spark中的重要抽象對象。它們代表了一種高效地將數(shù)據(jù)呈現(xiàn)給迭代進程的容錯方法。由于處理工作在內存中進行,這表示相比使用HDFS和MapReduce,處理時間縮短了好幾個數(shù)量級。
Redis是專門為高性能設計的。亞毫秒延遲得益于經(jīng)過優(yōu)化的數(shù)據(jù)結構,由于讓操作可以在鄰近數(shù)據(jù)存儲的地方執(zhí)行,提高了效率。這種數(shù)據(jù)結構不僅可以高效地利用內存、降低應用程序的復雜性,還降低了網(wǎng)絡開銷、帶寬消耗量和處理時間。Redis數(shù)據(jù)結構包括字符串、集合、有序集合、哈希、位圖、hyperloglog和地理空間索引。開發(fā)人員可以像使用樂高積木那樣使用Redis數(shù)據(jù)結構――它們就是提供復雜功能的簡單管道。
為了直觀地表明這種數(shù)據(jù)結構如何簡化應用程序的處理時間和復雜性,我們不妨以有序集合(Sorted Set)數(shù)據(jù)結構為例。有序集合基本上是一組按分數(shù)排序的成員。

Redis有序集合
你可以將多種類型的數(shù)據(jù)存儲在這里,它們自動由分數(shù)來排序。存儲在有序集合中的常見數(shù)據(jù)類型包括:物品(按價格)、商品名稱(按數(shù)量)、股價等時間序列數(shù)據(jù),以及時間戳等傳感器讀數(shù)。
有序集合的魅力在于Redis的內置操作,讓范圍查詢、多個有序集合交叉、按成員等級和分數(shù)檢索及更多事務可以簡單地執(zhí)行,具有***的速度,還可以大規(guī)模執(zhí)行。內置操作不僅節(jié)省了需要編寫的代碼,內存中執(zhí)行操作還縮短了網(wǎng)絡延遲、節(jié)省了帶寬,因而能夠實現(xiàn)亞毫秒延遲的高吞吐量。如果將有序集合用于分析時間序列數(shù)據(jù),相比其他內存鍵/值存儲系統(tǒng)或基于磁盤的數(shù)據(jù)庫,通常可以將性能提升好幾個數(shù)量級。
Redis團隊的目標是提升Spark的分析功能,為此開發(fā)了Spark-Redis連接件。這個程序包讓Spark得以使用Redis作為其數(shù)據(jù)源之一。該連接件將Redis的數(shù)據(jù)結構暴露在Spark面前,可以針對所有類型的分析大幅提升性能。

Spark Redis連接件
為了展示給Spark帶來的好處,Redis團隊決定在幾種不同的場景下執(zhí)行時間片(范圍)查詢,以此橫向比較Spark中的時間序列分析。這幾種場景包括:Spark在堆內內存中存儲所有數(shù)據(jù),Spark使用Tachyon作為堆外緩存,Spark使用HDFS,以及結合使用Spark和Redis。
Redis團隊使用Cloudera的Spark時間序列程序包,構建了一個Spark-Redis時間序列程序包,使用Redis有序集合來加快時間序列分析。除了讓Spark可以訪問Redis的所有數(shù)據(jù)結構外,該程序包另外做兩件事:
自動確保Redis節(jié)點與Spark集群一致,從而確保每個Spark節(jié)點使用本地Redis數(shù)據(jù),因而優(yōu)化延遲。
與Spark數(shù)據(jù)幀和數(shù)據(jù)源API整合起來,以便自動將Spark SQL查詢轉換成對Redis中的數(shù)據(jù)來說***效的那種檢索機制。
