Linux優化之IO子系統監控與調優
Linux優化之IO子系統
作為服務器主機來講,***的兩個IO類型 :
1.磁盤IO
2.網絡IO
這是我們調整最多的兩個部分所在
磁盤IO是如何實現的
在內存調優中,一直在講到為了加速性能,linux內核一般情況下都會嘗試將磁盤上的慢速設備上的文件緩存至內存中,從而達到加速效果;
虛擬內存的概念:
讀寫都在內存中完成,當某一進程在cpu運行的時候,進程要訪問自己地址空間中的某一內存頁,當進程需要訪問頁面中的數據,而這個頁面最終是要對應在物理內存中的某個物理頁面,而進程只能看到自己的線性地址空間,而這個地址并不存在,一旦訪問這個地址,那么會通過MMU(內存管理單元)機制中的存儲當前進程的線性地址到物理地址的映射表
由此通過MMU實現對應的地址查詢于是得到了其映射的地址,最終進程雖然訪問的數據是來自于映射過的地址,這種訪問訪問我們被稱為虛擬地址或虛擬內存
如果由于我們使用交換內存或其他方式有可能這個進程所打開的文件長時間沒有被訪問,這個文件所對應的內存已經被清出去了,所以使用mmu地址轉換后的地址對應的數據在內存中不存在了,這時候會產生頁錯誤,我們也被稱為缺頁異常
缺頁異常
缺頁異常分為大異常和小異常:
如果數據不存在使得不得不在磁盤中載入頁面文件,這時CPU就會進入內核模式,訪問磁盤,每次CPU訪問內存就要3個周期,訪問磁盤需要N個周期,首先需要定位數據的準確位置,而后定位物理內存中開辟數據空間,***將數據總線貫通,從而將數據從磁盤轉入到內存--blockin
當我們找一個空閑空間,而事實上當進程訪問這段數據就需要訪問新位置的數據,所以我們要更新這個映射表,明確說明所要訪問的邏輯地址所要對應的空間的轉換的位置,并且讓進程重新發起一次訪問,這時需要先查找TLB(緩存緩沖器),再次進行查表
而將磁盤裝入內存的過程就會發生IO,如果進程修改了數據,最終數據還需要寫到磁盤中去,而寫到磁盤中去,過程使得數據比原來的文件更大了
具體是由文件系統模塊根據進程發起的請求,內核指揮文件系統模塊開辟更多的存儲塊而后將數據存儲,這種過程被稱為 block out
#緩沖器負責將之前緩沖過的緩存下來,那么如果N個條目,而緩沖器只能緩存有限的幾個,那么命中率可能會很低,如果我們使用大頁面的話,那么命中率可以大大提高。
機械硬盤的特性
同一方向的操作是合并起來完成的,而后在這個方向結束之后則是另外一方向的
對硬盤來講,讀寫是不同類型的操作,讀寫是不能同時進行的
磁盤是如何操作的
將一個或多個進程的讀操作合并到一起讀
將一個或多個進程的寫操作合并到一起寫
所以讀寫操作是兩類不同的操作而且是同一方向合并的
如果是讀文件,這個文件一定是來自于磁盤的
如果是寫文件,那么寫入到內存中,對于進程來講是已經完成的,那么用戶對計算機性能感知是來自于讀,因為讀一定是與IO相交互
1.讀是在同方向合并的
2.寫也是需要合并的,而且兩者是不同方向的操作
因為在同一方向可以節省很多資源
讀必須優先滿足,而寫也不能等太久,因此必須有一種良好的算法讓其盡可能都得到滿足,而又不能讓用戶感到性能下降
因此在IO系統上有個非常重要的模塊---IO調度器
IO調度器
用來實現合并同一方向的讀寫操作并且將讀寫操作盡可能理想的這種狀況,IO調度器本身的完成,最終用戶實現寫的時候進程級別所看到的數據是文件接口,那么文件接口輸出的時候就意味著將磁盤空間以文件接口的方式輸出,其需要文件系統,也就意味著進程與磁盤上的數據打交道是依賴文件系統的,所以用戶的請求先到文件系統,而文件系統通過內核輸出是虛擬文件接口(VFS) 通過VFS找到各特定文件系統相關模塊,當然對應的文件是哪個那么則通過vfs轉換成什么即可,文件系統將數據接下來之后,最終存儲為磁盤塊的方式保存在磁盤上,因此這些文件系統最終還要轉換數據為磁盤塊,所以接下來還要有塊層
塊層主要是將數據轉換為磁盤塊格式,而后再由磁盤塊格式轉換成調度以后存儲在磁盤上
如下圖所示:

- (1)用戶進程實現寫操作 實現系統調用
- (2)用戶的寫操作一定是跟VFS進行交互的
- (3)VFS需要將其換換為特定的文件系統
- (4)單個文件在虛擬文件系統存放都會轉換成頁面方式(page cache)
