Hadoop架構(gòu)中的HDFS和NameNode
到目前為止,我們談到Hadoop是一個創(chuàng)建分布式集群的框架,能夠處理大的、不同的數(shù)據(jù)集。然而,另一個說法是將Hadoop理解為一個存儲設(shè)備或存儲環(huán)境。確實,它是一個能夠在其上創(chuàng)建應(yīng)用的平臺,有存儲PB級數(shù)據(jù)的能力。此外,它能夠處理并分析數(shù)據(jù);提供越來越多的“大數(shù)據(jù)”應(yīng)用結(jié)果。(不可否認(rèn),這正是一個以存儲為中心的Hadoop架構(gòu)觀點。)
我們也可以說每個節(jié)點提供其本地計算并把資源存儲到集群,這些節(jié)點基于常用的服務(wù)器硬件。有時候用“cheap and deep”這一術(shù)語來描述資源配置理念,意思是集群由常用服務(wù)器(廉價的)組成,能夠擴展到數(shù)百個節(jié)點(深入)――都是以免費的Apache Hadoop(可以免費獲得)為基礎(chǔ)。
Hadoop:與RAID類似嗎?
鑒于cheap and deep(廉價和深入)的傾向,隨著時間的推移出現(xiàn)預(yù)期的一類或另一類組件失敗。所以Hadoop的目的是檢測并解決故障。這方面Hadoop有點類似于初期以廉價磁盤冗余陣列為代表的RAID。假設(shè),由許多PC級磁盤構(gòu)成存儲陣列,驅(qū)動器將來很可能發(fā)生故障。訣竅是允許驅(qū)動器出現(xiàn)故障而不丟失數(shù)據(jù)。不同的RAID級別(0,1,3,5,6等等)提供多種陣列配置和驅(qū)動器故障恢復(fù)模式。
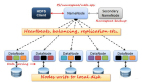
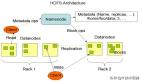
的確,Hadoop可以看作廉價服務(wù)器冗余陣列(RAIS). Hadoop也假設(shè)冗余服務(wù)器的硬件故障將是一個正常的操作事件,并因此內(nèi)置恢復(fù)進程。大多數(shù)部署在Hadoop分布式文件系統(tǒng)(HDFS)中.例如,當(dāng)提取數(shù)據(jù)時,它被分解成數(shù)據(jù)塊(默認(rèn)是64MB塊)。塊被多次拷貝然后分布――原始和副本――訪問DataNodes。HDFS默認(rèn)創(chuàng)建兩份副本,并且通常寫入到不同機架的服務(wù)器。這個拷貝和分布進程由NameNode管理。如果由于某種原因一個DataNode服務(wù)器出現(xiàn)故障,包括內(nèi)部磁盤故障,這個NameNode將在集群中其它地方找到丟失的數(shù)據(jù),當(dāng)故障節(jié)點被重啟或替換后進程能夠繼續(xù)執(zhí)行。
區(qū)別于現(xiàn)代RAID陣列
盡管如此,還有一些明顯的遺漏。從DataNode的故障中恢復(fù)比NameNode中斷恢復(fù)相對容易。在當(dāng)前的Apache Hadoop版本中,沒有適用于無功能的NameNode的自動恢復(fù)規(guī)定。Hadoop NameNode是一個臭名昭著的單點故障點(SPOF)——和RAID陣列沒有什么不同,單控制器的RAID陣列也是一個SPOF。NameNode損壞關(guān)閉集群可能導(dǎo)致數(shù)據(jù)丟失,如果故障發(fā)生,數(shù)據(jù)不能被恢復(fù)。此外,重啟大集群(假設(shè)數(shù)據(jù)可恢復(fù))中的NameNode可能花費數(shù)小時。
Apache Hadoop尋址問題
缺乏自動NameNode故障轉(zhuǎn)移模式和其它Apache Hadoop的缺點(JobTracker是另一個SPOF)給商業(yè)供應(yīng)商急于出售“企業(yè)就緒”方案提供了機會。這些供應(yīng)商的普遍做法之一是從本質(zhì)上支持Apache Hadoop,通過APIs訪問核心Hadoop組件,像HDFS一樣隨同他們自身修改,一些開放的和其它的專利。供應(yīng)商列表分成以下幾類(但不限于此):
