命中率80%,磁盤I/O減半,Flashcache的發展史
***版發布的3年后,Facebook開源了新版Flashcache。對比舊版本,新版本緩存命中率由原來的60%提升到80%,磁盤讀寫更減少了一半。 近日該公司數據庫工程師Domas Mituzas撰文盤點了Flashcache在Facebook的發展歷程,以下為譯文:
Flashcache 在 Facebook 的歷史
Facebook 于2010年***使用Fashcache。那時,工程師仍在做基于SAS或SATA硬盤和完全基于閃存方案的選擇。然而,這兩個方案都不盡人意:2010年,SATA讀寫慢,SAS需要很多硬盤,而閃存的價格又居高不下。
其中一個可行的方法就是把我們的數據庫分成多層——一部分處理請求最多的數據,這些層需要高性能的硬件設備做支撐,而在需求較少冷數據的處理上,性能低的設備也能跑起來。當時,這種方法在技術是可行的,因為我們的數據存取模式呈現為典型的Zipfian分布:即使我們使用了很多RAM緩存機制(memcache、TAO、InnoDB 緩沖池),通常熱數據的存取要高出普通數據10倍。但缺點是該方法卻相對復雜,依當時的數據規模,額外增加復雜性顯然不是一個明智的選擇。
2010年,我們嗅到了從軟件層解決這個問題的機會。于是評估了直接在InnoDB中為L2緩存增加支持的可行性,結果發現為MySQL等設備加緩存效果會更理想。因此,選擇把Flashcache做成Linux內核設備映射模塊,并大規模地將其部署到生產環境。
性能分析和優化
在隨后的幾年中,系統的性能狀況發生了變化:借助InnoDB 的壓縮性能,我們存儲更多的邏輯數據,它們通常要求較高的IOPS;隨后一些舊數據被遷移到其他層,并進行了相應的優化,在不影響正常讀取的前提下盡可能使其少占空間。隨后因負載需求磁盤IO也不斷增加,某些服務器上的硬盤IO限制達到飽和。鑒于此,深入探究生產環境中的Flashcache的性能也被提上臺面,我們開始查看性能進一步提升的可能。
不同類型磁盤驅動器運行特性由多個因素決定,其中包括了硬盤轉速、磁頭速度以及每一轉所讀取的次數等。過去,SATA硬盤性能普遍不敵企業版SAS組件,因此,就像到了優化軟件棧來提升系統性能。
雖然在很多情況下,“iostat”之類的工具對理解系統的整體性能有所幫助,但是卻無助于深層次的研究。這里使用了Linux的blktrace工具來跟蹤數據庫軟件發起的每一次請求,并分析閃存、硬件緩存機制如何處理這些請求。從而得到了3處可以提升的地方:讀寫分布、緩存回收和高效地寫操作。
1. 讀寫分布