- (5)寫完之后通過block buffer快緩沖(知所以進行緩沖是因為磁盤太慢了,所以寫的時候需要緩沖下來)
- (6)然后由bio將每個page cache轉換成塊,并且在塊緩沖這個層次上緩存下來
#p#
這就是緩沖隊列,而在塊層實現緩沖之后每個塊最終都要交給塊層來處理,塊層中最重要的一個組件就是IO調度器,IO調度器接收blockbuffer中所發送過來的多個請求塊,這多個請求塊需要排序的:同方向合并,圖中都是寫操作的
至于如何排序,一定是最靠近寫請求的***先滿足
而IO調度器主要功能就是將隨機IO盡可能合并為順序IO 本文來自http://yijiu.blog.51cto.com 轉載請說明,翻版可恥
但是我們有說過,盡可能同一方向合并盡可能會隨機變為順序,但是我們又不得不讀饑餓也不能寫饑餓,所以要交替進行的
所以:
(10)由IO調度器調度完成之后,提交給Device Driver ,由Device Driver控制磁盤控制器,由控制器將電器信號轉換為磁信號寫入到磁盤中去
為何隨機讀寫比順序讀寫要慢:
·隨機讀寫:
我們可能寫任意一個磁道的任意一個扇區,那么硬盤磁頭可能來回晃動才能完成一次寫
·順序讀寫:
在一個方向轉動即可完成,不用再去移動磁臂的
磁頭操作是電磁運動,而磁臂操作是機械運動,所以任何時候隨機讀寫性能都比順序讀寫都要差的很多
調度算法
IO調度器事實上是用程序完成的調度算法,對linux來講,2.6的內核一共有4個
1、CFQ
完全公平隊列,比較適合于交互式場景
2、Deadline
***期限,任何一個讀寫請求,都有自己的滿足期限,當期限到來時之前,必須達到需求的滿足(一般建議在數據庫服務器上使用此調度算法)
3、anticpatory
預期的,任何一個數據讀完之后,有可能與其相鄰的數據也可能被讀到,所以它大致所實現的方法就是,讀完之后先不滿足,則不處理,需等一段時間后查看是否有相近數據訪問過,如果有馬上先滿足,所以這只能在行為預估的場景下可用
4、Noop
不排隊不合并,先到先得
#像固態硬盤,因為它不是機械硬盤,它的讀寫就算是隨機IO那么它的性能跟順序IO差別也不是很大,反而如果想讓調度器去調取它的算法,那么調度器本身運行會占用很高的CPU的時鐘周期,有可能會得不償失,所以noop在這種場景下是***的算法
#有些RAID設備控制器在硬件設備上自己就有讀寫操作排序的,也就意味著在硬件級別排好序之后在操作系統級別會將其打散重新排序,得不償失,所以RAID設備有自己的調度器的話,***也使用noop
一般來講,默認是CFQ的
本文來自http://yijiu.blog.51cto.com 轉載請說明,翻版可恥
有時候在不同場景下,他們所***所適用的算法可能不一樣,比如:
如果是web服務器,這里只是訪問放web上的分區的頁面數據
如果是db數據庫,訪問的是db數據庫的文件,他們最適用的算法未必會一樣,因為他們的訪問風格不同,所以這時候我們就需要修改他們的調度器算法
CFQ比較適合于交互式場景,于是在很多時候會將服務器設置為Deadline,當然只是一種假定,具體需要自己測試然后做決定
觀測當前磁盤IO活動
一般 ethstatus iotio pt-ioprofile sar等查工具看哪些進程引起的io比較高等
這里我們使用sar來觀察其狀態信息 本文 來自http://yijiu.blog.51cto.com 轉載 請說明,翻版 可恥
例:
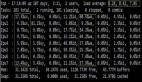
- [root@node3 ~]# sar -d 1 5
- Linux2.6.32-431.20.3.el6.x86_64 (node3.test.com) 09/20/2014 _x86_64_(4 CPU)
- 09:16:00 PM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
- 09:16:01 PM dev252-0 46.46 0.00 46795.96 1007.13 2.65 580.00 2.26 10.51
- 09:16:01 PM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