• EMC
• HortonWorks
• IBM
• MapR (也是由EMC Greenplum提供)
• Red Hat
這些供應(yīng)商(其它供應(yīng)商希望在解決問題的同時,保留Hadoop的MapReduce框架)的業(yè)務(wù)首先是為了解決NameNode和JobTracker SPOF問題。例如,MapR是Apache Hadoop工具的分布,實現(xiàn)集群中跨服務(wù)器分布式NameNode功能(分布式NameNode負(fù)載均衡)。Red Hat的GlusterFS使用它內(nèi)置的元數(shù)據(jù)感知NameNode,完全消除了元數(shù)據(jù)服務(wù)器。
我們也提到,Hadoop創(chuàng)建多個跨集群分布的數(shù)據(jù)副本,適用于不同的恢復(fù)場景。然而,使用快照替代可能適用于回滾集群到一個已知的好的狀態(tài),同時降低全數(shù)據(jù)拷貝的開銷。一些供應(yīng)商在他們的Hadoop架構(gòu)中支持快照拷貝。
回顧我們關(guān)于向外擴展的網(wǎng)絡(luò)直連存儲(NAS)作為Hadoop主存儲的討論, EMC Isilon也可以用來解決這些問題。Isilon的OneFS全局命名空間文件系統(tǒng)能夠支持Greenplum Hadoop (HD)集群。Isilon把HDFS看作“過線”協(xié)議,因此是第一個集成到HDFS的SoNAS平臺。它也解決了Hadoop NameNode 和 JobTracker功能的單點故障。
Apache Hadoop的回應(yīng)
公平地說,我們不得不指出Apache社區(qū)清楚Hadoop當(dāng)前NameNode和其它問題的缺陷。事實上,現(xiàn)在從Cloudera (CDH 4.0)可以得到一個重要的作為測試版的新版本,專門針對NameNode SPOF問題。它包括一個HDFS的高可用(HA)版本.在HA版本中是一個“熱備”NameNode,在管理員控制下,當(dāng)活動節(jié)點出現(xiàn)故障或因管理員在日常維護和升級將NameNode離線時接管——通常這種情況很有可能。總之,HDFS HA包括兩個主/備配置的NameNodes。將來,支持自動NameNode故障切換。
結(jié)語
我們由關(guān)注大數(shù)據(jù)存儲開始本系列,另一種說法是PB級存儲,大數(shù)據(jù)分析是做商業(yè)智能(BI)的新途徑。但是,我們已經(jīng)看到大數(shù)據(jù)存儲如何與Hadoop結(jié)合使用——集成大數(shù)據(jù)存儲和分析——Hadoop可以被看作一個PB級存儲設(shè)備。
然而,我們還沒有真正探索一個最終的但重要的因素:成本。除了我們以前描述的給無共享集群增加網(wǎng)絡(luò)存儲的潛在問題,一個存儲區(qū)域網(wǎng)絡(luò)(SAN)和NAS也被“傳統(tǒng)主義者”視為太昂貴的方法。記住這個準(zhǔn)則:cheap and deep。與之相似,在集群結(jié)點級固態(tài)硬盤(SSD)作為直連存儲(DAS)的替代方案。甚至能夠用渦輪給集群增壓的存儲在規(guī)模和適用性上被視為太昂貴,只適用于那些愿意為性能付錢的用戶。
真正的問題是廉價和深的思想將來是否會在企業(yè)級數(shù)據(jù)中心盛行。如果確實如此,節(jié)點級DAS作為Hadoop唯一的存儲層將很可能盛行,直到有人意識到持續(xù)增加服務(wù)器到集群來適應(yīng)數(shù)據(jù)增長,同時會有越來越多的增長維護問題和管理開銷方面成本影響。如果不是這樣,為了業(yè)務(wù)連續(xù)和數(shù)據(jù)存儲目的SAN 和/或 NAS將作為一級或二級存儲層,并且存儲管理員的技能將被再次加分。