













GPU超算完整體驗 AMD FirePro 通用計算特性
使用顯卡或者說GPU執行通用計算早就已經不是什么新鮮的事情,這得益于整個行業近年來不遺余力的推動,例如AMD、Apple、NVIDIA、Intel 等都把 GPU 執行非圖形處理作為新業務的重中之重來推廣。
雖然說GPU通用計算不再是新鮮事,但是對于許多人而言,可能也就僅限于聽過而已,其中的一些關鍵信息缺并不十分了解,這并不奇怪,因為“聽過”的人當中其實大部分都是游戲玩家,就算對這方面有更多認識(例如懂得寫OpenCL 代碼)的人來說,也未必能對廠商為什么會推出專門的超算卡有充分的認知。
我們以AMDFirePro為例,這個產品線最初是叫 FireGL,本是針對圖形工作站為主的應用,因為圖形工作站的最突出特點就是使用 OpenGL 作為圖形 API。
后來AMD推出了FireStream 產品線,這個產品線類似于競爭廠商的 Tesla 產品線,為了統一品牌推廣,AMD 將 FireStream 和 FireGL 產品線合并,現在分別名為 FirePro S 系列和 FirePro W 系列,S 和 W 分別是英文中服務器和工作站的首字母。

拿下2014年度Green500 ***名的 AMD FirePro S9150 服務器超算卡

AMDFireProS9150采用了特別設計的被動散熱方案
從外觀上看S和W 的區別其實很簡單,分別就是 S 是被動散熱,而 W 則是主動散熱,而且 W 是主打傳統圖形工作站應用的,其中要 W8X00 級別以上的產品才具備較高的浮點計算性能,往下的 W 系列顯卡不強調雙精度性能(至少目前是這樣)。
除了雙精度性能的區別外,W8X00級別以上的產品一般還會配備較大的卡載內存,這樣的設計不僅有利于復雜場景的工作站應用,而且對通用計算來說也是有非常大的助益。
在GordenBell(DEC公司早期雇員之一,早期的 PDP 小型機設計者,現在美國計算機協會設立的 Gorden Bell 獎被視作計算機界的諾貝爾獎,于每年 SC 大會上頒發)所撰寫的《Great and Big Ideas in Computer Structures》一文中,關于資源平衡有這樣的說法:
按照上世紀60年代提出的 Amdahl 法則,指令速度、內存容量、位元速率的性能平衡,應該做到每秒一條指令對應一個字節的一級內存大小和每秒一個位元的內存帶寬(這些指標是相對值,換個說法就是每周期一條指令的性能需要一個字節的一級內存空間和每個周期一個位元的內存帶寬來達致性能平衡)。
到了90年代,在科學計算領域,要實現每秒浮點操作(flops)與內存的平衡,就得做到不低于1flops/字節 到 1flops/8字節。
在多級內存方面,美國LosAlamosNational Laboratory(洛斯阿拉莫斯國家實驗室)曾經對若干個“重大挑戰”的計算問題進行了評估,得出的結論是:每個一級內存字節需要 1/15 到 5000 個二級內存字節才能達致平衡。
按照這樣的說法,如果GPU里有2.8 MiB 內存(例如 AMD GPU 里稱作 Local Data Store 的那塊小內存),就需要 14 GiB 片外內存才能在科學計算上做到“性能平衡”,看到這里,也就不能難解釋為何 AMD FirePro W9100 和 FirePro S9150 搭配高達 16 GiB 的卡載內存了——這不是隨便拍下腦袋決定的。
AMDFirePro產品針對超算的一個特別設計就是提供了ECC 的支持,而這個特性在游戲卡中是不提供的。
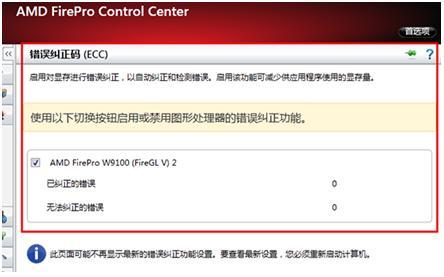
超算執行的操作往往涉及大量的數據處理,但是受到宇宙背景射線的影響,存儲芯片非常容易因此而導致位元錯誤,例如8(00111000)會變成 9(0011 1001)。
根據美國NASA(國家航空航天局)發布的一份名為“In-FlightObservationsof Multiple-Bit Upset in DRAMs”的文件有這樣的統計結果:
在1997年發射的卡西尼-惠更斯號土星探測器內有兩個相同的飛行記錄儀,它們各有一個2.5 GiB 采用商用動態內存芯片的內存陣列。在頭兩年半的飛行中,飛船的工程自動遙測報告顯示每天都持續有大約 280 個位元錯誤,而在頭一個月的時候更是可能因為太陽粒子活動,出現了單日錯誤數增加超過 4 倍的現象發生。
這樣的現象會隨著DRAM密度的增加而進一步加重,這意味著隨著工藝進步,芯片越來越小、耗電越來越低,同面積存儲器發生錯誤的次數越多。
GCN微架構在芯片級提供了硬件ECC,所有的片上緩存都受到ECC 技術的保護,能偵測并矯正片上緩存受宇宙射線影響導致的單個位元錯誤。
在片外內存或者說顯卡卡載內存上,AMD為FirePro提供了一個驅動面板開關,允許用家自行決定是否啟用 ECC 技術,用來確保這部份數據存儲和傳輸可靠性。
當然,由于GDDR5缺乏ECC,因此這里就涉及到一些額外的數據傳輸進行驗證,容量和帶寬會因此受到影響,相應顯卡的性能會有一定的影響,影響幅度取決于具體的應用。
和速度受到一定影響相比,計算結果是否準確才是超算最為關心的,尤其是大規模集群計算,這點和游戲卡只是輸出至顯示器、幾乎不存在數據復用的情況很不一樣。
說到這,就不得不提一個容易讓人誤解的問題:交火并行渲染。Crossfire是AMD的并行渲染技術,不過它并不能讓未指定設備的超算代碼自動以并行方式運行。
交火的時候,驅動程序會自動安排好渲染幀或者中間數據的處理,然后副卡把渲染好的數據傳輸到主卡里進行后續的處理(例如合并為最終輸出的色彩緩存數據)。
但是超算的執行方式并不是這樣的,原因在于數據復用情況要復雜許多,理論上它也不需要畫面輸出操作,故此交火和超算是沒啥關系的,因此在FirePro上你是看不到游戲卡的那個交火橋接插頭,因為多卡并行完全是由超算代碼開發人員或者編譯器來實現的。
綜上所述,你可以看到:
1、藍寶PGSAMDFirePro 和游戲卡在硬件上存在板卡級的區別。
2、藍寶PGSAMDFirePro 和游戲卡存在軟件驅動的重要區別。
3、藍寶PGSAMDFirePro 有多種提供給超算用戶的方案,例如偏工作站應用、強調單精度性能耗電比的 W 系列以及強調雙精度性能、偏向服務器、注重機箱型制的 S 系列。
不過除了這幾點外,還有一點需要在***提一下,那就是產品生命周期方面,FirePro提供了至少3年的售后支持,而游戲卡一般也就是 1 年,更重要的是,FirePro 面向的超算是技術含量遠遠高于游戲的應用,非常需要來自廠商的***手技術支持,AMD 在這方面為 FirePeo 提供了相應的有力支持,經常有培訓班提供,為用戶打開了價值提升的空間。


