簡單地說,這意味著用戶不必擔心Spark和Redis之間的操作一致性,可以繼續(xù)使用Spark SQL來分析,同時大大提升了查詢性能。
用于這番橫向比較的時間序列數(shù)據(jù)包括:隨機生成的金融數(shù)據(jù),每天1024支股票,時間范圍是32年。每只股票由各自的有序集合來表示,分數(shù)是日期,數(shù)據(jù)成員包括開盤價、***價、***價、收盤價、成交量以及調整后的收盤價。下圖描述了用于Spark分析的Redis有序集合中的數(shù)據(jù)表示:
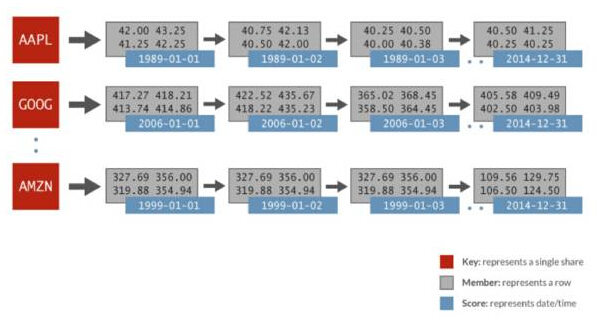
Spark Redis時間序列
在上述例子中,就有序集合AAPL而言,有表示每天(1989-01-01)的分數(shù),還有全天中表示為一個相關行的多個值。只要在Redis中使用一個簡單的ZRANGEBYSCORE命令,就可以執(zhí)行這一操作:獲取某個時間片的所有值,因而獲得指定的日期范圍內的所有股價。Redis執(zhí)行這種類型的查詢的速度比其他鍵/值存儲系統(tǒng)快100倍。
這番橫向比較證實了性能提升。結果發(fā)現(xiàn),Spark使用Redis執(zhí)行時間片查詢的速度比Spark使用HDFS快135倍,比Spark使用堆內(進程)內存或Spark使用Tachyon作為堆外緩存快45倍。下圖顯示了針對不同場景所比較的平均執(zhí)行時間:
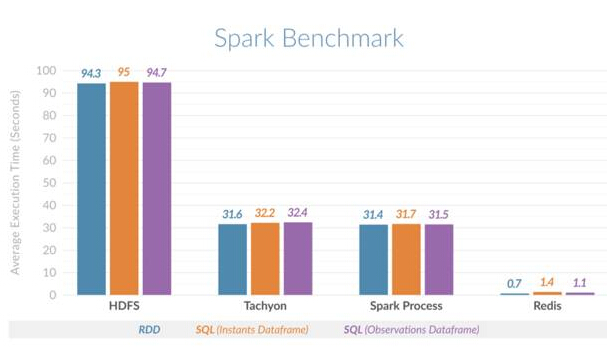
Spark Redis橫向比較
如果你想親自嘗試一下,不妨遵照這篇可下載的逐步指南:《Spark和Redis使用入門》(https://redislabs.com/solutions/spark-and-redis)。該指南將逐步引導你安裝典型的Spark集群和Spark-Redis程序包。它還用一個簡單的單詞計數(shù)例子,表明了可以如何結合使用Spark和Redis。你在試用過Spark和Spark-Redis程序包后,可以進一步探究利用其他Redis數(shù)據(jù)結構的更多場景。
雖然有序集合很適合時間序列數(shù)據(jù),但Redis的其他數(shù)據(jù)結構(比如集合、列表和地理空間索引)可以進一步豐富Spark分析。設想一下:一個Spark進程試圖根據(jù)人群偏好以及鄰近市中心,獲取在哪個地區(qū)發(fā)布新產品效果***的信息。現(xiàn)在設想一下,內置分析自帶的數(shù)據(jù)結構(比如地理空間索引和集合)可以大大加快這個進程。Spark-Redis這對組合擁有***的應用前景。
Spark支持一系列廣泛的分析,包括SQL、機器學習、圖形計算和Spark Streaming。使用Spark的內存處理功能只能讓你達到一定的規(guī)模。然而有了Redis后,你可以更進一步:不僅可以通過利用Redis的數(shù)據(jù)結構來提升性能,還可以更輕松自如地擴展Spark,即通過充分利用Redis提供的共享分布式內存數(shù)據(jù)存儲機制,處理數(shù)百萬個記錄,乃至數(shù)十億個記錄。
時間序列這個例子只是開了個頭。將Redis數(shù)據(jù)結構用于機器學習和圖形分析同樣有望為這些工作負載帶來執(zhí)行時間大幅縮短的好處。