- 09:16:02 PM dev252-0 3.00 0.00 144.00 48.00 0.00 1.33 1.00 0.30
- 09:16:02 PM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
- 09:16:03 PM dev252-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
- 09:16:03 PM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
- 09:16:04 PM dev252-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
- 09:16:04 PM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
- 09:16:05 PM dev252-0 72.73 0.00 59967.68 824.56 2.61 35.88 1.21 8.79
用參數-p可以打印出sda,hdc等磁盤設備名稱,如果不用參數-p,設備節點則有可能是dev8-0,dev22-0
參數解釋:
tps:每秒從物理磁盤I/O的次數.多個邏輯請求會被合并為一個I/O磁盤請求,一次傳輸的大小是不確定的
rd_sec/s:每秒讀扇區的次數.
avgrq-sz:平均每次設備I/O操作的數據大小(扇區).
avgqu-sz:磁盤請求隊列的平均長度.
await:從請求磁盤操作到系統完成處理,每次請求的平均消耗時間,包括請求隊列等待時間,單位是毫秒(1秒=1000毫秒).(一次完成的任務,它的IO完成的平均耗時)
svctm:系統處理每次請求的平均時間,不包括在請求隊列中消耗的時間,
%util:I/O請求占CPU的百分比,比率越大,說明越飽
我們通常經驗值是:
svctm不超過0.5;
await不超過5;
主要看當前設備
核心要點:
1、tps(iops)越高,但%util越低,說明io能力容量越大
2、await、svctm越低越好,說明io響應延遲很低,iops能力很高
調整buffer,提高性能
無非就是調整隊列數,以及增加預讀數,下面我們來手動做一下
·增加隊列長度
#p#
格式:
/sys/block/vda(特定某設備)/queue/nr_requests
由于我這里跑的是kvm虛機,所以設備號默認都以vdx開頭
默認隊列為128個長度
[root@node3 ~]# cat /sys/block/vda/queue/nr_requests
128
這個值是可以調大一點的
2.增加預讀數
/sys/block/vda(特定某設備)/queue/read_ahead_kb
表示事先預讀數據的kb數,默認也是128
[root@node3 ~]# cat /sys/block/vda/queue/read_ahead_kb
128
這個值也是可以調大的,具體多少自行而定
本文 來自http://yijiu.blog.51cto.com 轉載 請說明,翻版 可恥
CFQ完全公平隊列
IO調度是在各進程之間平均分配的,主要是根據進程的IO需求來講IO能力平均分配調度
所以在交互式環境中,這種方式是比較實用的
但是在RHEL6.4上 它又提供了三個不同的調度等級:
1.實時 RT
2.***效果 BE
3.閑置
我們可以使用ionice命令手動分配調度等級,或者使用iopro_set系統調用編程分配,當然涉及到開發層面了
在實時調度等級和***效果兩個級別都有8個IO等級,
數字越小優先級越高,***效果是默認調度等級 也就是4,不用更改
修改CFQ,以調節其性能
涉及參數文件:/sys/block/vda/queue/iosched/
修改默認調度器算法:
- [root@node3 ~]# cd /sys/block/vda/queue/
- [root@node3 queue]# ls
- add_random hw_sector_size max_hw_sectors_kb minimum_io_size physical_block_size scheduler
