Storm入門教程 第二章 構(gòu)建Topology
2.1 Storm基本概念
在運(yùn)行一個(gè)Storm任務(wù)之前,需要了解一些概念:
- Topologies
- Streams
- Spouts
- Bolts
- Stream groupings
- Reliability
- Tasks
- Workers
torm集群和Hadoop集群表面上看很類似。但是Hadoop上運(yùn)行的是 MapReduce jobs,而在Storm上運(yùn)行的是拓?fù)洌╰opology),這兩者之間是非常不一樣的。一個(gè)關(guān)鍵的區(qū)別是: 一個(gè)MapReduce job最終會(huì)結(jié)束, 而一個(gè)topology永遠(yuǎn)會(huì)運(yùn)行(除非你手動(dòng)kill掉)。
在Storm的集群里面有兩種節(jié)點(diǎn): 控制節(jié)點(diǎn)(master node)和工作節(jié)點(diǎn)(worker node)。控制節(jié)點(diǎn)上面運(yùn)行一個(gè)叫Nimbus后臺(tái)程序,它的作用類似Hadoop里面的JobTracker。Nimbus負(fù)責(zé)在集群里面分發(fā)代碼, 分配計(jì)算任務(wù)給機(jī)器, 并且監(jiān)控狀態(tài)。
每一個(gè)工作節(jié)點(diǎn)上面運(yùn)行一個(gè)叫做Supervisor的節(jié)點(diǎn)。Supervisor會(huì)監(jiān)聽分配給它那臺(tái)機(jī)器的工作,根據(jù)需要啟動(dòng)/關(guān)閉工作進(jìn)程。每一個(gè)工作進(jìn)程執(zhí)行一個(gè)topology的一個(gè)子集;一個(gè)運(yùn)行的topology由運(yùn)行在很多機(jī)器上的很多工作進(jìn)程組成。
Nimbus和Supervisor之間的所有協(xié)調(diào)工作都是通過Zookeeper集 群完成。另外,Nimbus進(jìn)程和Supervisor進(jìn)程都是快速失敗(fail-fast)和無狀態(tài)的。所有的狀態(tài)要么在zookeeper里面, 要么在本地磁盤上。這也就意味著你可以用kill -9來殺死Nimbus和Supervisor進(jìn)程, 然后再重啟它們,就好像什么都沒有發(fā)生過。這個(gè)設(shè)計(jì)使得Storm異常的穩(wěn)定。
2.1.1 Topologies
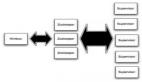
一個(gè)topology是spouts和bolts組成的圖, 通過stream groupings將圖中的spouts和bolts連接起來,如下圖:
一個(gè)topology會(huì)一直運(yùn)行直到你手動(dòng)kill掉,Storm自動(dòng)重新分配執(zhí)行失敗的任務(wù), 并且Storm可以保證你不會(huì)有數(shù)據(jù)丟失(如果開啟了高可靠性的話)。如果一些機(jī)器意外停機(jī)它上面的所有任務(wù)會(huì)被轉(zhuǎn)移到其他機(jī)器上。
運(yùn)行一個(gè)topology很簡單。首先,把你所有的代碼以及所依賴的jar打進(jìn)一個(gè)jar包。然后運(yùn)行類似下面的這個(gè)命令:
storm jar all-my-code.jar backtype.storm.MyTopology arg1 arg2
這個(gè)命令會(huì)運(yùn)行主類: backtype.strom.MyTopology, 參數(shù)是arg1, arg2。這個(gè)類的main函數(shù)定義這個(gè)topology并且把它提交給Nimbus。storm jar負(fù)責(zé)連接到Nimbus并且上傳jar包。
Topology的定義是一個(gè)Thrift結(jié)構(gòu),并且Nimbus就是一個(gè)Thrift服務(wù), 你可以提交由任何語言創(chuàng)建的topology。上面的方面是用JVM-based語言提交的最簡單的方法。
2.1.2 Streams
消息流stream是storm里的關(guān)鍵抽象。一個(gè)消息流是一個(gè)沒有邊界的tuple 序列, 而這些tuple序列會(huì)以一種分布式的方式并行地創(chuàng)建和處理。通過對stream中tuple序列中每個(gè)字段命名來定義stream。在默認(rèn)的情況 下,tuple的字段類型可以是:integer,long,short, byte,string,double,float,boolean和byte array。你也可以自定義類型(只要實(shí)現(xiàn)相應(yīng)的序列化器)。
每個(gè)消息流在定義的時(shí)候會(huì)被分配給一個(gè)id,因?yàn)閱蜗蛳⒘魇褂玫南喈?dāng)普遍, OutputFieldsDeclarer定義了一些方法讓你可以定義一個(gè)stream而不用指定這個(gè)id。在這種情況下這個(gè)stream會(huì)分配個(gè)值為‘default’默認(rèn)的id 。
Storm提供的最基本的處理stream的原語是spout和bolt。你可以實(shí)現(xiàn)spout和bolt提供的接口來處理你的業(yè)務(wù)邏輯。
#p#
2.1.3 Spouts
