













優化技巧分享:把內存消耗降低至原來的1/20
這是最近發生的又一起內存相關的事件了。這個案例是從一個最近的客戶報告中提取出來,一個異常運行的應用在其產品中反復報告內存耗盡。
這個癥狀是由我們的一個實驗性功能發現,它主要用來監測某一類數據結構的使用情況。它提供了一個信號探針,結果會指向問題源代碼的某一位置。為了保護客戶的隱私,我們人為重建了該例子并保持它同原真實場景在技術層面的一致性。你可以免費在此處下載到源碼。
故事開始于一組從外界源加載進來的對象。同外部的信息交互是基于XML的接口,這本身并沒什么大不了的,但事實上“基于XML的格式進行通訊”的實現細節被分散到了系統的每一個角落。 傳入系統的文檔是首先被轉換成XMLBean實例,然后在整個系統范圍內被使用,這中做法聽起來有點傻。
整個問題中最核心的部分是一個延遲加載的緩沖方案。緩存的對象是“Person”的實例:
- // Imports and methods removed to improve readability
- public class Person {
- private String id;
- private Date dateOfBirth;
- private String forename;
- private String surname;
- }
你也許會說這才能消耗多少內存呢。但當我們揭開進一步的細節時,發現事情就變了味了。表面上根據設計,聲稱實現只用到的諸如上文提到的那樣一些簡單的類,但真實的情形是使用了基于模型生成的數據結構。使用的模型是諸如下面的這個簡化的XSD片段。
- <xs:schema targetNamespace="http://plumbr.eu"
- xmlns:xs="http://www.w3.org/2001/XMLSchema"
- elementFormDefault="qualified">
- <xs:element name="person">
- <xs:complexType>
- <xs:sequence>
- <xs:element name="id" type="xs:string"/>
- <xs:element name="dateOfBirth" type="xs:dateTime"/>
- <xs:element name="forename" type="xs:string"/>
- <xs:element name="surname" type="xs:string"/>
- </xs:sequence>
- </xs:complexType>
- </xs:element>
- </xs:schema>
使用XMLBeans,開發者生成了該模型,并在真實的場景中使用。現在我們回到開始的這個緩存的方案上來,假設它設計初衷是為了支持最多1.3M Person類的實例,而我們實際卻要塞進去同等數量的大家伙,這從根上就注定了失敗。
跑一組測試用例后,發現1.3M個基于XMLBean的生成的實例需要消耗大概1.5GB的堆空間。我們當時想這肯定可以做的更好。
第一個改進是顯而易見的,外部同系統內部集成的實現細節是不應該把影響傳遞給系統的每一個角落的。所以我們把緩存改成了使用簡單的 java.util.HashMap<Long, Person>。ID是鍵,Person是值。我們發現內存的消耗立即降低到了214MB。但這還不能令我們滿意。
由于Map中的鍵是一個數,我們有十足的理由使用Trove Collections來進一步降低它的內存消耗。這在實現上的改動很快,我們只需把 HashMap 改成 TLongObjectHashMap<Person> ,堆的消耗進一步降低到了143MB。
活干到這個程度我們已經可以收工了,但是工程師的好奇心驅使我們要更進一步。不由自主的我們發現了系統的數據存在著大量的重復信息。例如Date Of Birth其實已經在ID中編碼了,所以Date Of Birth可以直接從ID中得到,而不必使用額外的空間去它。
經過改良,Person類現在變成了這個樣子:
- // Imports and methods removed to improve readability
- public class Person {
- private String id;
- private String forename;
- private String surname;
- }
重新跑一邊測試證實我們的改進的確有效,堆消耗降低到了93MB。但是我們還未滿足。
該應用在64位的機器上使用老的JDK6。默認情況下,這么做不能壓縮普通對象的指針的。通過參數”-XX:UseCompressedOops“切換到壓縮模式使我們獲得了額外的收獲,現在我們的內存消耗降低到了73MB。
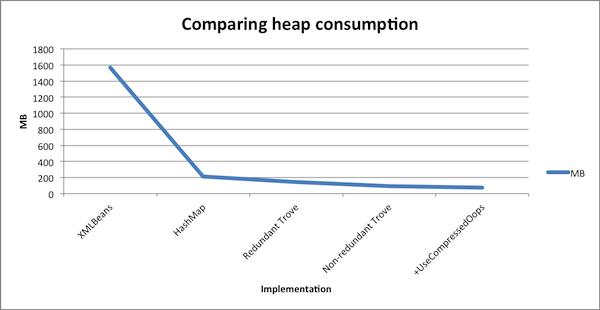
當然,我們還能走的更遠。比如基于鍵值建立B-tree,但這已經開始影響到了代碼的可讀性,所以我們決定到此為止。降低21.5倍的堆內存應該已經是一個足夠好的結果了。
讓我們在重復一下學到了什么
別把同外部模塊的整合影響到系統的每一個角落
冗余的數據可能帶來開銷。在可能的情況下盡量消除它
基本數據類型是你最經常打交道的朋友,務必知道些關于它們的工具,如果還沒玩過Trove請立刻開始吧
JVM自帶的優化技術不可忽視
如果你對這個實驗很好奇,請在此處下載相關的代碼。使用到的的測量工具和其具體描述可以在這篇博文找到。