- discard_granularity iosched max_sectors_kb nomerges read_ahead_kb unpriv_sgio
- discard_max_bytes iostats max_segments nr_requests rotational
- discard_zeroes_data logical_block_size max_segment_size optimal_io_size rq_affinity
而在其上層目錄里,有一scheduler文件
查看scheduler文件
- [root@node3 queue]# cat scheduler
- noop anticipatory deadline [cfq]
因此更改磁盤IO調度器則去找這個目錄下所對應的scheduler,注意的是,它只是針對每個磁盤進行調整的,如果有多塊磁盤的話則需要對應每個磁盤進行修改
它沒有辦法使用sysctl進行控制,如果想開機生效,只能寫到rc.local 或init腳本中
一旦更改調度算法之后,再來查看目錄中的文件
- [root@node3 queue]# ls /sys/block/vda/queue/iosched/
- back_seek_max fifo_expire_async group_idle low_latency slice_async slice_idle
- back_seek_penalty fifo_expire_sync group_isolation quantum slice_async_rq slice_sync
修改算法
- [root@node3 queue]# echo deadline > scheduler
- [root@node3 queue]# cat scheduler
- noop anticipatory [deadline] cfq
再次觀察iosched目錄,并查看其是否有變化
- [root@node3 queue]# ls/sys/block/vda/queue/iosched/
- fifo_batch front_merges read_expire write_expire writes_starved
所以我們更改調度算法后,每個調度算法在此目錄都有很多可調整參數,每個參數都有值,只不過都表現為其文件內容而已,而每個調度器的值通過修改是可以優化調度器的工作特性的
比如對CFQ來講,有以下幾個值可以調整:
back_seek_max
反向尋道可能有負面影響,負載小的時候可以啟用,否則不要使用反向尋道太多值
back_seek_penal
反向尋道做懲罰,如果不得不使用反向尋道的話,那么必須對其做出一定懲罰,一旦做完懲罰之后,必須要正向尋道更多次數
fifo_expire_async
用來控制異步請求等待時間長度,默認是250毫秒,過期之后無法滿足的異步請求將會被移動到調度隊列中,也就意味著要重新調度。通常這些值不需要調整
fifo_expire_sync
用于同步請求的,
嚴格來講寫操作都是在內存中完成 過周期之后才會同步至硬盤中,站在計算機角度來說這種操作都被稱為異步,而同步則是為了盡可能保證數據會被***時間寫到磁盤上來,數據不會在內存上逗留,直接寫入磁盤
low_latecy
低延遲,簡單來講,每個進程都有可能發起讀寫請求,也就意味著最終滿足用戶讀寫請求是按進程為單位劃分,在滿足這個前提下,需要考慮每個進程都需要得到滿足,所以必須關注每個進程發起IO請求之后最多等待多長時間,如果啟動此值就意味著每個進程只要發起讀寫請求都要盡可能快速得到滿足,默認就啟用了低延遲
在桌面系統環境,低延遲是非常有必要的
quantum
CFQ一次可以發出的IO請求數,一批***可以調度的IO數,限制IO隊列深度的,簡單來說就是定義設備一次可以接收的IO請求的隊列長度,默認為8
增加反而會有負面影響,因此謹慎調整
如果隨機IO請求數非常的多,這個值可以適當調大,如果順序寫非常多,那么不建議調整
#p#
設置IO允許消耗的時間
