Storm與Spark:誰(shuí)才是我們的實(shí)時(shí)處理利器
譯文實(shí)時(shí)商務(wù)智能這一構(gòu)想早已算不得什么新生事物(早在2006年維基百科中就出現(xiàn)了關(guān)于這一概念的頁(yè)面)。然而盡管人們多年來(lái)一直在對(duì)此類方案進(jìn)行探討,我卻發(fā)現(xiàn)很多企業(yè)實(shí)際上尚未就此規(guī)劃出明確發(fā)展思路、甚至沒能真正意識(shí)到其中蘊(yùn)含的巨大效益。
為什么會(huì)這樣?一大原因在于目前市場(chǎng)上的實(shí)時(shí)商務(wù)智能與分析工具仍然非常有限。傳統(tǒng)數(shù)據(jù)倉(cāng)庫(kù)環(huán)境針對(duì)的主要是批量處理流程,這類方案要么延遲極高、要么成本驚人——當(dāng)然,也可能二者兼具。
然而已經(jīng)有多款強(qiáng)大而且易于使用的開源平臺(tái)開始興起,欲徹底扭轉(zhuǎn)目前的不利局面。其中最值得關(guān)注的兩大項(xiàng)目分別為Apache Storm與Apache Spark,它們都能為廣大潛在用戶提供良好的實(shí)時(shí)處理能力。兩套方案都?xì)w屬于Apache軟件基金會(huì),而且除了在功能方面的一部分交集之外、兩款工具還各自擁有著獨(dú)特的特性與市場(chǎng)定位。
Storm:實(shí)時(shí)處理領(lǐng)域的Hadoop
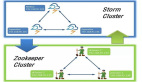
作為一套專門用于事件流處理的分布式計(jì)算框架,Storm的誕生可以追溯到當(dāng)初由BackType公司開發(fā)的項(xiàng)目——這家市場(chǎng)營(yíng)銷情報(bào)企業(yè)于2011年被Twitter所收購(gòu)。Twitter旋即將該項(xiàng)目轉(zhuǎn)為開源并推向GitHub平臺(tái),不過(guò)Storm最終還是加入了Apache孵化器計(jì)劃并于2014年9月正式成為Apache旗下的***項(xiàng)目之一。
Storm有時(shí)候也被人們稱為實(shí)時(shí)處理領(lǐng)域的Hadoop。Storm項(xiàng)目的說(shuō)明文檔看起來(lái)對(duì)這種稱呼也表示認(rèn)同:“Storm大大簡(jiǎn)化了面向龐大規(guī)模數(shù)據(jù)流的處理機(jī)制,從而在實(shí)時(shí)處理領(lǐng)域扮演著Hadoop之于批量處理領(lǐng)域的重要角色。”
為了達(dá)成上述目標(biāo),Storm在設(shè)計(jì)思路中充分考慮到大規(guī)模可擴(kuò)展能力、利用一套“故障快速、自動(dòng)重啟”方案為處理提供容錯(cuò)性支持、從而有力地保證了每個(gè)元組都能切實(shí)得到處理。Storm項(xiàng)目默認(rèn)為消息采取“至少一次”的處理覆蓋保障,但用戶也能夠根據(jù)需要實(shí)現(xiàn)“僅為一次”的處理方式。
Storm項(xiàng)目主要利用Clojure編寫而成,且既定設(shè)計(jì)目標(biāo)在于支持將“流”(例如輸入流)與“栓”(即處理與輸出模塊)結(jié)合在一起并構(gòu)成一套有向無(wú)環(huán)圖(簡(jiǎn)稱DAG)拓?fù)浣Y(jié)構(gòu)。Storm的拓?fù)浣Y(jié)構(gòu)運(yùn)行在集群之上,而Storm調(diào)度程序則根據(jù)具體拓?fù)渑渲脤⑻幚砣蝿?wù)分發(fā)給集群當(dāng)中的各個(gè)工作節(jié)點(diǎn)。
大家可以將拓?fù)浣Y(jié)構(gòu)大致視為MapReduce在Hadoop當(dāng)中所扮演的角色,只不過(guò)Storm的關(guān)注重點(diǎn)放在了實(shí)時(shí)、以流為基礎(chǔ)的處理機(jī)制身上,因此其拓?fù)浣Y(jié)構(gòu)默認(rèn)永遠(yuǎn)運(yùn)行或者說(shuō)直到手動(dòng)中止。一旦拓?fù)淞鞒虇?dòng),挾帶著數(shù)據(jù)的流就會(huì)不斷涌入系統(tǒng)并將數(shù)據(jù)交付給栓(而數(shù)據(jù)仍將在各栓之間循流程繼續(xù)傳遞),而這也正是整個(gè)計(jì)算任務(wù)的主要實(shí)現(xiàn)方式。隨著處理流程的推進(jìn),一個(gè)或者多個(gè)栓會(huì)把數(shù)據(jù)寫入至數(shù)據(jù)庫(kù)或者文件系統(tǒng)當(dāng)中,并向另一套外部系統(tǒng)發(fā)出消息或者將處理獲得的計(jì)算結(jié)果提供給用戶。