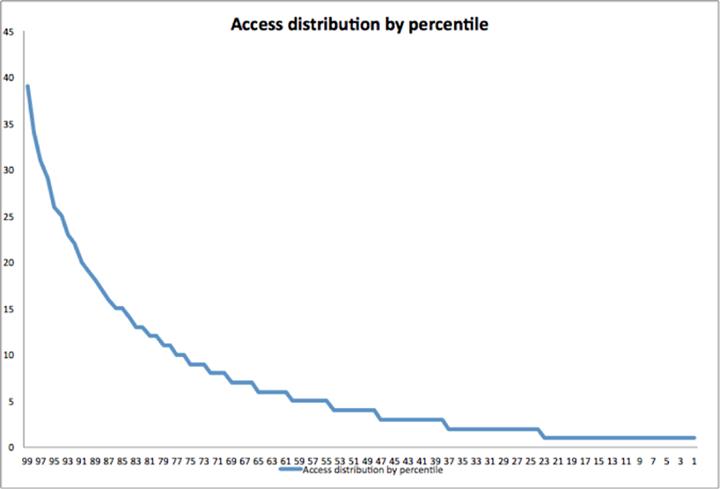
通過分析后發現寫操作集中在硬盤上的少數區域,而讀操作分布很不均勻。我們在Flashcache中增加了更多的設備來監控工作負載,以更好地測量緩存行為。從高層次上看,情況大抵是這樣的:
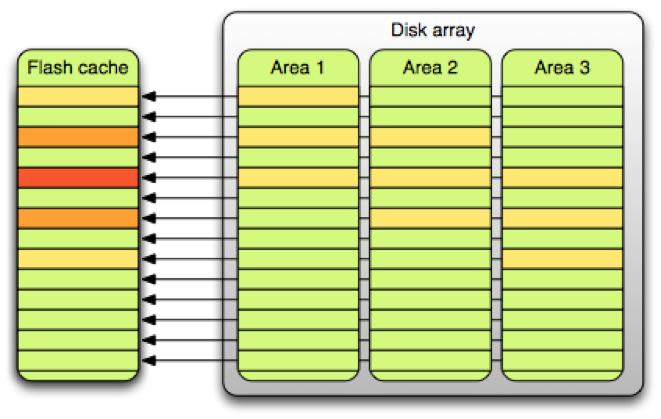
為了簡化緩存維護操作,緩存設備被分割為許多大小為2M的單元,總體存儲中2M大小的部分線性映射到緩存。然而,這種架構導致熱點表排列在相同的緩存單元上,冷表則占用了其它閑置的單元。(這與“生日悖論”沒有什么不同,“生日悖論”指的是與大多數人的期望相反的是——兩人生日是同一天的概率要達到50%的話,至少要有23個人。)
要解決這個問題,要么是有好的配置算法能夠將小塊緩存考慮在內,或是增加某一單元內的數據類型。經過簡單的策略調整后,果斷的選擇了后一個方案。
將硬盤端的相關數據從2M降至256K (使用RAID陣列)
將閃存端的相關數據從2M增加到16M(每單元為4096頁而不是512頁)
用隨機哈希取代替線性映射
以上變動將熱數據打散至更多的緩存區域。下圖顯示了這樣做帶來的好處:
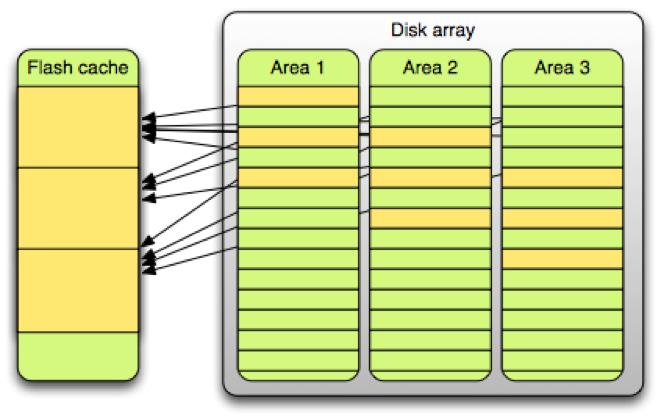
變動前,50%的緩存“貢獻”了80%的硬盤操作。而變動后,同比例的緩存,硬盤操作僅為50%。
2. 緩存回收
在Facebook,數據庫服務器使用小型的邏輯塊——壓縮過的InnoDB表僅用4或8K,而未壓縮過的用16K大小的邏輯塊。用2M大小的緩存單元的話,各緩存回收算法,FIFO和LRU,并沒有明顯差別。z在增加Flashcache單元大小后,工作負載隨之改變,因此不得不開始尋找FIFO的替代方案。
由于使用了blktrace子系統提供的跟蹤功能,因此不再需要實現整套機制來為不同的緩存回收算法的表現建模。回收算法通常非常簡單——因為它們要管理所有經過緩存的動作,它們不得不簡單有效。用Python寫的LRU裝飾器僅有不到20行代碼,加上中點插入功能不過是增加了15行代碼( 示例)。最終我們寫了簡單的模擬器來為回收算法在我們的數據集上的不同表現建模。我們發現帶中點插入功能的LRU較為有效——但是我們仍然需要確定LRU中的***中點以插入新讀入的數據塊。
我們發現被多次引用的數據塊由中點移到了LRU的頭部。如果在***次被讀取時,把這些數據塊置于LRU的頭部,很多只讀一次的數據塊將會把讀操作更頻繁的頁面推出LRU。如果我們把它們置于LRU的中部,它們將處于第50百分位。如果我們把它們置于頭部,它們將處于0百分位。如圖所示,插入點至少要到第85百分位,緩存才有效。
