Java代碼優(yōu)化過程的實(shí)例介紹
衡量程序的標(biāo)準(zhǔn)
衡量一個(gè)程序是否優(yōu)質(zhì),可以從多個(gè)角度進(jìn)行分析。其中,最常見的衡量標(biāo)準(zhǔn)是程序的時(shí)間復(fù)雜度、空間復(fù)雜度,以及代碼的可讀性、可擴(kuò)展性。針對程序的時(shí)間復(fù)雜度和空間復(fù)雜度,想要優(yōu)化程序代碼,需要對數(shù)據(jù)結(jié)構(gòu)與算法有深入的理解,并且熟悉計(jì)算機(jī)系統(tǒng)的基本概念和原理;而針對代碼的可讀性和可擴(kuò)展性,想要優(yōu)化程序代碼,需要深入理解軟件架構(gòu)設(shè)計(jì),熟知并會(huì)應(yīng)用合適的設(shè)計(jì)模式。
首先,如今計(jì)算機(jī)系統(tǒng)的存儲(chǔ)空間已經(jīng)足夠大了,達(dá)到了 TB 級別,因此相比于空間復(fù)雜度,時(shí)間復(fù)雜度是程序員首要考慮的因素。為了追求高性能,在某些頻繁操作執(zhí)行時(shí),甚至可以考慮用空間換取時(shí)間。其次,由于受到處理器制造工藝的物理限制、成本限制,CPU 主頻的增長遇到了瓶頸,摩爾定律已漸漸失效,每隔 18 個(gè)月 CPU 主頻即翻倍的時(shí)代已經(jīng)過去了,程序員的編程方式發(fā)生了徹底的改變。在目前這個(gè)多核多處理器的時(shí)代,涌現(xiàn)了原生支持多線程的語言(如 Java)以及分布式并行計(jì)算框架(如 Hadoop)。為了使程序充分地利用多核 CPU,簡單地實(shí)現(xiàn)一個(gè)單線程的程序是遠(yuǎn)遠(yuǎn)不夠的,程序員需要能夠編寫出并發(fā)或者并行的多線程程序。***,大型軟件系統(tǒng)的代碼行數(shù)達(dá)到了***,如果沒有一個(gè)設(shè)計(jì)良好的軟件架構(gòu),想在已有代碼的基礎(chǔ)上進(jìn)行開發(fā),開發(fā)代價(jià)和維護(hù)成本是無法想象的。一個(gè)設(shè)計(jì)良好的軟件應(yīng)該具有可讀性和可擴(kuò)展性,遵循“開閉原則”、“依賴倒置原則”、“面向接口編程”等。
項(xiàng)目介紹
本文將介紹筆者經(jīng)歷的一個(gè)項(xiàng)目中的一部分,通過這個(gè)實(shí)例剖析代碼優(yōu)化的過程。下面簡要地介紹該系統(tǒng)的相關(guān)部分。
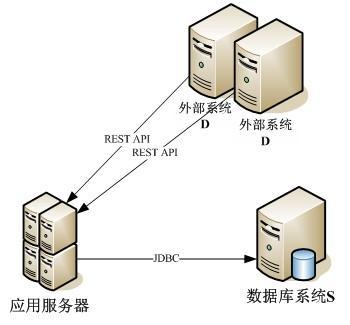
該系統(tǒng)的開發(fā)語言為 Java,部署在共擁有 4 核 CPU 的 Linux 服務(wù)器上,相關(guān)部分主要有以下操作:通過某外部系統(tǒng) D 提供的 REST API 獲取信息,從中提取出有效的信息,并通過 JDBC 存儲(chǔ)到某數(shù)據(jù)庫系統(tǒng) S 中,供系統(tǒng)其他部分使用,上述操作的執(zhí)行頻率為每天一次,一般在午夜當(dāng)系統(tǒng)空閑時(shí)定時(shí)執(zhí)行。為了實(shí)現(xiàn)高可用性(High Availability),外部系統(tǒng) D 部署在兩臺(tái)服務(wù)器上,因此需要分別從這兩臺(tái)服務(wù)器上獲取信息并將信息插入數(shù)據(jù)庫中,有效信息的條數(shù)達(dá)到了上千條,數(shù)據(jù)庫插入操作次數(shù)則為有效信息條數(shù)的兩倍。
圖 1. 系統(tǒng)體系結(jié)構(gòu)圖