消息源spout是Storm里面一個(gè)topology里面的消息生產(chǎn)者。一般來說消 息源會(huì)從一個(gè)外部源讀取數(shù)據(jù)并且向topology里面發(fā)出消息:tuple。Spout可以是可靠的也可以是不可靠的。如果這個(gè)tuple沒有被 storm成功處理,可靠的消息源spouts可以重新發(fā)射一個(gè)tuple, 但是不可靠的消息源spouts一旦發(fā)出一個(gè)tuple就不能重發(fā)了。
消息源可以發(fā)射多條消息流stream。使用OutputFieldsDeclarer.declareStream來定義多個(gè)stream,然后使用SpoutOutputCollector來發(fā)射指定的stream。
Spout類里面最重要的方法是nextTuple。要么發(fā)射一個(gè)新的tuple到topology里面或者簡單的返回如果已經(jīng)沒有新的tuple。要注意的是nextTuple方法不能阻塞,因?yàn)閟torm在同一個(gè)線程上面調(diào)用所有消息源spout的方法。
另外兩個(gè)比較重要的spout方法是ack和fail。storm在檢測到一個(gè)tuple被整個(gè)topology成功處理的時(shí)候調(diào)用ack,否則調(diào)用fail。storm只對可靠的spout調(diào)用ack和fail。
2.1.4 Bolts
所有的消息處理邏輯被封裝在bolts里面。Bolts可以做很多事情:過濾,聚合,查詢數(shù)據(jù)庫等等。
Bolts可以簡單的做消息流的傳遞。復(fù)雜的消息流處理往往需要很多步驟,從而也就需 要經(jīng)過很多bolts。比如算出一堆圖片里面被轉(zhuǎn)發(fā)最多的圖片就至少需要兩步:***步算出每個(gè)圖片的轉(zhuǎn)發(fā)數(shù)量。第二步找出轉(zhuǎn)發(fā)最多的前10個(gè)圖片。(如果 要把這個(gè)過程做得更具有擴(kuò)展性那么可能需要更多的步驟)。
Bolts可以發(fā)射多條消息流, 使用OutputFieldsDeclarer.declareStream定義stream,使用OutputCollector.emit來選擇要發(fā)射的stream。
Bolts的主要方法是execute, 它以一個(gè)tuple作為輸入,bolts使用OutputCollector來發(fā)射tuple,bolts必須要為它處理的每一個(gè)tuple調(diào)用 OutputCollector的ack方法,以通知Storm這個(gè)tuple被處理完成了,從而通知這個(gè)tuple的發(fā)射者spouts。 一般的流程是: bolts處理一個(gè)輸入tuple, 發(fā)射0個(gè)或者多個(gè)tuple, 然后調(diào)用ack通知storm自己已經(jīng)處理過這個(gè)tuple了。storm提供了一個(gè)IBasicBolt會(huì)自動(dòng)調(diào)用ack。
2.1.5 Stream groupings
定義一個(gè)topology的其中一步是定義每個(gè)bolt接收什么樣的流作為輸入。stream grouping就是用來定義一個(gè)stream應(yīng)該如果分配數(shù)據(jù)給bolts上面的多個(gè)tasks。
Storm里面有7種類型的stream grouping
- Shuffle Grouping: 隨機(jī)分組, 隨機(jī)派發(fā)stream里面的tuple,保證每個(gè)bolt接收到的tuple數(shù)目大致相同。
- Fields Grouping:按字段分組, 比如按userid來分組, 具有同樣userid的tuple會(huì)被分到相同的Bolts里的一個(gè)task, 而不同的userid則會(huì)被分配到不同的bolts里的task。
- All Grouping:廣播發(fā)送,對于每一個(gè)tuple,所有的bolts都會(huì)收到。
- Global Grouping:全局分組, 這個(gè)tuple被分配到storm中的一個(gè)bolt的其中一個(gè)task。再具體一點(diǎn)就是分配給id值***的那個(gè)task。
- Non Grouping:不分組,這個(gè)分組的意思是說stream不關(guān)心到底誰會(huì)收到它的tuple。目前這種分組和Shuffle grouping是一樣的效果, 有一點(diǎn)不同的是storm會(huì)把這個(gè)bolt放到這個(gè)bolt的訂閱者同一個(gè)線程里面去執(zhí)行。
- Direct Grouping: 直接分組, 這是一種比較特別的分組方法,用這種分組意味著消息的發(fā)送者指定由消息接收者的哪個(gè)task處理這個(gè)消息。 只有被聲明為Direct Stream的消息流可以聲明這種分組方法。而且這種消息tuple必須使用emitDirect方法來發(fā)射。消息處理者可以通過 TopologyContext來獲取處理它的消息的task的id (OutputCollector.emit方法也會(huì)返回task的id)。
- Local or shuffle grouping:如果目標(biāo)bolt有一個(gè)或者多個(gè)task在同一個(gè)工作進(jìn)程中,tuple將會(huì)被隨機(jī)發(fā)生給這些tasks。否則,和普通的Shuffle Grouping行為一致。
2.1.6 Reliability
