













大數(shù)據(jù)量下的SQL Server數(shù)據(jù)庫(kù)自身優(yōu)化
1.1:增加次數(shù)據(jù)文件
從SQL SERVER 2005開(kāi)始,數(shù)據(jù)庫(kù)不默認(rèn)生成NDF數(shù)據(jù)文件,一般情況下有一個(gè)主數(shù)據(jù)文件(MDF)就夠了,但是有些大型的數(shù)據(jù)庫(kù),由于信息很多,而且查詢頻繁,所以為了提高查詢速度,可以把一些表或者一些表中的部分記錄分開(kāi)存儲(chǔ)在不同的數(shù)據(jù)文件里
由于CPU和內(nèi)存的速度遠(yuǎn)大于硬盤(pán)的讀寫(xiě)速度,所以可以把不同的數(shù)據(jù)文件放在不同的物理硬盤(pán)里,這樣執(zhí)行查詢的時(shí)候,就可以讓多個(gè)硬盤(pán)同時(shí)進(jìn)行查詢,以充分利用CPU和內(nèi)存的性能,提高查詢速度。 在這里詳細(xì)介紹一下其寫(xiě)入的原理,數(shù)據(jù)文件(MDF、NDF)和日志文件(LDF)的寫(xiě)入方式是不一樣的:
數(shù)據(jù)文件:SQL Server按照同一個(gè)文件組里面的所有文件現(xiàn)有空閑空間的大小,按這個(gè)比例把新的數(shù)據(jù)分布到所有有空間的數(shù)據(jù)文件里,如果有三個(gè)數(shù)據(jù)文件A.MDF,B.NDF,C.NDF,空閑大小分別為200mb,100mb,和50mb,那么寫(xiě)入一個(gè)70mb的東西,他就會(huì)向ABC三個(gè)文件中一次寫(xiě)入40、20、10的數(shù)據(jù),如果某個(gè)日志文件已滿,就不會(huì)向其寫(xiě)入
日志文件:日志文件是按照順序?qū)懭氲模粋€(gè)寫(xiě)滿,才會(huì)寫(xiě)入另外一個(gè)
由上可見(jiàn),如果能增加其數(shù)據(jù)文件NDF,有利于大數(shù)據(jù)量的查詢速度,但是增加日志文件卻沒(méi)什么用處。
1.2:設(shè)置文件自動(dòng)增長(zhǎng)(大數(shù)據(jù)量,小數(shù)據(jù)量無(wú)需設(shè)置)
在SQL Server 2005中,默認(rèn)MDF文件初始大小為5MB,自增為1MB,不限增長(zhǎng),LDF初始為1MB,增長(zhǎng)為10%,限制文件增長(zhǎng)到一定的數(shù)目,一般設(shè)計(jì)中,使用SQL自帶的設(shè)計(jì)即可,但是大型數(shù)據(jù)庫(kù)設(shè)計(jì)中,最好親自去設(shè)計(jì)其增長(zhǎng)和初始大小,如果初始值太小,那么很快數(shù)據(jù)庫(kù)就會(huì)寫(xiě)滿,如果寫(xiě)滿,在進(jìn)行插入會(huì)是什么情況呢?當(dāng)數(shù)據(jù)文件寫(xiě)滿,進(jìn)行某些操作時(shí),SQL Server會(huì)讓操作等待,直到文件自動(dòng)增長(zhǎng)結(jié)束了,原先的那個(gè)操作才能繼續(xù)進(jìn)行。如果自增長(zhǎng)用了很長(zhǎng)時(shí)間,原先的操作會(huì)等不及就超時(shí)取消了(一般默認(rèn)的閾值是15秒),不但這個(gè)操作會(huì)回滾,文件自動(dòng)增長(zhǎng)也會(huì)被取消。也就是說(shuō),這一次文件沒(méi)有得到任何增大,增長(zhǎng)的時(shí)間根據(jù)自動(dòng)增長(zhǎng)的大小確定的,如果太小,可能一次操作需要連續(xù)幾次增長(zhǎng)才能滿足,如果太大,就需要等待很長(zhǎng)時(shí)間,所以設(shè)置自動(dòng)增長(zhǎng)要注意一下幾點(diǎn):
1)要設(shè)置成按固定大小增長(zhǎng),而不能按比例。這樣就能避免一次增長(zhǎng)太多或者太少所帶來(lái)的不必要的麻煩。建議對(duì)比較小的數(shù)據(jù)庫(kù),設(shè)置一次增長(zhǎng)50 MB到100 MB。對(duì)大的數(shù)據(jù)庫(kù),設(shè)置一次增長(zhǎng)100 MB到200 MB。
2)要定期監(jiān)測(cè)各個(gè)數(shù)據(jù)文件的使用情況,盡量保證每個(gè)文件剩余的空間一樣大,或者是期望的比例。