為了快速地實(shí)現(xiàn)預(yù)期效果,在最初的實(shí)現(xiàn)中優(yōu)先考慮了功能的實(shí)現(xiàn),而未考慮系統(tǒng)性能和代碼可讀性等。系統(tǒng)大致有以下的實(shí)現(xiàn):(1)REST API 獲取信息、數(shù)據(jù)庫操作可能拋出的異常信息都被記錄到日志文件中,作為調(diào)試用;(2)共有 5 次數(shù)據(jù)庫連接操作,包括***次清空數(shù)據(jù)庫表,針對兩個(gè)外部系統(tǒng) D 各有兩次數(shù)據(jù)庫插入操作,這 5 個(gè)連接都是獨(dú)立的,用完之后即釋放;(3)所有的數(shù)據(jù)庫插入語句都是使用 java.sql.Statement 類生成的;(4)所有的數(shù)據(jù)庫插入語句,都是單條執(zhí)行的,即生成一條執(zhí)行一條;(5)整個(gè)過程都是在單個(gè)線程中執(zhí)行的,包括數(shù)據(jù)庫表清空操作,數(shù)據(jù)庫插入操作,釋放數(shù)據(jù)庫連接;(6)數(shù)據(jù)庫插入操作的 JDBC 代碼散布在代碼中。雖然這個(gè)版本的系統(tǒng)可以正常運(yùn)行,達(dá)到了預(yù)期的效果,但是效率很低,從通過 REST API 獲取信息,到解析并提取有效信息,再到數(shù)據(jù)庫插入操作,總共耗時(shí) 100 秒左右。而預(yù)期的時(shí)間應(yīng)該在一分鐘以內(nèi),這顯然是不符合要求的。
代碼優(yōu)化過程
筆者開始分析整個(gè)過程有哪些耗時(shí)操作,以及如何提升效率,縮短程序執(zhí)行的時(shí)間。通過 REST API 獲取信息,因?yàn)槭鞘褂猛獠肯到y(tǒng)提供的 API,所以無法在此處提升效率;取得信息之后解析出有效部分,因?yàn)槭菍μ囟ǜ袷降男畔⑦M(jìn)行解析,所以也無效率提升的空間。所以,效率可以大幅度提升的空間在數(shù)據(jù)庫操作部分以及程序控制部分。下面,分條敘述對耗時(shí)操作的改進(jìn)方法。
針對日志記錄的優(yōu)化
關(guān)閉日志記錄,或者更改日志輸出級別。因?yàn)閺膬膳_(tái)服務(wù)器的外部系統(tǒng) D 上獲取到的信息是相同的,所以數(shù)據(jù)庫插入操作會(huì)拋出異常,異常信息類似于“Attempt to insert duplicate record”,這樣的異常信息跟有效信息的條數(shù)相等,有上千條。這種情況是能預(yù)料到的,所以可以考慮關(guān)閉日志記錄,或者不關(guān)閉日志記錄而是更改日志輸出級別,只記錄嚴(yán)重級別(severe level)的錯(cuò)誤信息,并將此類操作的日志級別調(diào)整為警告級別(warning level),這樣就不會(huì)記錄以上異常信息了。本項(xiàng)目使用的是 Java 自帶的日志記錄類,以下配置文件將日志輸出級別設(shè)置為嚴(yán)重級別。
清單 1. log.properties 設(shè)置日志輸出級別的片段
|
通過上述的優(yōu)化之后,性能有了大幅度的提升,從原來的 100 秒左右降到了 50 秒左右。為什么僅僅不記錄日志就能有如此大幅度的性能提升呢?查閱資料,發(fā)現(xiàn)已經(jīng)有人做了相關(guān)的研究與實(shí)驗(yàn)。經(jīng)常聽到 Java 程序比 C/C++ 程序慢的言論,但是運(yùn)行速度慢的真正原因是什么,估計(jì)很多人并不清楚。對于 CPU 密集型的程序(即程序中包含大量計(jì)算),Java 程序可以達(dá)到 C/C++ 程序同等級別的速度,但是對于 I/O 密集型的程序(即程序中包含大量 I/O 操作),Java 程序的速度就遠(yuǎn)遠(yuǎn)慢于 C/C++ 程序了,很大程度上是因?yàn)? C/C++ 程序能直接訪問底層的存儲(chǔ)設(shè)備。因此,不記錄日志而得到大幅度性能提升的原因是,Java 程序的 I/O 操作較慢,是一個(gè)很耗時(shí)的操作。
