簡析TCP協議的TIME_WAIT與CLOSE_WAIT狀態
一、服務器異常
如果服務器出了異常,十之八九都是以下兩種情況:
1.服務器保持了大量TIME_WAIT狀態
2.服務器保持了大量CLOSE_WAIT狀態
二、TIME_WAIT狀態
1、TIME_WAIT狀態存在的兩個理由:
1)讓4次握手關閉流程更加可靠;4次握手的***一個ACK是是由主動關閉方發送出去的,若這個ACK丟失,被動關閉方會再次發一個FIN過來。若主動關閉方能夠保持一個2MSL的TIME_WAIT狀態,則有更大的機會讓丟失的ACK被再次發送出去。
如果主動關閉端不維持TIME_WAIT狀態,而是處于CLOSED 狀態,那么當主動端ACK丟失,被動方將重發最終的FIN,而主動端將響應RST,被動端收到后將此分節解釋成一個錯誤(在java中會拋出connection reset的SocketException)。
因而,要實現TCP全雙工連接的正常終止,必須處理終止過程中四個分節任何一個分節的丟失情況,主動關閉連接的A端必須維持TIME_WAIT狀態 。
2)允許老的重復分節在網絡中消逝,防止lost duplicate對后續新建正常鏈接的傳輸造成破壞。lost duplicate在實際的網絡中非常常見,經常是由于路由器產生故障,路徑無法收斂,導致一個packet在路由器A,B,C之間做類似死循環的跳轉。IP頭部有個TTL,限制了一個包在網絡中的***跳數,因此這個包有兩種命運,要么***TTL變為0,在網絡中消失;要么TTL在變為0之前路由器路徑收斂,它憑借剩余的TTL跳數終于到達目的地。但非常可惜的是TCP通過超時重傳機制在早些時候發送了一個跟它一模一樣的包,并先于它達到了目的地,因此它的命運也就注定被TCP協議棧拋棄。
另外一個概念叫做incarnation connection,指跟上次的socket pair一模一樣的新連接,叫做incarnation of previous connection。lost duplicate加上incarnation connection,則會對我們的傳輸造成致命的錯誤。
大家都知道TCP是流式的,所有包到達的順序是不一致的,依靠序列號由TCP協議棧做順序的拼接;假設一個incarnation connection這時收到的seq=1000, 來了一個lost duplicate為seq=1000, len=1000, 則tcp認為這個lost duplicate合法,并存放入了receive buffer,導致傳輸出現錯誤。通過一個2MSL TIME_WAIT狀態,確保所有的lost duplicate都會消失掉,避免對新連接造成錯誤。
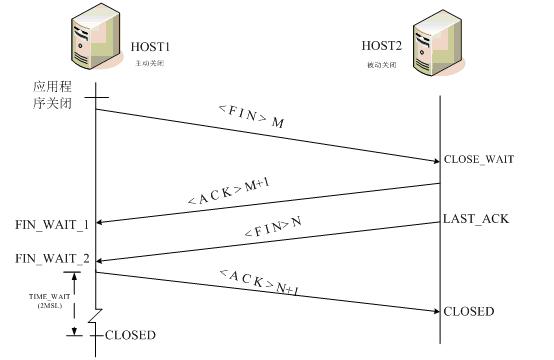
2、該狀態為什么設計在主動關閉這一方:
(1)發***ack的是主動關閉一方
(2)只要有一方保持TIME_WAIT狀態,就能起到避免incarnation connection在2MSL內的重新建立,不需要兩方都有。
3、如何正確對待2MSL TIME_WAIT
RFC要求socket pair在處于TIME_WAIT時,不能再起一個incarnation connection。但絕大部分TCP實現,強加了更為嚴格的限制。在2MSL等待期間,socket中使用的本地端口在默認情況下不能再被使用。若A 10.234.5.5:1234和B 10.55.55.60:6666建立了連接,A主動關閉,那么在A端只要port為1234,無論對方的port和ip是什么,都不允許再起服務。顯而易見這是比RFC更為嚴格的限制,RFC僅僅是要求socket pair不一致,而實現當中只要這個port處于TIME_WAIT,就不允許起連接。
這個限制對主動打開方來說是無所謂的,因為一般用的是臨時端口;但對于被動打開方,一般是server,那就悲劇了,因為server一般是熟知端口。比如http一般端口是80,不可能允許這個服務在2MSL內不能起來。解決方案是給服務器的socket設置SO_REUSEADDR選項,這樣的話就算熟知端口處于TIME_WAIT狀態,在這個端口上依舊可以將服務啟動。當然,雖然有了SO_REUSEADDR選項,但sockt pair這個限制依舊存在。比如上面的例子,A通過SO_REUSEADDR選項依舊在1234端口上起了監聽,但這時我們若是從B通過6666端口去連它,TCP協議會告訴我們連接失敗,原因為Address already in use。#p#
三、CLOSE_WAIT狀態
因為linux分配給一個用戶的文件句柄是有限的,而TIME_WAIT和CLOSE_WAIT兩種狀態如果一直被保持,那么意味著對應數目的通道就一直被占著,一旦達到句柄數上限,新的請求就無法被處理了,接著應用程序可能返回大量Too Many Open Files異常。
1、Close_Wait引發的問題
Close_Wait會占用一個連接,網絡可用連接小。數量過多,可能會引起網絡性能下降,并占用系統非換頁內存。 尤其是在有連接池的情況下(比如HttpRequest)
會耗盡連接池的網絡連接數,導致無法建立網絡連接。
2、解決方法
下面來討論下這兩種情況的處理方法,優化系統內核參數解決TIME_WAIT可能很容易,可以通過修改/etc/sysctl.conf文件解決;
但是應對CLOSE_WAIT的情況還是需要從程序本身出發。因為發生TIME_WAIT的情況是服務器自己可控的,要么就是對方連接的異常,要么就是自己沒有迅速回收資源,總之不是由于自己程序錯誤導致的。從上面的圖可以看出來,如果一直保持在CLOSE_WAIT狀態,那么只有一種情況,就是在對方關閉連接之后服務器程序自己沒有進一步發出FIN信號,一般原因都是TCP連接沒有調用關閉方法。換句話說,就是在對方連接關閉之后,程序里沒有檢測到,或者程序壓根就忘記了這個時候需要關閉連接,于是這個資源就一直被程序占著。這種情況,通過服務器內核參數也沒辦法解決,服務器對于程序搶占的資源沒有主動回收的權利,除非終止程序運行,一定程度上,可以使用TCP的KeepAlive功能,讓操作系統替我們自動清理掉CLOSE_WAIT連接。