3)設(shè)置文件最大值,以免SQL Server文件自增長(zhǎng)用盡磁盤(pán)空間,影響操作系統(tǒng)。
4)發(fā)生自增長(zhǎng)后,要及時(shí)檢查新的數(shù)據(jù)文件空間分配情況。避免SQL Server總是往個(gè)別文件寫(xiě)數(shù)據(jù)。
因此,對(duì)于一個(gè)比較繁忙的數(shù)據(jù)庫(kù),推薦的設(shè)置是開(kāi)啟數(shù)據(jù)庫(kù)自動(dòng)增長(zhǎng)選項(xiàng),以防數(shù)據(jù)庫(kù)空間用盡導(dǎo)致應(yīng)用程序失敗,但是要嚴(yán)格避免自動(dòng)增長(zhǎng)的發(fā)生。同時(shí),盡量不要使用自動(dòng)收縮功能。
1.3 數(shù)據(jù)和日志文件分開(kāi)存放在不同磁盤(pán)上
數(shù)據(jù)文件和日志文件的操作會(huì)產(chǎn)生大量的I/O。在可能的條件下,日志文件應(yīng)該存放在一個(gè)與數(shù)據(jù)和索引所在的數(shù)據(jù)文件不同的硬盤(pán)上以分散I/O,同時(shí)還有利于數(shù)據(jù)庫(kù)的災(zāi)難恢復(fù)。
優(yōu)化②:表分區(qū),索引分區(qū) (優(yōu)化①粗略的進(jìn)行了表分區(qū),優(yōu)化②為精確數(shù)據(jù)分區(qū))
為什么要表分區(qū)?
當(dāng)一個(gè)表的數(shù)據(jù)量太大的時(shí)候,我們最想做的一件事是什么?將這個(gè)表一分為二或者更多分,但是表還是這個(gè)表,只是將其內(nèi)容存儲(chǔ)分開(kāi),這樣讀取就快了N倍了
原理:表數(shù)據(jù)是無(wú)法放在文件中的,但是文件組可以放在文件中,表可以放在文件組中,這樣就間接實(shí)現(xiàn)了表數(shù)據(jù)存放在不同的文件中。能分區(qū)存儲(chǔ)的還有:表、索引和大型對(duì)象數(shù)據(jù) 。
SQL SERVER 2005中,引入了表分區(qū)的概念, 當(dāng)表中的數(shù)據(jù)量不斷增大,查詢數(shù)據(jù)的速度就會(huì)變慢,應(yīng)用程序的性能就會(huì)下降,這時(shí)就應(yīng)該考慮對(duì)表進(jìn)行分區(qū),當(dāng)一個(gè)表里的數(shù)據(jù)很多時(shí),可以將其分拆到多個(gè)的表里,因?yàn)橐獟呙璧臄?shù)據(jù)變得更少 ,查詢可以更快地運(yùn)行,這樣操作大大提高了性能,表進(jìn)行分區(qū)后,邏輯上表仍然是一張完整的表,只是將表中的數(shù)據(jù)在物理上存放到多個(gè)表空間(物理文件上),這樣查詢數(shù)據(jù)時(shí),不至于每次都掃描整張表
2.1什么時(shí)候使用分區(qū)表:
1、表的大小超過(guò)2GB。
2、表中包含歷史數(shù)據(jù),新的數(shù)據(jù)被增加到新的分區(qū)中。
2.2表分區(qū)的優(yōu)缺點(diǎn)
表分區(qū)有以下優(yōu)點(diǎn):
1、改善查詢性能:對(duì)分區(qū)對(duì)象的查詢可以僅搜索自己關(guān)心的分區(qū),提高檢索速度。
2、增強(qiáng)可用性:如果表的某個(gè)分區(qū)出現(xiàn)故障,表在其他分區(qū)的數(shù)據(jù)仍然可用;
3、維護(hù)方便:如果表的某個(gè)分區(qū)出現(xiàn)故障,需要修復(fù)數(shù)據(jù),只修復(fù)該分區(qū)即可;
4、均衡I/O:可以把不同的分區(qū)映射到磁盤(pán)以平衡I/O,改善整個(gè)系統(tǒng)性能。
缺點(diǎn):
分區(qū)表相關(guān):已經(jīng)存在的表沒(méi)有方法可以直接轉(zhuǎn)化為分區(qū)表。不過(guò) Oracle 提供了在線重定義表的功能。
2.3表分區(qū)的操作三步走
2.31 創(chuàng)建分區(qū)函數(shù)
CREATE PARTITION FUNCTION xx1(int)
AS RANGE LEFT FOR VALUES (10000, 20000);
注釋:創(chuàng)建分區(qū)函數(shù):myRangePF2,以INT類型分區(qū),分三個(gè)區(qū)間,10000以內(nèi)在A 區(qū),1W-2W在B區(qū),2W以上在C區(qū).
