Linux實用教程:自動批量掃描文檔
譯文【51CTO精選譯文】本文將為讀者介紹如何構建一套文檔批量掃描系統。為了實現這個目標,我們將使用眾多Linux工具。這種方法具有的優點是,這個過程可以定制,以符合你特定的需求。這為你提供了一套可處理重大任務,又能靈活定制的系統。
我們將著眼于兩種可能的最終產品:每一頁都是原始頁掃描件的PDF文件,以及含有原始頁文本內容的文本文件。文本文件的內容可以搜索,我們探討了將文本文件轉換成PDF文件的若干方法。
本教程具有模塊化特點。比如說,如果你在處理一組預先掃描的圖像,那么就可以略過頭幾個步驟,直接進入到使用光學字符識別(OCR)軟件處理圖像,或者將它們轉換成PDF文件。同樣,如果你偏愛使用圖形用戶界面(GUI)工具來處理這個過程的某些環節,也沒有什么可以阻止你。話雖如此,我們還是盡量讓這個過程的每個環節都可以編寫腳本,以便實現全面自動化。
我們通過充分使用基于命令行的工具,確保這個項目的每個階段都是可以定制、可以編寫腳本。
- 相關資源
- Linux機器
- 掃描儀
- 具體步驟
第1步:安裝SANE
你可以使用程序包管理器,安裝主要的掃描儀程序包SANE(Scanner Access Now Easy)。要是你已安裝了SANE,但是掃描儀訪問起來還是有困難,網上可能有面向該掃描儀的針對特定廠商的SANE后端工具。如果是這種情況,不妨用谷歌搜索一下。
第2步:找到掃描儀
在命令行鍵入scanimage -L命令,檢查一下SANE能否與你的掃描儀兼容。要是你的掃描儀得到支持,文本輸出就會含有設備名稱。你需要的那部分就是冒號前面的第一個元素。
第3步:掃描圖像
鍵入scanimage -d [設備名稱] > test.pnm,快速測試掃描某個對象。這會使用默認設置來掃描一頁內容。在圖形查看器中打開掃描后的文件,檢查一下。要是遇到了問題,可以添加-v選項,以便排查故障。
第4步:完善scanimage選項
如果你打算使用OCR處理文本,或者不需要顏色,那么300 DPI分辨率和黑白是兩個典型的選項。首先,這縮小了文件尺寸。scanimage -d [設備名稱] -format=tiff -mode Lineart -resolution和300 > [文件名稱]是兩個典型的選項。
第5步:創建掃描腳本
我們將使用進行掃描的命令行字符串創建第一個腳本。使用一個文本編輯器,創建一個名為scan.sh的文件。添加#!/bin/bash作為頭一行。添加你所用的掃描儀系列作為第二行。保存該文件。在命令行鍵入chmod +x scan.sh,讓這個腳本成為可執行腳本。將./scan.sh鍵入到終端,以便運行它。接下來,我們在必要的階段可以創建諸如此類的額外腳本。你可以把這些腳本合并成一個長腳本,也可以單獨調用不同的階段。
第6步:計算裁剪尺寸
用不著為這個階段的旋轉文檔而操心。你可以使用程序包管理器,安裝GIMP。在GIMP中打開掃描后文檔,從工具面板中選擇裁剪工具。讓裁剪區覆蓋文檔的有效部分,然后在裁剪對話框中記下裁剪尺寸。如果你打算把迎面頁分割成不同頁面,就要記下適當的頁面尺寸。別在GIMP中進行裁剪,因為我們稍后會從命令行來進行裁剪。
第7步:安裝ImageMagick
使用程序包管理器,將ImageMagick安裝到你的系統上。我們使用convert命令,與這個圖像處理器工具進行交互。我們可以用它來旋轉和裁剪圖像,還可以用它來分割頁面。要注意:convert在選項前面使用了單破折號。
第8步:裁剪頁面
利用通過使用GIMP獲得的相關參數,執行裁剪任務。鍵入convert [圖像名稱] +repage -crop [x width]x[y width]+[x offset]+y[offset] [輸出名稱]。比如說,convert page1.png +repage -crop 2244×3113+1+1 page1_crop.png就會裁剪從上邊和左邊1個像素開始、尺寸為2244 x 3113的矩形頁面。
第9步:旋轉頁面
如果你不得不雙面掃描頁面,不妨使用ImageMagick來旋轉頁面。convert [輸入名稱] -rotate 90 [輸出名稱]可以完成這項任務。
第10步:分割迎面頁