一次IO請求的操作,一次執行多久,應該執行多久,按理說硬盤只要是沒有損壞,能正常運作,在正常范圍內,那么它就應該寫完、讀完所以我們要定義好每次讀寫請求所***允許消耗的時間,那么就是以下幾個參數的意義了:
slice_async
定義異步寫入的超時值,每次異步寫操作最長時長是多少,默認值為40秒
slice_idle
等待IO請求的閑置時長
slice_sync
定義同步寫入操作超時值,因為同步比較慢,所以其默認值是100秒,因為是從進程直接到磁盤的,所以超時時間會長一點
在桌面環境和在服務環境下,他們如果都使用CFQ調度器,他們工作特性不一定,也就意味著我們關注其背后工作機制參數也不一樣,所以要調整某些值做一些測試的評判
Deadline***期限調度
***期限

如圖所示,其分為了3個隊列,分別是:
- ·讀隊列
- ·寫對列
- ·排序隊列
而后這些隊列都被整合到派發隊列中去而后由磁盤得到滿足,我們從中任何一隊列中選出一個操作得到滿足之前必須要保證這類操作不能超期
簡單來講deadline就是將每個讀寫操作放到隊列的時候都給他一個倒計時的計時器,將倒計時的計時器消耗完之前需要趕緊放到派發隊列中,而后再同步至硬盤
而對服務器來講,這種方式是比較理想的
常用可調參數
fifo_batch
單批發出的讀寫數,在其***期限滿足之前將隊列中的數據拿出并滿足,但有寫操作是需要排序的;默認為16,設置更多的值會獲得更好的流量,但是會增加延遲
比如一批讀為16個,那么我們講其改為32個,那意味著寫的時間會更高
當然所有都取決于測試數據,無論怎么調都不如換一塊SSD硬盤
front_merges
可以將多個請求合并在一起,但是有些請求壓根不連續,不可能被合并在一起,那么我們可以禁止在滿足IO之前進行合并的,禁止合并有可能會帶來隨機讀寫的特性的
但允許合并也有一定的副作用,就是必須花時間去排序
read_expire
每個讀操作必須在多少期限內得到滿足,默認為半秒鐘
write_expire
每個寫操作必須在多久內得到滿足,默認為5秒鐘
#寫操作是可以延遲滿足的
writes_starved
定義一批可以處理多少個讀取批,這個值越高,讀的效果就越好。默認為2,意味著2批讀,一批寫。如果服務器讀多寫少,內存緩沖足夠大,那么可以將其調大
Noop
如果系統與cpu綁定,且使用高速存儲(SSD),這就是***的IO調度程序
只要使用固態硬盤就要將其改為noop
如果調參數的話則需要直接去挑戰/sys/block/vda/queue下的參數,而不是調度器的參數
add_random
其作用是否使用商池
max_sectors_kb
默認發送到磁盤的***請求是多少,默認為512kb。我們知道每個扇區是512字節,那么每次發送512kb 意味著發送N個扇區,我們可以調整或增大減小該值,對于固態硬盤來講不是所謂的扇區概念,由此可調。
在此類情況下建議將max_hw_sectors_kb降低刪除塊大小
我們可以使用壓力測試工具對其做測試,記錄大小從512kb到1MB不等,哪個值的效果好就設置為哪個值,當然壓力測試跟實際場景有出入的,所以要充分考慮環境盡可能模擬真實場景,盡可能要模擬隨機讀寫
nr_request
請求的隊列的值,可以降低其值
rotational
如果是SSD硬盤要將此值設置為0,禁用輪轉模式
rq_affinity
在觸發IO不同的CPU中處理IO,一般來講在同CPU上處理同IO是***的
因為CPU處理的僅僅是中斷而已
因此對于SSD環境中常用的調整參數有:
max_sectors_kb
nr_requests
optimal_io_size
rotational
調整后如何測試性能是否提高
比較常用的硬盤壓力測試工具
·aio-stress
·iozone
·fio
了解磁盤IO活動狀況分析工具
blktrace
磁盤IO瓶頸分析工具
blkparse
gnuplot
本文 來自http://yijiu.blog.51cto.com 轉載 請說明,翻版 可恥
總結:IO優化大致思路
- ·***換SSD
- ·調整raid級別
- ·選擇IO調度器
- ·根據場景選擇合適的文件系統
- ·配置選定調度器的參數
- ·優化結果是否理想,則使用工具進行分析
- ·寫在開機啟動項里