在Spark中,什么叫內存計算?
作者:ziwen
由于計算的融合只發生在 Stages 內部,而 Shuffle 是切割 Stages 的邊界,因此一旦發生 Shuffle,內存計算的代碼融合就會中斷。
本文轉載自微信公眾號「記錄技術記錄我」,作者ziwen。轉載本文請聯系記錄技術記錄我公眾號。
在 Spark 中,內存計算有兩層含義:
- 第一層含義就是眾所周知的分布式數據緩存;
- 第二層含義是 Stage 內的流水線式計算模式,通過計算的融合來大幅提升數據在內存中的轉換效率,進而從整體上提升應用的執行性能;
那 Stage 內的流水線式計算模式到底長啥樣呢?在 Spark 中,流水線計算模式指的是:在同一 Stage 內部,所有算子融合為一個函數,Stage 的輸出結果,由這個函數一次性作用在輸入數據集而產生。
我們用一張圖來直觀地解釋這一計算模式。
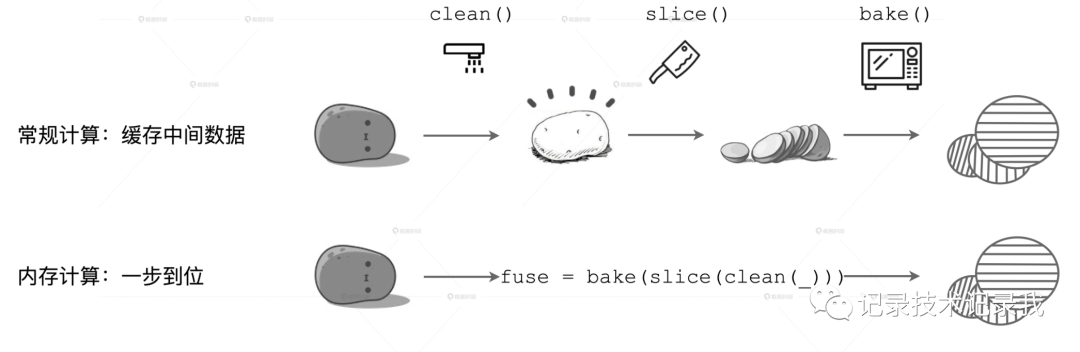
在上面的計算流程中,如果你把流水線看作是內存,每一步操作過后都會生成臨時數據,如圖中的 clean 和 slice,這些臨時數據都會緩存在內存里。
但在下面的內存計算中,所有操作步驟如 clean、slice、bake,都會被捏合在一起構成一個函數。這個函數一次性地作用在“帶泥土豆”上,直接生成“即食薯片”,在內存中不產生任何中間數據形態。
由于計算的融合只發生在 Stages 內部,而 Shuffle 是切割 Stages 的邊界,因此一旦發生 Shuffle,內存計算的代碼融合就會中斷。但是,當我們對內存計算有了多方位理解以后,就不會一股腦地只想到用 cache 去提升應用的執行性能,而是會更主動地想辦法盡量避免 Shuffle,讓應用代碼中盡可能多的部分融合為一個函數,從而提升計算效率。
責任編輯:武曉燕
來源:
記錄技術記錄我