2.3.2創(chuàng)建分區(qū)架構(gòu)
CREATE PARTITION SCHEME myRangePS2
AS PARTITION xx1
TO (a, b, c);
注釋:在分區(qū)函數(shù)XX1上創(chuàng)建分區(qū)架構(gòu):myRangePS2,分別為A,B,C三個(gè)區(qū)間
A,B,C分別為三個(gè)文件組的名稱,而且必須三個(gè)NDF隸屬于這三個(gè)組,文件所屬文件組一旦創(chuàng)建就不能修改
2.3.3 對(duì)表進(jìn)行分區(qū)
常用數(shù)據(jù)規(guī)范--數(shù)據(jù)空間類型修改為:分區(qū)方案,然后選擇分區(qū)方案名稱和分區(qū)列列表,結(jié)果如圖所示:
也可以用sql語(yǔ)句生成
- CREATE TABLE [dbo].[AvCache](
- [AVNote] [varchar](300) NULL,
- [bb] [int] IDENTITY(1,1)
- ) ON [myRangePS2](bb);
--注意這里使用[myRangePS2]架構(gòu),根據(jù)bb分區(qū)
2.3.4查詢表分區(qū)
SELECT *, $PARTITION.[myRangePF2](bb) FROM dbo.AVCache
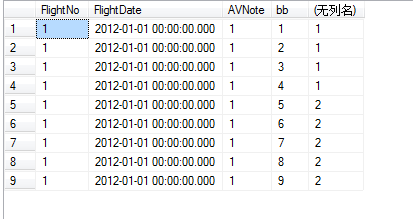
這樣就可以清楚的看到表數(shù)據(jù)是如何分區(qū)的了
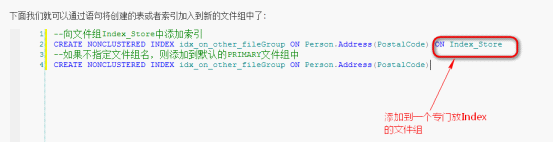
2.3.5創(chuàng)建索引分區(qū)
優(yōu)化③:分布式數(shù)據(jù)庫(kù)設(shè)計(jì)
分布式數(shù)據(jù)庫(kù)系統(tǒng)是在集中式數(shù)據(jù)庫(kù)系統(tǒng)的基礎(chǔ)上發(fā)展起來(lái)的,理解起來(lái)也很簡(jiǎn)單,就是將整體的數(shù)據(jù)庫(kù)分開(kāi),分布到各個(gè)地方,就其本質(zhì)而言,分布式數(shù)據(jù)庫(kù)系統(tǒng)分為兩種:1.數(shù)據(jù)在邏輯上是統(tǒng)一的,而在物理上卻是分散的,一個(gè)分布式數(shù)據(jù)庫(kù)在邏輯上是一個(gè)統(tǒng)一的整體,在物理上則是分別存儲(chǔ)在不同的物理節(jié)點(diǎn)上,我們通常說(shuō)的分布式數(shù)據(jù)庫(kù)都是這種2.邏輯是分布的,物理上也是分布的,這種也成聯(lián)邦式分布數(shù)據(jù)庫(kù),由于組成聯(lián)邦的各個(gè)子數(shù)據(jù)庫(kù)系統(tǒng)是相對(duì)“自治”的,這種系統(tǒng)可以容納多種不同用途的、差異較大的數(shù)據(jù)庫(kù),比較適宜于大范圍內(nèi)數(shù)據(jù)庫(kù)的集成。
分布式數(shù)據(jù)庫(kù)較為復(fù)雜,在此不作詳細(xì)的使用和說(shuō)明,只是舉例說(shuō)明一下,現(xiàn)在分布式數(shù)據(jù)庫(kù)多用于用戶分區(qū)性較強(qiáng)的系統(tǒng)中,如果一個(gè)全國(guó)連鎖店,一般設(shè)計(jì)為每個(gè)分店都有自己的銷售和庫(kù)存等信息,總部則需要有員工,供應(yīng)商,分店信息等數(shù)據(jù)庫(kù),這類型的分店數(shù)據(jù)庫(kù)可以完全一致,很多系統(tǒng)也可能導(dǎo)致不一致,這樣,各個(gè)連鎖店數(shù)據(jù)存儲(chǔ)在本地,從而提高了影響速度,降低了通信費(fèi)用,而且數(shù)據(jù)分布在不同場(chǎng)地,且存有多個(gè)副本,即使個(gè)別場(chǎng)地發(fā)生故障,不致引起整個(gè)系統(tǒng)的癱瘓。 但是他也帶來(lái)很多問(wèn)題,如:數(shù)據(jù)一致性問(wèn)題、數(shù)據(jù)遠(yuǎn)程傳遞的實(shí)現(xiàn)、通信開(kāi)銷的降低等,這使得分布式數(shù)據(jù)庫(kù)系統(tǒng)的開(kāi)發(fā)變得較為復(fù)雜,只是讓大家明白其原理,具體的使用方式就不做詳細(xì)的介紹了。
優(yōu)化④:整理數(shù)據(jù)庫(kù)碎片
如果你的表已經(jīng)創(chuàng)建好了索引,但性能卻仍然不好,那很可能是產(chǎn)生了索引碎片,你需要進(jìn)行索引碎片整理。
什么是索引碎片?