Storm保證每個(gè)tuple會(huì)被topology完整的執(zhí)行。Storm會(huì)追蹤由每 個(gè)spout tuple所產(chǎn)生的tuple樹(一個(gè)bolt處理一個(gè)tuple之后可能會(huì)發(fā)射別的tuple從而形成樹狀結(jié)構(gòu)),并且跟蹤這棵tuple樹什么時(shí)候成 功處理完。每個(gè)topology都有一個(gè)消息超時(shí)的設(shè)置,如果storm在這個(gè)超時(shí)的時(shí)間內(nèi)檢測不到某個(gè)tuple樹到底有沒有執(zhí)行成功, 那么topology會(huì)把這個(gè)tuple標(biāo)記為執(zhí)行失敗,并且過一會(huì)兒重新發(fā)射這個(gè)tuple。
為了利用Storm的可靠性特性,在你發(fā)出一個(gè)新的tuple以及你完成處理一個(gè) tuple的時(shí)候你必須要通知storm。這一切是由OutputCollector來完成的。通過emit方法來通知一個(gè)新的tuple產(chǎn)生了,通過 ack方法通知一個(gè)tuple處理完成了。
Storm的可靠性我們在第四章會(huì)深入介紹。
2.1.7 Tasks
每一個(gè)spout和bolt會(huì)被當(dāng)作很多task在整個(gè)集群里執(zhí)行。每一個(gè) executor對應(yīng)到一個(gè)線程,在這個(gè)線程上運(yùn)行多個(gè)task,而stream grouping則是定義怎么從一堆task發(fā)射tuple到另外一堆task。你可以調(diào)用TopologyBuilder類的setSpout和 setBolt來設(shè)置并行度(也就是有多少個(gè)task)。
2.1.8 Workers
一個(gè)topology可能會(huì)在一個(gè)或者多個(gè)worker(工作進(jìn)程)里面執(zhí)行,每個(gè) worker是一個(gè)物理JVM并且執(zhí)行整個(gè)topology的一部分。比如,對于并行度是300的topology來說,如果我們使用50個(gè)工作進(jìn)程來執(zhí) 行,那么每個(gè)工作進(jìn)程會(huì)處理其中的6個(gè)tasks。Storm會(huì)盡量均勻的工作分配給所有的worker。
2.1.9 Configuration
Storm里面有一堆參數(shù)可以配置來調(diào)整Nimbus, Supervisor以及正在運(yùn)行的topology的行為,一些配置是系統(tǒng)級(jí)別的,一些配置是topology級(jí)別的。default.yaml里面有 所有的默認(rèn)配置。你可以通過定義個(gè)storm.yaml在你的classpath里來覆蓋這些默認(rèn)配置。并且你也可以在代碼里面設(shè)置一些topology 相關(guān)的配置信息(使用StormSubmitter)。
#p#
2.2 構(gòu)建Topology
1. 實(shí)現(xiàn)的目標(biāo):
我們將設(shè)計(jì)一個(gè)topology,來實(shí)現(xiàn)對一個(gè)句子里面的單詞出現(xiàn)的頻率進(jìn)行統(tǒng)計(jì)。這是一個(gè)簡單的例子,目的是讓大家對于topology快速上手,有一個(gè)初步的理解。
2. 設(shè)計(jì)Topology結(jié)構(gòu):
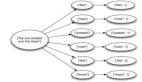
在開始開發(fā)Storm項(xiàng)目的***步,就是要設(shè)計(jì)topology。確定好你的數(shù)據(jù)處理邏輯,我們今天將的這個(gè)簡單的例子,topology也非常簡單。整個(gè)topology如下:
整個(gè)topology分為三個(gè)部分:
KestrelSpout:數(shù)據(jù)源,負(fù)責(zé)發(fā)送sentence
Splitsentence:負(fù)責(zé)將sentence切分
Wordcount:負(fù)責(zé)對單詞的頻率進(jìn)行累加
3. 設(shè)計(jì)數(shù)據(jù)流
這個(gè)topology從kestrel queue讀取句子,并把句子劃分成單詞,然后匯總每個(gè)單詞出現(xiàn)的次數(shù),一個(gè)tuple負(fù)責(zé)讀取句子,每一個(gè)tuple分別對應(yīng)計(jì)算每一個(gè)單詞出現(xiàn)的次數(shù),大概樣子如下所示:
4. 代碼實(shí)現(xiàn):
1) 構(gòu)建maven環(huán)境:
為了開發(fā)storm topology, 你需要把storm相關(guān)的jar包添加到classpath里面去: 要么手動(dòng)添加所有相關(guān)的jar包, 要么使用maven來管理所有的依賴。storm的jar包發(fā)布在Clojars(一個(gè)maven庫), 如果你使用maven的話,把下面的配置添加在你項(xiàng)目的pom.xml里面。
- <repository>
- <id>clojars.org</id>
- <url>http://clojars.org/repo</url>
- </repository>
- <dependency>
- <groupId>storm</groupId>
- <artifactId>storm</artifactId>
- <version>0.5.3</version>
- <scope>test</scope>
- </dependency>
2) 定義topology:
