













基于Hadoop云盤系統1:上傳和下載效率優化
作者:張子良
基于任何平臺實現的云盤系統,面臨的首要的技術問題就是客戶端上傳和下載效率優化問題。基于Hadoop實現的云盤系統,受到Hadoop文件讀寫機制的影響,采用Hadoop提供的API進行HDFS文件系統訪問,文件讀取時默認是順序、逐block讀取;寫入時是順序寫入。
一、讀寫機制
首先來看文件讀取機制:盡管DataNode實現了文件存儲空間的水平擴展和多副本機制,但是針對單個具體文件的讀取,Hadoop默認的API接口并沒有提供多DataNode的并行讀取機制。基于Hadoop提供的API接口實現的云盤客戶端也自然面臨同樣的問題。Hadoop的文件讀取流程如下圖所示:
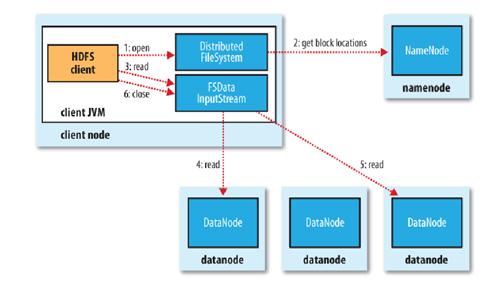
- 使用HDFS提供的客戶端開發庫,向遠程的Namenode發起RPC請求;
- Namenode會視情況返回文件的部分或者全部block列表,對于每個block,Namenode都會返回有該block拷貝的datanode地址;
- 客戶端開發庫會選取離客戶端最接近的datanode來讀取block;
- 讀取完當前block的數據后,關閉與當前的datanode連接,并為讀取下一個block尋找***的datanode;
- 當讀完列表的block后,且文件讀取還沒有結束,客戶端開發庫會繼續向Namenode獲取下一批的block列表。
- 讀取完一個block都會進行checksum驗證,如果讀取datanode時出現錯誤,客戶端會通知Namenode,然后再從下一個擁有該block拷貝的datanode繼續讀取。
這里需要注意的關鍵點是:多個Datanode順序讀取。
其次再看文件的寫入機制:
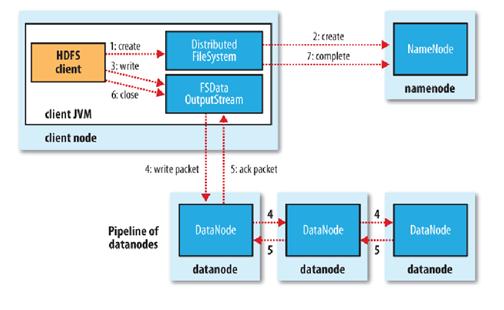
- 使用HDFS提供的客戶端開發庫,向遠程的Namenode發起RPC請求;
- Namenode會檢查要創建的文件是否已經存在,創建者是否有權限進行操作,成功則會為文件創建一個記錄,否則會讓客戶端拋出異常;
- 當客戶端開始寫入文件的時候,開發庫會將文件切分成多個packets,并在內部以"data queue"的形式管理這些packets,并向Namenode申請新的blocks,獲取用來存儲replicas的合適的datanodes列表, 列表的大小根據在Namenode中對replication的設置而定。
- 開始以pipeline(管道)的形式將packet寫入所有的replicas中。開發庫把packet以流的方式寫入***個 datanode,該datanode把該packet存儲之后,再將其傳遞給在此pipeline中的下一個datanode,直到***一個 datanode,這種寫數據的方式呈流水線的形式。
- ***一個datanode成功存儲之后會返回一個ack packet,在pipeline里傳遞至客戶端,在客戶端的開發庫內部維護著"ack queue",成功收到datanode返回的ack packet后會從"ack queue"移除相應的packet。
- 如果傳輸過程中,有某個datanode出現了故障,那么當前的pipeline會被關閉,出現故障的datanode會從當前的 pipeline中移除,剩余的block會繼續剩下的datanode中繼續以pipeline的形式傳輸,同時Namenode會分配一個新的 datanode,保持replicas設定的數量。
關鍵詞:開發庫把packet以流的方式寫入***個datanode,該datanode將其傳遞給pipeline中的下一個datanode,知道***一個Datanode,這種寫數據的方式呈流水線方式。
二、解決方案
1.下載效率優化
通過以上讀寫機制的分析,我們可以發現基于Hadoop實現的云盤客戶段下載效率的優化可以從兩個層級著手:
1.文件整體層面:采用并行訪問多線程(多進程)份多文件并行讀取。
2.Block塊讀取:改寫Hadoop接口擴展,多Block并行讀取。
2.上傳效率優化
上傳效率優化只能采用文件整體層面的并行處理,不支持分Block機制的多Block并行讀取。
原文鏈接:http://www.cnblogs.com/hadoopdev/archive/2013/03/07/2947447.html
【編輯推薦】
責任編輯:彭凡
來源:
博客園
















