Hadoop學習筆記之Hadoop的來龍去脈
談到Hadoop就不得不提到Lucene和Nutch。首先,Lucene并不是一個應用程序,而是提供了一個純Java的高性能全文索引引擎工具包,它可以方便的嵌入到各種實際應用中實現全文搜索/索引功能。Nutch是一個應用程序,是一個以Lucene為基礎實現的搜索引擎應用,Lucene 為Nutch提供了文本搜索和索引的API,Nutch不光有搜索的功能,還有數據抓取的功能。在nutch0.8.0版本之前,Hadoop還屬于 Nutch的一部分,而從nutch0.8.0開始,將其中實現的NDFS和MapReduce剝離出來成立一個新的開源項目,這就是Hadoop,而 nutch0.8.0版本較之以前的Nutch在架構上有了根本性的變化,那就是完全構建在Hadoop的基礎之上了。在Hadoop中實現了 Google的GFS和MapReduce算法,使Hadoop成為了一個分布式的計算平臺。
其實,Hadoop并不僅僅是一個用于存儲的分布式文件系統,而是設計用來在由通用計算設備組成的大型集群上執行分布式應用的框架。
Hadoop包含兩個部分:
1、HDFS
即Hadoop Distributed File System (Hadoop分布式文件系統)
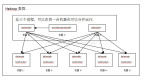
HDFS具有高容錯性,并且可以被部署在低價的硬件設備之上。HDFS很適合那些有大數據集的應用,并且提供了對數據讀寫的高吞吐率。 HDFS是一個master/slave的結構,就通常的部署來說,在master上只運行一個Namenode,而在每一個slave上運行一個 Datanode。
HDFS支持傳統的層次文件組織結構,同現有的一些文件系統在操作上很類似,比如你可以創建和刪除一個文件,把一個文件從一個目錄移到另一個目錄,重命名等等操作。Namenode管理著整個分布式文件系統,對文件系統的操作(如建立、刪除文件和文件夾)都是通過Namenode來控制。
2、MapReduce的實現
MapReduce是Google 的一項重要技術,它是一個編程模型,用以進行大數據量的計算。對于大數據量的計算,通常采用的處理手法就是并行計算。至少現階段而言,對許多開發人員來說,并行計算還是一個比較遙遠的東西。MapReduce就是一種簡化并行計算的編程模型,它讓那些沒有多少并行計算經驗的開發人員也可以開發并行應用。
MapReduce的名字源于這個模型中的兩項核心操作:Map和 Reduce。也許熟悉Functional Programming(函數式編程)的人見到這兩個詞會倍感親切。簡單的說來,Map是把一組數據一對一的映射為另外的一組數據,其映射的規則由一個函數來指定,比如對[1, 2, 3, 4]進行乘2的映射就變成了[2, 4, 6, 8]。Reduce是對一組數據進行歸約,這個歸約的規則由一個函數指定,比如對[1, 2, 3, 4]進行求和的歸約得到結果是10,而對它進行求積的歸約結果是24。
關于MapReduce的內容,建議看看這篇文章MapReduce:The Free Lunch Is Not Over!
持續學習中....Hurry
【編輯推薦】