- TopologyBuilder builder = new TopologyBuilder();
- builder.setSpout(1, new KestrelSpout(“kestrel.backtype.com”,22133,
- ”sentence_queue”,
- new StringScheme()));
- builder.setBolt(2, new SplitSentence(), 10)
- .shuffleGrouping(1);
- builder.setBolt(3, new WordCount(), 20)
- .fieldsGrouping(2, new Fields(“word”));
這種topology的spout從句子隊(duì)列中讀取句子,在kestrel.backtype.com位于一個(gè)Kestrel的服務(wù)器端口22133。
Spout用setSpout方法插入一個(gè)獨(dú)特的id到topology。 Topology中的每個(gè)節(jié)點(diǎn)必須給予一個(gè)id,id是由其他bolts用于訂閱該節(jié)點(diǎn)的輸出流。 KestrelSpout在topology中id為1。
setBolt是用于在Topology中插入bolts。 在topology中定義的第一個(gè)bolts 是切割句子的bolts。 這個(gè)bolts 將句子流轉(zhuǎn)成成單詞流。
#p#
讓我們看看SplitSentence實(shí)施:
- public class SplitSentence implements IBasicBolt{
- public void prepare(Map conf, TopologyContext context) {
- }
- public void execute(Tuple tuple, BasicOutputCollector collector) {
- String sentence = tuple.getString(0);
- for(String word: sentence.split(“ ”)) {
- collector.emit(new Values(word));
- }
- }
- public void cleanup() {
- }
- public void declareOutputFields(OutputFieldsDeclarer declarer) {
- declarer.declare(new Fields(“word”));
- }
- }
關(guān)鍵的方法是 execute方法。 正如你可以看到,它將句子拆分成單詞,并發(fā)出每個(gè)單詞作為一個(gè)新的元組。 另一個(gè)重要的方法是declareOutputFields,其中宣布bolts輸出元組的架構(gòu)。 在這里宣布,它發(fā)出一個(gè)域?yàn)閣ord的元組
setBolt的***一個(gè)參數(shù)是你想為bolts的并行量。 SplitSentence bolts 是10個(gè)并發(fā),這將導(dǎo)致在storm集群中有十個(gè)線程并行執(zhí)行。 你所要做的的是增加bolts的并行量在遇到topology的瓶頸時(shí)。
setBolt方法返回一個(gè)對象,用來定義bolts的輸入。 例如,SplitSentence螺栓訂閱組件“1”使用隨機(jī)分組的輸出流。 “1”是指已經(jīng)定義KestrelSpout。 我將解釋在某一時(shí)刻的隨機(jī)分組的一部分。 到目前為止,最要緊的是,SplitSentence bolts會(huì)消耗KestrelSpout發(fā)出的每一個(gè)元組。
#p#
下面在讓我們看看wordcount的實(shí)現(xiàn):
- public class WordCount implements IBasicBolt {
- private Map<String, Integer> _counts = new HashMap<String, Integer>();
- public void prepare(Map conf, TopologyContext context) {
- }
- public void execute(Tuple tuple, BasicOutputCollector collector) {
- String word = tuple.getString(0);
- int count;
- if(_counts.containsKey(word)) {
- count = _counts.get(word);
- } else {
- count = 0;
- }
- count++;
- _counts.put(word, count);
- collector.emit(new Values(word, count));
- }
- public void cleanup() {
- }
- public void declareOutputFields(OutputFieldsDeclarer declarer) {
- declarer.declare(new Fields(“word”, “count”));
- }
- }
SplitSentence對于句子里面的每個(gè)單詞發(fā)射一個(gè)新的tuple, WordCount在內(nèi)存里面維護(hù)一個(gè)單詞->次數(shù)的mapping, WordCount每收到一個(gè)單詞, 它就更新內(nèi)存里面的統(tǒng)計(jì)狀態(tài)。
5. 運(yùn)行Topology
storm的運(yùn)行有兩種模式: 本地模式和分布式模式.