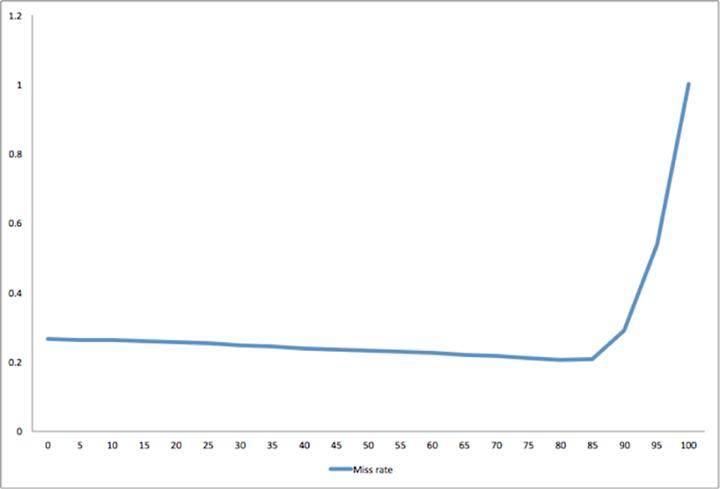
這種行為是基于特定工作負載的,理解這一點有助于提升Flashcache的效率。當前,我們使用Flashcache時是在第75百分位使用中點(實現為LRU-2Q)插入單元。該設置有些保守,它允許25%的舊頁面存在,但仍然要比標準的LRU要出色,因為重構、遷移等緩存行為在先前的建模中是沒有考慮在內。
在Facebook,每臺機器上運行多個數據庫實例,我們優先選用運行時間最長的實例的舊表區域,對新表則謹慎對待。
3. 寫操作的效率
另一個需要解決的問題是寫操作效率。Flashcache能夠充當可靠的寫入前高速緩存,對硬盤的很多寫操作可以事先合并到閃存中。
之前,我們嘗試固定每緩存單元的臟頁占比。由于不同的緩存單元有不同的行為,在這種模型下,我們最終會為修改過的頁面配置underallocating或overallocating緩存。有些部分被不停地寫入,有的臟頁被緩存一周,這嚴重影響了讀緩存。
為了解決這個問題,我們實現了不再分離讀寫操作的臟數據回收方法。所有的數據同等對待,如果緩存要重用一頁面,它只須查找LRU中最舊的那頁即可。如果最舊的頁面是臟的,緩存調用后臺的回收算法回收該頁面,重用次舊頁來緩存新數據。
在***化地保留寫入前高速緩存的寫-合并效率和速寫能力的同時,解決了寫操作問題。它還增加了可用于讀操作的空間,并從整體上提升了緩存效率。
未來工作
實現了以上三處改進,目光被投到未來的工作上。首先調整了元數據結構來提升數據讀取的效率,但是要讓Flashcache支持下一代建立在TB級的緩存設備和硬盤存儲的系統,仍然存在許多挑戰。為了支持多核CPU的并行數據讀取,細粒度鎖機制的開發也正在進行中。
同時,雖然每G閃存的價格在下降,但離理想區間還有段距離。價格下降也對容量規劃帶來了挑戰。SSD寫次數有限,這里還必須確保寫的次數不會超過上限。將數據寫入閃存時,緩存的數據會丟失,所以使用太小的閃存設備存在隱患。在這種情況下,***使用轉速不要太快的硬盤,因為任何緩存層級取決于多層間的巨大的性能差距。
有了這些改進,Flashcache已經成為Facebook軟件棧的構建模塊。我們在新的分支上跑成千上萬的服務器,其性能自flashcache-1系列有大幅提高。我們最繁忙的系統的讀操作I/O下降了40%,寫操作I/O下降了75%。自此,高效地服務于10億用戶只須輕彈一內核模塊。flashcache-3系列的代碼已經提交到 GitHub。