Storm生態(tài)系統(tǒng)的一大優(yōu)勢(shì)在于其擁有豐富的流類型組合,足以從任何類型的來(lái)源處獲取數(shù)據(jù)。雖然大家也可以針對(duì)某些具備高度特殊性的應(yīng)用程序編寫定制化流,但基本上我們總能從龐大的現(xiàn)有源類型中找到適合需要的方案——從Twitter流API到Apache Kafka再到JMS broker,一切盡皆涵蓋于其中。
適配器的存在使其能夠輕松與HDFS文件系統(tǒng)進(jìn)行集成,這意味著Storm可以在必要時(shí)與Hadoop間實(shí)現(xiàn)互操作。Storm的另一大優(yōu)勢(shì)在于它對(duì)多語(yǔ)言編程方式的支持能力。盡管Storm本身基于Clojure且運(yùn)行在JVM之上,其流與栓仍然能夠通過(guò)幾乎所有語(yǔ)言進(jìn)行編寫,其中包括那些能夠充分發(fā)揮在標(biāo)準(zhǔn)輸入/輸出基礎(chǔ)上使用JSON、并由此實(shí)現(xiàn)組件間通信協(xié)議優(yōu)勢(shì)的非JVM語(yǔ)言。
總體而言,Storm是一套***可擴(kuò)展能力、快速驚人且具備容錯(cuò)能力的開源分布計(jì)算系統(tǒng),其高度專注于流處理領(lǐng)域。Storm在事件處理與增量計(jì)算方面表現(xiàn)突出,能夠以實(shí)時(shí)方式根據(jù)不斷變化的參數(shù)對(duì)數(shù)據(jù)流進(jìn)行處理。盡管Storm同時(shí)提供原語(yǔ)以實(shí)現(xiàn)通用性分布RPC并在理論上能夠被用于任何分布式計(jì)算任務(wù)的組成部分,但其最為根本的優(yōu)勢(shì)仍然表現(xiàn)在事件流處理方面。
Spark:適用于一切的分布式處理方案
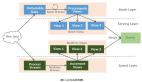
作為另一個(gè)專門面向?qū)崟r(shí)分布式計(jì)算任務(wù)的項(xiàng)目,Spark最初由加州大學(xué)伯克利分校的APMLab實(shí)驗(yàn)室所打造,而后又加入到Apache孵化器項(xiàng)目并最終于2014年2月成為其中的***項(xiàng)目之一。與Storm類似,Spark也支持面向流的處理機(jī)制,不過(guò)這是一套更具泛用性的分布式計(jì)算平臺(tái)。
有鑒于此,我們不妨將Spark視為Hadoop當(dāng)中一套足以取代MapReduce的潛在備選方案——二者的區(qū)別在于,Spark能夠運(yùn)行在現(xiàn)有Hadoop集群之上,但需要依賴于YARN對(duì)于資源的調(diào)度能力。除了Hadoop YARN之外,Spark還能夠以Mesos為基礎(chǔ)實(shí)現(xiàn)同樣的資源調(diào)度或者利用自身內(nèi)置調(diào)度程度作為獨(dú)立集群運(yùn)行。值得注意的是,如果不將Spark與Hadoop配合使用,那么運(yùn)行在集群之上時(shí)某些網(wǎng)絡(luò)/分布式文件系統(tǒng)(包括NFS、AFS等)仍然必要,這樣每個(gè)節(jié)點(diǎn)才能夠切實(shí)訪問(wèn)底層數(shù)據(jù)。
Spark項(xiàng)目由Scala編寫而成,而且與Storm一樣都支持多語(yǔ)言編程——不過(guò)Spark所提供的特殊API只支持Scala、Java以及Python。Spark并不具備“流”這樣的特殊抽象機(jī)制,但卻擁有能夠與存儲(chǔ)在多種不同數(shù)據(jù)源內(nèi)的數(shù)據(jù)實(shí)現(xiàn)協(xié)作的適配器——具體包括HDFS文件、Cassandra、HBase以及S3。
Spark項(xiàng)目的***亮點(diǎn)在于其支持多處理模式以及支持庫(kù)。沒錯(cuò),Spark當(dāng)然支持流模式,但這種支持能力僅源自多個(gè)Spark模塊之一,其預(yù)設(shè)模塊除了流處理之外還支持SQL訪問(wèn)、圖形操作以及機(jī)器學(xué)習(xí)等。
