Pinterest采用Redshift實現強大的交互式數據分析
我們最終選用了Redshift,它是基于亞馬遜網絡服務的數據倉庫服務,它增強了我們的交互分析能力,每天盡可能快的導入數以億計的記錄,來確保核心數據源的可用性。Redshift是一個偉大的解決方案,它可以在幾秒鐘內回答問題來保證交互數據分析和快速的原型(然而Hadoop和Hive用來處理每天兆兆字節量級的數據,只能在幾鐘或者幾個小時內給出答案)。
來看看我們在使用Redshift中的一起體驗吧:包括了挑戰和收獲,這只是系統的數億分之一的縮影。
Pinterest采用Redshift實現強大的交互式數據分析
Redshift啟動方便并且相當可靠,然而面對千萬億字節量級的大量數據和快速擴張的組織規模,在生產環境中使用Redshift,我們將會面對一些有趣的挑戰。
挑戰1: 創建100萬億字節量級的ETL完成從Hive到Redshift的轉化
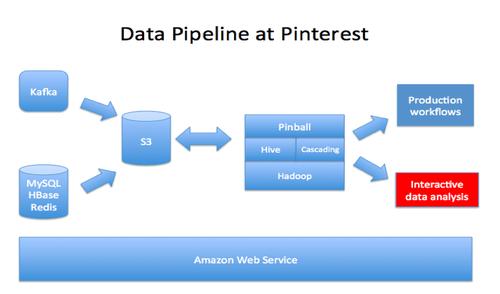
在Hive中有萬億字節量級的數據,它需要我們花一些時間來思考一個***的實踐,如何把100萬億字節的核心數據導入到Redshift中。在Hive中有各種格式的數據,包括了原始的json,Thrift, RCFile,這些都需要轉化成帶有一個平面模式的文本文件。我們用Python撰寫了模式映射的腳本,通過這些腳本生成Hive查詢來處理重量級的ETL。
在Hive中,大部分的表都是時間序列數據且按日期分片。為了保證***結果,我們使用了日期作為排序鍵,每天在各張表后追加數據,從而避免高成本的VACUUM操作。另一種方法是每天使用一張表,通過視圖把它們關聯,但是我們發現Redshift沒有很好的視圖查詢優化的機制(例如,它不能下壓LIMIT)。
加載一張大的快照表同樣是一件具有挑戰的事情。我們***的表db_pins它包括了200億個Pins,在規模上遠不止10TB的數據。在快照表中加載它會導致開銷巨大的分片和排序,因此我們在Hive中做了大量的分片,同時逐塊兒的加載到Redshift中。
由于Redshift只有有限的存儲空間,我們采用表保留的方式去處理大數據的時間序列的表格,通過周期性的運行插入查詢到Redshift中去將有限的數據拷貝到新的表格中,這樣做會比刪除行然后做耗費極高的清空,或者舍棄整個表再重新導入的方法要快得多。
也許***的挑戰是來自于S3最終的一致性。我們發現在Redshift中有時候會有嚴重的丟數據現象,然后追查下來是S3的問題。我們通過綁定一些小的文件的方法來減少在S3上的文件數量,這樣來減少數據丟失。我們同時在ETL的每一步中添加審計,這樣數據丟失率現在通常已經在可以接受的0.0001%以下。
挑戰2:通過Redshift之外的Hives得到100x的速度提升
Redshift生來具備高性能,這使得在原型中對于一些查詢不需要什么額外的努力,我們可通過Hive得到50-100x的提速,然而一旦進入生產環境,它并不總能像測試時那樣與預期的性能相符。
在早期的測試中我們發現一些長達數小時的查詢,調試性能問題是相當棘手的,這需要收集查詢計劃、查詢執行統計等,但是最終它沒有明顯的性能問題。
由此得到的教訓是需要把數據準備好,無論何時更新系統的統計信息是必須的,因為它會極大的影響優化的的工作。為每張表選擇一個好的排序鍵和分區鍵,排序鍵會容易一些,但是糟糕的分區鍵將會歪曲和影響系統的性能。
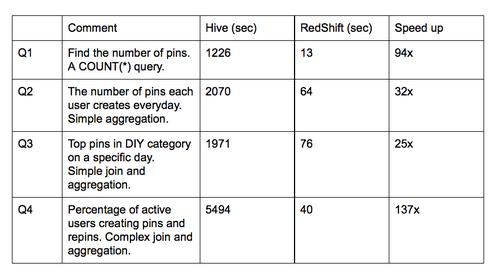
下面是Hive 和Redshift聚簇的基準測試結果,測試基于db_pins(200億行,每行有50個列的,總大小是10TB)和一些其它的核心表。要記得這些比較不包括聚簇大小,資源爭用和其它可能的優化機制,因此比較一點也不科學。
Pinterest采用Redshift實現強大的交互式數據分析
我們也發現了一些常識性的錯誤,總結了我們的***實踐,創建了工具實時的監控速度慢的查詢。耗時超過20分鐘的被視為有嫌疑,工程師們就會收到提醒,來回顧我們遵守的***實踐。

Pinterest采用Redshift實現強大的交互式數據分析
或許最常見的錯誤是趨向于把“Select *” 這樣的內容放在select子句中,這有悖于列存儲,因為它需要掃描全部非必需的列。
挑戰3: 管理不斷增長的查詢/用戶的爭用。
因為性能良好,在我們配置好后,Redshift被廣泛的應用到Pinterest中。我們是一個高速發展的機構,越來越多的人們對并行使用Redshift感興趣,由于大量的查詢爭用資源,查詢的速度明顯的下降。一個代價較大的查詢會占用大量的資源且明顯的影響其它并行的查詢,因此我們需要制定規則來使得爭用最小化。
我們避免在峰值時段(上午9點到下午5點)使用重量級的ETL查詢。ETL查詢和COPY一樣會占用大量的輸入輸出和網絡帶寬,為了保證用戶的交互查詢要避免在這些時段使用ETL查詢。我們優化了ETL的管道使它在峰值時間之前完成,或者暫停管道,在峰值后再恢復。甚至于,在峰值時段暫停用戶交互查詢。可能包含錯誤的長查詢將會被立即停止,而不是讓它浪費資源。
目前狀況
我們建了16個hs1.8xlarge性能的節點。通常在Pinterest上會有100個用戶同時使用Redshift,每天我們運行300到500個交互式的查詢。因為很多查詢都能在幾秒鐘內完成,總體的性能超過了我們的預期。以下是上周交互式查詢的持續百分比。我們可以看到75%的查詢是可以在35秒內完成的。

Pinterest采用Redshift實現強大的交互式數據分析
因為我們成功的使用了Redshift,我們將繼續將其集成到我們下一代的工具中。如果你對這一類的挑戰感興趣,并且有快速的、可擴展的方法,請加入我們的團隊。