針對數(shù)據(jù)庫連接的優(yōu)化
共享數(shù)據(jù)庫連接。共有 5 次數(shù)據(jù)庫連接操作,每次都需重新建立數(shù)據(jù)庫連接,數(shù)據(jù)庫插入操作完成之后又立即釋放了,數(shù)據(jù)庫連接沒有被復(fù)用。為了做到共享數(shù)據(jù)庫連接,可以通過單例模式(Singleton Pattern)獲得一個(gè)相同的數(shù)據(jù)庫連接,每次數(shù)據(jù)庫連接操作都共享這個(gè)數(shù)據(jù)庫連接。這里沒有使用數(shù)據(jù)庫連接池(Database Connection Pool)是因?yàn)樵诔绦蛑挥猩倭康臄?shù)據(jù)庫連接操作,只有在大量并發(fā)數(shù)據(jù)庫連接的時(shí)候才需要連接池。#p#
清單 2. 共享數(shù)據(jù)庫連接的代碼片段
|
通過上述的優(yōu)化之后,性能有了小幅度的提升,從 50 秒左右降到了 40 秒左右。共享數(shù)據(jù)庫連接而得到的性能提升的原因是,數(shù)據(jù)庫連接是一個(gè)耗時(shí)耗資源的操作,需要同遠(yuǎn)程計(jì)算機(jī)進(jìn)行網(wǎng)絡(luò)通信,建立 TCP 連接,還需要維護(hù)連接狀態(tài)表,建立數(shù)據(jù)緩沖區(qū)。如果共享數(shù)據(jù)庫連接,則只需要進(jìn)行一次數(shù)據(jù)庫連接操作,省去了多次重新建立數(shù)據(jù)庫連接的時(shí)間。
針對插入數(shù)據(jù)庫記錄的優(yōu)化 1
使用預(yù)編譯 SQL。具體做法是使用 java.sql.PreparedStatement 代替 java.sql.Statement 生成 SQL 語句。PreparedStatement 使得數(shù)據(jù)庫預(yù)先編譯好 SQL 語句,可以傳入?yún)?shù)。而 Statement 生成的 SQL 語句在每次提交時(shí),數(shù)據(jù)庫都需進(jìn)行編譯。在執(zhí)行大量類似的 SQL 語句時(shí),可以使用 PreparedStatement 提高執(zhí)行效率。使用 PreparedStatement 的另一個(gè)好處是不需要拼接 SQL 語句,代碼的可讀性更強(qiáng)。通過上述的優(yōu)化之后,性能有了小幅度的提升,從 40 秒左右降到了 30~35 秒左右。
清單 3. 使用 Statement 的代碼片段
|
清單 4. 使用 PreparedStatement 的代碼片段
|
針對插入數(shù)據(jù)庫記錄的優(yōu)化 2
使用 SQL 批處理。通過 java.sql.PreparedStatement 的 addBatch 方法將 SQL 語句加入到批處理,這樣在調(diào)用 execute 方法時(shí),就會(huì)一次性地執(zhí)行 SQL 批處理,而不是逐條執(zhí)行。通過上述的優(yōu)化之后,性能有了小幅度的提升,從 30~35 秒左右降到了 30 秒左右。
針對多線程的優(yōu)化