Spark還提供一套極為便利的交互shell,允許用戶利用Scala或者Python API以實(shí)時(shí)方式快速建立起原型及探索性數(shù)據(jù)分析機(jī)制。在使用這套交互shell時(shí),大家會(huì)很快發(fā)現(xiàn)Spark與Storm之間的另一大差異所在:Spark明顯表現(xiàn)出一種偏“功能”的取向,在這里大部分API使用都是由面向原始操作的連續(xù)性方法調(diào)用來(lái)實(shí)現(xiàn)的——這與Storm遵循的模式完全不同,后者更傾向于通過(guò)創(chuàng)建類與實(shí)現(xiàn)接口來(lái)完成此類任務(wù)。先不論兩種方案孰優(yōu)孰劣,單單是風(fēng)格的巨大差異已經(jīng)足以幫助大家決定哪款系統(tǒng)更適合自己的需求了。
與Storm類似,Spark在設(shè)計(jì)當(dāng)中同樣高度重視大規(guī)模可擴(kuò)展能力,而且Spark團(tuán)隊(duì)目前已經(jīng)擁有一份大型用戶文檔、其中列出的系統(tǒng)方案都運(yùn)行著包含成千上萬(wàn)個(gè)節(jié)點(diǎn)的生產(chǎn)性集群。除此之外,Spark還在最近的2014年Daytona GraySort競(jìng)賽當(dāng)中獲得了優(yōu)勝,成為目前承載100TB級(jí)別數(shù)據(jù)工作負(fù)載的***選擇。Spark團(tuán)隊(duì)還保留了多份文檔,其中記錄著Spark ETL如何負(fù)責(zé)數(shù)PB級(jí)別生產(chǎn)工作負(fù)載的運(yùn)營(yíng)。
Spark是一套快速出色、可擴(kuò)展能力驚人且***靈活性的開源分布式計(jì)算平臺(tái),與Hadoop以及Mesos相兼容并且支持多川計(jì)算模式,其中包括流、以圖形為核心的操作、SQL訪問(wèn)外加分布式機(jī)器學(xué)習(xí)等。Spark的實(shí)際擴(kuò)展記錄令人滿意,而且與Storm一樣堪稱構(gòu)建實(shí)時(shí)分析與商務(wù)智能系統(tǒng)的卓越平臺(tái)。
您會(huì)如何選擇
那么大家又該如何在Storm與Spark之間做出選擇呢?
如果大家的需求主要集中在流處理與CEP(即復(fù)雜事件處理)式處理層面,而且需要從零開始為項(xiàng)目構(gòu)建一套目標(biāo)明確的集群設(shè)施,那么我個(gè)人更傾向于選擇Storm——特別是在現(xiàn)有Storm流機(jī)制能夠確切滿足大家集成需求的情況下。這一結(jié)論并不屬于硬性要求或者強(qiáng)制規(guī)則,但上述因素的存在確實(shí)更適合由Storm出面打理。
在另一方面,如果大家打算使用現(xiàn)有Hadoop或者M(jìn)esos集群,而且/或者既定流程需要涉及與圖形處理、SQL訪問(wèn)或者批量處理相關(guān)的其它實(shí)質(zhì)性要求,那么Spark則值得加以優(yōu)先考慮。
另一個(gè)需要考量的因素是兩套系統(tǒng)對(duì)于多語(yǔ)言的支持能力,舉例來(lái)說(shuō),如果大家需要使用由R語(yǔ)言或者其它Spark無(wú)法原生支持的語(yǔ)言所編寫的代碼,那么Storm無(wú)疑在語(yǔ)言支持寬泛性方面占據(jù)優(yōu)勢(shì)。同理可知,如果大家必須利用交互式shell通過(guò)API調(diào)用實(shí)現(xiàn)數(shù)據(jù)探索,那么Spark也能帶來(lái)Storm所不具備的優(yōu)秀能力。
***,大家可能希望在做出決定前再對(duì)兩套平臺(tái)進(jìn)行一番詳盡分析。我建議大家先利用這兩套平臺(tái)各自建立一個(gè)小規(guī)模概念驗(yàn)證項(xiàng)目——而后運(yùn)行自己的基準(zhǔn)工作負(fù)載,借此在最終選擇前親身體驗(yàn)二者的工作負(fù)載處理能力是否與預(yù)期相一致。
當(dāng)然,大家也不一定非要從二者之中選擇其一。根據(jù)各位工作負(fù)載、基礎(chǔ)設(shè)施以及具體要求的不同,我們可能會(huì)找出一種將Storm與Spark加以結(jié)合的理想方案——其它同樣可能發(fā)揮作用的工具還包括Kafka、Hadoop以及Flume等等。而這正是開源機(jī)制的***亮點(diǎn)所在。
無(wú)論大家選擇哪一套方案,這些工具的存在都切實(shí)表明實(shí)時(shí)商務(wù)智能市場(chǎng)的游戲規(guī)則已經(jīng)發(fā)生了變化。曾經(jīng)只能為少數(shù)精英所掌握的強(qiáng)大選項(xiàng)如今已經(jīng)進(jìn)入尋常百姓家——或者說(shuō),至少適用于多數(shù)中等規(guī)模或者大型企業(yè)。不要浪費(fèi)資源,充分享受由此帶來(lái)的便利吧。