













Spark 1.2 發布,開源集群計算系統
作者:開源中國
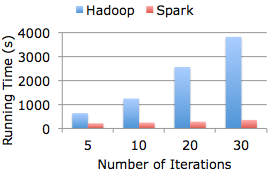
Spark 是一種與 Hadoop 相似的開源集群計算環境,但是兩者之間還存在一些不同之處,Spark 啟用了內存分布數據集,除了能夠提供交互式查詢外,它還可以優化迭代工作負載。Spark 1.2 發布,此版本包括 172 位貢獻者和超過 1000 個 commits。
Spark 1.2 發布,此版本包括 172 位貢獻者和超過 1000 個 commits。
此版本包括
- Spark 核心操作和性能改進;
- 添加新的網絡傳輸子系統,進行了較大的改進;
- Spark SQL 引入了一個外部數據源的支持,支持 Hive13;
- 動態分區;
- fixed-precision decimal type;
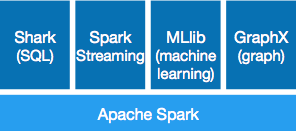
- MLlib 添加了一個新的面向管道包 (spark.ml),組合多個算法;
- Spark Streaming 添加了一個 Python API,提前寫錯誤容錯日志;
- GraphX 正式脫離 Alpha 版本,引入了一個穩定的 API。
更多內容請看發行說明,現已提供下載。
Spark 是一種與 Hadoop 相似的開源集群計算環境,但是兩者之間還存在一些不同之處,這些有用的不同之處使 Spark 在某些工作負載方面表現得更加優越,換句話說,Spark 啟用了內存分布數據集,除了能夠提供交互式查詢外,它還可以優化迭代工作負載。
Spark 是在 Scala 語言中實現的,它將 Scala 用作其應用程序框架。與 Hadoop 不同,Spark 和 Scala 能夠緊密集成,其中的 Scala 可以像操作本地集合對象一樣輕松地操作分布式數據集。
盡管創建 Spark 是為了支持分布式數據集上的迭代作業,但是實際上它是對 Hadoop 的補充,可以在 Hadoo 文件系統中并行運行。通過名為 Mesos 的第三方集群框架可以支持此行為。Spark 由加州大學伯克利分校 AMP 實驗室 (Algorithms, Machines, and People Lab) 開發,可用來構建大型的、低延遲的數據分析應用程序。
責任編輯:Ophira
來源:
開源中國社區
