與之前一樣,使用GIMP的裁剪功能,算出裁剪頁面的確切尺寸。convert page1.tiff +repage -crop 2233×1579+0+1529 page1_a.tiff以及隨后的convert page1.tiff +repage -crop 2233×1546+0+0 page1_b.tiff,可以從兩個迎面頁創建兩個不同的文件。
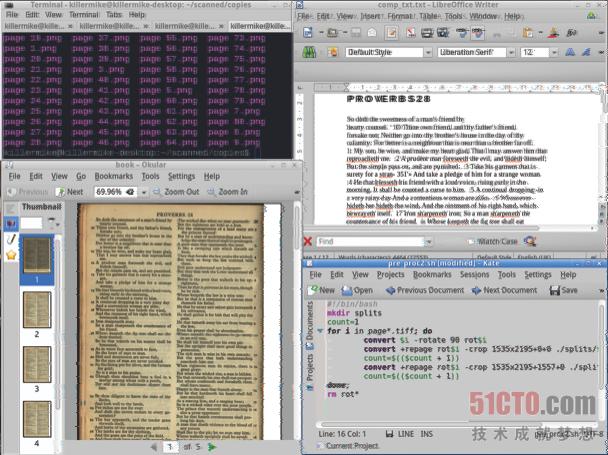
第11步:創建預先處理的腳本
上面是一個示例的預先處理腳本。它創建了一個名為splits的目錄,然后旋轉每個掃描件,之后將其分割成按順序編號的兩個頁面。最后,它刪除經過旋轉的文件。保存它,然后鍵入chmod +x命令,讓它成為可執行腳本。
第12步:掃描儀批處理模式
使用針對多個頁面的-batch系列選項。要是你沒有送紙器,那就添加-batch-prompt選項,以便每次掃描之間加以提示。此外,可以添加-batch=./$page_%03d.tiff,提供以"page"開頭、以帶三個0的數字結尾的文件名稱。
第13步:在掃描儀中預先裁剪
你也許能夠在掃描儀中裁剪頁面,這可以帶來更小的文件和更快的操作,因為掃描頭沒必要掃過很遠的距離。使用GIMP中的裁剪工具,在對話框中將單位由px(像素)改成mm(毫米),算出你所需要的尺寸和偏移量。要是結果證明以這種方式獲得的信息不準確,不妨考慮改用原始的辦法,使用直尺。在scanimage命令行上,額外標志的格式是-l [左邊] -x [寬度] -t [上邊] -y [高度].
第14步:雙面文檔
如果你要掃描雙面文檔,使用之前所說的batch選項,但要添加-batch-double選項,以便將頁面數遞增2個。在第二次掃描時,針對另一面,再次進行同一番操作,不過添加-batch-start=2,讓編號遞增。
第15步:將掃描件轉換成PDF
你可以使用ImageMagick,將裝滿掃描后圖像的目錄轉換成PDF"書冊"。convert *.tiff output.pdf這個命令會創建一個多頁文檔。如果你需要插入標題頁,將其命名為page000.tiff,然后放到該目錄中。
第16步:借助Tesseract,使用OCR處理文本
不妨在測試頁上試一下OCR引擎。為此,鍵入tesseract [輸入文件名稱] [輸出文件]。別給輸出文件名稱添加文件擴展名,因為文件擴展名會由Tesseract來添加。請注意:Tesseract可以檢測出多列文本和迎面頁。
第17步:OCR批處理
使用下列Bash代碼,使用OCR處理裝滿掃描后頁面的目錄:for i in *.tiff ; do tesseract $i outtext$i; done;最終結果是一組文本文件。使用cat *.txt >[輸出文本文件],將這些文件結合起來。
第18步:文本格式化
默認情況下,Tesseract會將回車符插入到之前源文本中出現的同一個位置。你可以使用下面這個命令:fmt -u [輸入文件] > [輸出文件],重新為文本文件制作格式。
第19步:在LibreOffice中編輯文本
只要將從前幾個步驟所得的輸出結果剪貼到LibreOffice Writer中。在這個階段,你可以控制編輯,并手動編輯節頭等參數。你甚至可以插入來自原文檔的圖像。
第20步:從LibreOffice導出PDF文件
LibreOffice有一些內置工具,可用于創建PDF文件。如果你最終敲定了布局和格式,就進入到File(文件)>Export as PDF(導出為PDF文件)。由此處,點擊Export(導出),為文檔取個名稱。
第21步:可以編寫腳本的PDF創建
使用程序包管理器,安裝iconv、ps2pdf和enscript這幾個程序包。鍵入iconv -f UTF-8 -t ISO-8859-1 -c [輸入文本文件][輸出文本文件],準備好文本文件。鍵入enscript [文本文件] -p [輸出postscript文件.ps]。鍵入ps2pdf [.ps文件],將PostScript轉換成PDF。
原文鏈接:http://www.linuxuser.co.uk/tutorials/automatic-mass-scanning-of-documents-tutorial