1) 本地模式:
storm用一個(gè)進(jìn)程里面的線程來模擬所有的spout和bolt. 本地模式對開發(fā)和測試來說比較有用。 你運(yùn)行storm-starter里面的topology的時(shí)候它們就是以本地模式運(yùn)行的, 你可以看到topology里面的每一個(gè)組件在發(fā)射什么消息。
2) 分布式模式:
storm由一堆機(jī)器組成。當(dāng)你提交topology給master的時(shí)候, 你同時(shí)也把topology的代碼提交了。master負(fù)責(zé)分發(fā)你的代碼并且負(fù)責(zé)給你的topolgoy分配工作進(jìn)程。如果一個(gè)工作進(jìn)程掛掉了, master節(jié)點(diǎn)會(huì)把認(rèn)為重新分配到其它節(jié)點(diǎn)。
3) 下面是以本地模式運(yùn)行的代碼:
- Config conf = new Config();
- conf.setDebug(true);
- conf.setNumWorkers(2);
- LocalCluster cluster = new LocalCluster();
- cluster.submitTopology(“test”, conf, builder.createTopology());
- Utils.sleep(10000);
- cluster.killTopology(“test”);
- cluster.shutdown();
首先, 這個(gè)代碼定義通過定義一個(gè)LocalCluster對象來定義一個(gè)進(jìn)程內(nèi)的集群。提交topology給這個(gè)虛擬的集群和提交topology給分布式集群是一樣的。通過調(diào)用submitTopology方法來提交topology, 它接受三個(gè)參數(shù):要運(yùn)行的topology的名字,一個(gè)配置對象以及要運(yùn)行的topology本身。
topology的名字是用來唯一區(qū)別一個(gè)topology的,這樣你然后可以用這個(gè)名字來殺死這個(gè)topology的。前面已經(jīng)說過了, 你必須顯式的殺掉一個(gè)topology, 否則它會(huì)一直運(yùn)行。
Conf對象可以配置很多東西, 下面兩個(gè)是最常見的:
TOPOLOGY_WORKERS(setNumWorkers) 定義你希望集群分配多少個(gè)工作進(jìn)程給你來執(zhí)行這個(gè)topology. topology里面的每個(gè)組件會(huì)被需要線程來執(zhí)行。每個(gè)組件到底用多少個(gè)線程是通過setBolt和setSpout來指定的。這些線程都運(yùn)行在工作進(jìn)程里面. 每一個(gè)工作進(jìn)程包含一些節(jié)點(diǎn)的一些工作線程。比如, 如果你指定300個(gè)線程,60個(gè)進(jìn)程, 那么每個(gè)工作進(jìn)程里面要執(zhí)行6個(gè)線程, 而這6個(gè)線程可能屬于不同的組件(Spout, Bolt)。你可以通過調(diào)整每個(gè)組件的并行度以及這些線程所在的進(jìn)程數(shù)量來調(diào)整topology的性能。
TOPOLOGY_DEBUG(setDebug), 當(dāng)它被設(shè)置成true的話, storm會(huì)記錄下每個(gè)組件所發(fā)射的每條消息。這在本地環(huán)境調(diào)試topology很有用, 但是在線上這么做的話會(huì)影響性能的。
結(jié)論:
本章從storm的基本對象的定義,到廣泛的介紹了storm的開發(fā)環(huán)境,從一個(gè)簡單的例子講解了topology的構(gòu)建和定義。希望大家可以從本章的內(nèi)容對storm有一個(gè)基本的理解和概念,并且已經(jīng)可以構(gòu)建一個(gè)簡單的topology!!
原文鏈接:http://blog.linezing.com/2013/01/storm%E5%85%A5%E9%97%A8%E6%95%99%E7%A8%8B-%E7%AC%AC%E