由于表上有過(guò)度地插入、修改和刪除操作,索引頁(yè)被分成多塊就形成了索引碎片,如果索引碎片嚴(yán)重,那掃描索引的時(shí)間就會(huì)變長(zhǎng),甚至導(dǎo)致索引不可用,因此數(shù)據(jù)檢索操作就慢下來(lái)了。
如何知道是否發(fā)生了索引碎片?
在SQLServer數(shù)據(jù)庫(kù),通過(guò)DBCC ShowContig或DBCC ShowContig(表名)檢查索引碎片情況,指導(dǎo)我們對(duì)其進(jìn)行定時(shí)重建整理。
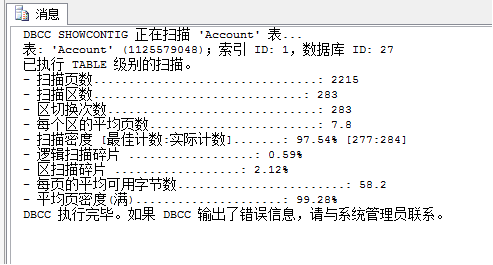
通過(guò)對(duì)掃描密度(過(guò)低),掃描碎片(過(guò)高)的結(jié)果分析,判定是否需要索引重建,主要看如下兩個(gè):
Scan Density [Best Count:Actual Count]-掃描密度[最佳值:實(shí)際值]:DBCC SHOWCONTIG返回最有用的一個(gè)百分比。這是擴(kuò)展盤(pán)區(qū)的最佳值和實(shí)際值的比率。該百分比應(yīng)該盡可能靠近100%。低了則說(shuō)明有外部碎片。
Logical Scan Fragmentation-邏輯掃描碎片:無(wú)序頁(yè)的百分比。該百分比應(yīng)該在0%到10%之間,高了則說(shuō)明有外部碎片。
解決方式:
一是利用DBCC INDEXDEFRAG整理索引碎片
二是利用DBCC DBREINDEX重建索引。
兩者區(qū)別調(diào)用微軟的原話如下:
DBCC INDEXDEFRAG 命令是聯(lián)機(jī)操作,所以索引只有在該命令正在運(yùn)行時(shí)才可用,而且可以在不丟失已完成工作的情況下中斷該操作。這種方法的缺點(diǎn)是在重新組織數(shù)據(jù)方面沒(méi)有聚集索引的除去/重新創(chuàng)建操作有效。
重新創(chuàng)建聚集索引將對(duì)數(shù)據(jù)進(jìn)行重新組織,其結(jié)果是使數(shù)據(jù)頁(yè)填滿。填滿程度可以使用 FILLFACTOR 選項(xiàng)進(jìn)行配置。這種方法的缺點(diǎn)是索引在除去/重新創(chuàng)建周期內(nèi)為脫機(jī)狀態(tài),并且操作屬原子級(jí)。如果中斷索引創(chuàng)建,則不會(huì)重新創(chuàng)建該索引。也就是說(shuō),要想獲得好的效果,還是得用重建索引,所以決定重建索引。
原文鏈接:http://www.cnblogs.com/AK2012/archive/2012/12/25/2012-1225.html
【編輯推薦】