使用多線程實(shí)現(xiàn)并發(fā) / 并行。清空數(shù)據(jù)庫表的操作、把從 2 個(gè)外部系統(tǒng) D 取得的數(shù)據(jù)插入數(shù)據(jù)庫記錄的操作,是相互獨(dú)立的任務(wù),可以給每個(gè)任務(wù)分配一個(gè)線程執(zhí)行。清空數(shù)據(jù)庫表的操作應(yīng)該先于數(shù)據(jù)庫插入操作完成,可以通過 java.lang.Thread 類的 join 方法控制線程執(zhí)行的先后次序。在單核 CPU 時(shí)代,操作系統(tǒng)中某一時(shí)刻只有一個(gè)線程在運(yùn)行,通過進(jìn)程 / 線程調(diào)度,給每個(gè)線程分配一小段執(zhí)行的時(shí)間片,可以實(shí)現(xiàn)多個(gè)進(jìn)程 / 線程的并發(fā)(concurrent)執(zhí)行。而在目前的多核多處理器背景下,操作系統(tǒng)中同一時(shí)刻可以有多個(gè)線程并行(parallel)執(zhí)行,大大地提高了計(jì)算速度。
清單 5. 使用多線程的代碼片段
|
通過上述的優(yōu)化之后,性能有了大幅度的提升,從 30 秒左右降到了 15 秒以下,10~15 秒之間。使用多線程而得到的性能提升的原因是,系統(tǒng)部署所在的服務(wù)器是多核多處理器的,使用多線程,給每個(gè)任務(wù)分配一個(gè)線程執(zhí)行,可以充分地利用 CPU 計(jì)算資源。
筆者試著給每個(gè)任務(wù)分配兩個(gè)線程執(zhí)行,希望能使程序運(yùn)行得更快,但是事與愿違,此時(shí)程序運(yùn)行的時(shí)間反而比每個(gè)任務(wù)分配一個(gè)線程執(zhí)行的慢,大約 20 秒。筆者推測,這是因?yàn)榫€程較多(相對于 CPU 的內(nèi)核數(shù)),使得 CPU 忙于線程的上下文切換,過多的線程上下文切換使得程序的性能反而不如之前。因此,要根據(jù)實(shí)際的硬件環(huán)境,給任務(wù)分配適量的線程執(zhí)行。
針對設(shè)計(jì)模式的優(yōu)化
使用 DAO 模式抽象出數(shù)據(jù)訪問層。原來的代碼中混雜著 JDBC 操作數(shù)據(jù)庫的代碼,代碼結(jié)構(gòu)顯得十分凌亂。使用 DAO 模式(Data Access Object Pattern)可以抽象出數(shù)據(jù)訪問層,這樣使得程序可以獨(dú)立于不同的數(shù)據(jù)庫,即便訪問數(shù)據(jù)庫的代碼發(fā)生了改變,上層調(diào)用數(shù)據(jù)訪問的代碼無需改變。并且程序員可以擺脫單調(diào)繁瑣的數(shù)據(jù)庫代碼的編寫,專注于業(yè)務(wù)邏輯層面的代碼的開發(fā)。通過上述的優(yōu)化之后,性能并未有提升,但是代碼的可讀性、可擴(kuò)展性大大地提高了。
圖 2. DAO 模式的層次結(jié)構(gòu)

清單 6. 使用 DAO 模式的代碼片段
|
回顧以上代碼優(yōu)化過程:關(guān)閉日志記錄、共享數(shù)據(jù)庫連接、使用預(yù)編譯 SQL、使用 SQL 批處理、使用多線程實(shí)現(xiàn)并發(fā) / 并行、使用 DAO 模式抽象出數(shù)據(jù)訪問層,程序運(yùn)行時(shí)間從最初的 100 秒左右降低到 15 秒以下,在性能上得到了很大的提升,同時(shí)也具有了更好的可讀性和可擴(kuò)展性。
結(jié)束語
通過該項(xiàng)目實(shí)例,筆者深深地感到,想要寫出一個(gè)性能優(yōu)化、可讀性可擴(kuò)展性強(qiáng)的程序,需要對計(jì)算機(jī)系統(tǒng)的基本概念、原理,編程語言的特性,軟件系統(tǒng)架構(gòu)設(shè)計(jì)都有較深入的理解。“紙上得來終覺淺,絕知此事要躬行”,想要將這些基本理論、編程技巧融會(huì)貫通,還需要不斷地實(shí)踐,并總結(jié)心得體會(huì)。
原文鏈接:http://www.ibm.com/developerworks/cn/java/j-lo-codeoptimize/