代號9527---DNS協議
在周星馳的電影《唐伯虎點秋香》中,周星馳飾演的主角一進入華府,就被強制增加了一個代號9527。從此,華府的人開始稱呼主角為9527,而不是他的姓名。
域名(domain name)是IP地址的代號。域名通常是由字符構成的。對于人類來說,字符構成的域名,比如www.yahoo.com,要比純粹數字構成的IP地址(106.10.170.118)容易記憶。域名解析系統(DNS, domain name system)就負責將域名翻譯為對應的IP地址。在DNS的幫助下,我們可以在瀏覽器的地址欄輸入域名,而不是IP地址。這大大減輕了互聯網用戶的記憶負擔。另一方面,處于維護和運營的原因,一些網站可能會變更IP地址。這些網站可以更改DNS中的對應關系,從而保持域名不變,而IP地址更新。由于大部分用戶記錄的都是域名,這樣就可以降低IP變更帶來的影響。
從機器和技術的角度上來說,域名并不是必須的。但Internet是由機器和用戶共同構成的。鑒于DNS對用戶的巨大幫助,DNS已經被當作TCP/IP套裝不可或缺的一個組成部分。
DNS服務器
域名和IP地址的對應關系存儲在DNS服務器(DNS server)中。所謂的DNS服務器,是指在網絡中進行域名解析的一些服務器(計算機)。這些服務器都有自己的IP地址,并使用DNS協議(DNS protocol)進行通信。DNS協議主要基于UDP,是應用層協議(這也是我們見到的***個應用層協議)。
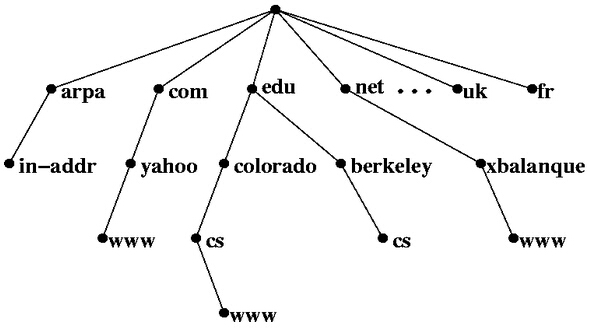
DNS服務器構成一個分級(hierarchical)的樹狀體系。上圖中,每個節點(node)為一個DNS服務器,每個節點都有自己的IP地址。樹的頂端為用戶電腦出口處的DNS服務器。在Linux下,可以使用cat /etc/resolv.conf,在Windows下,可以使用ipconfig /all,來查詢出口DNS服務器。樹的末端是真正的域名/IP對應關系記錄。一次DNS查詢就是從樹的頂端節點出發,最終找到相應末端記錄的過程。
中間節點根據域名的構成,將DNS查詢引導向下一級的服務器。比如說一個域名cs.berkeley.edu,DNS解析會將域名分割為cs, berkeley, edu,然后按照相反的順序查詢(edu, berkeley, cs)。出口DNS首先根據edu,將查詢指向下一層的edu節點。然后edu節點根據berkeley,將查詢指向下一層的berkeley節點。這臺berkeley服務器上存儲有cs.berkeley.edu的IP地址。所以,中間節點不斷重新定向,并將我們引導到正確的記錄。
在整個DNS查詢過程中,無論是重新定向還是最終取得對應關系,都是用戶計算機和DNS服務器使用DNS協議通信。用戶計算機根據DNS服務器的反饋,依次與下一層的DNS服務器建立通信。用戶計算機經過遞歸查詢,最終和末端節點通信,并獲得IP地址。
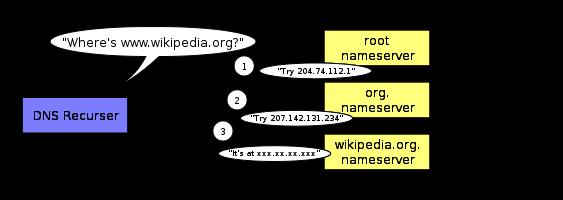
來自wikipedia
緩存
用戶計算機的操作系統中的域名解析模塊(DNS Resolver)負責域名解析的相關工作。任何一個應用程序(郵件,瀏覽器)都可以通過調用該模塊來進行域名解析。
并不是每次域名解析都要完整的經歷解析過程。DNS Resolver通常有DNS緩存(cache),用來記錄最近使用和查詢的域名/IP關系。在進行DNS查詢之前,計算機會先查詢cache中是否有相關記錄。這樣,重復使用的域名就不用總要經過整個遞歸查詢過程。

來自wikipedia
反向DNS
上面的DNS查詢均為正向DNS查詢:已經知道域名,想要查詢對應IP。而反向DNS(reverse DNS)是已經知道IP的前提下,想要查詢域名。反向DNS也是采用分層查詢方式,對于一個IP地址(比如106.10.170.118),依次查詢in-addr.arpa節點(如果是IPv6,則為ip6.arpa節點),106節點,10節點,170節點,并在該節點獲得106.10.170.118對應的域名。
實例
下面的視頻來自youtube,我覺得它很生動的解釋了DNS的工作過程。