













SQL Server數據庫中簡單的SELECT TOP
首先從博客園的Jerome Wong網友說起
他提出了一個這樣的問題
本人寫了好幾年SQL語句了,從來沒注意到這件事情。
例如:
數據表如下:
ID EMPNO NAME AGE
1 26929 Jerome 28
2 28394 Quince 27
3 20983 Green 30
4 27189 Mike 30
5 23167 Arishy 30
6 26371 Yager 29
我寫了SQL語句想取得第3、4筆數據,測試分頁玩的。
- select top 2 * from (select top 4 * from Member ) m
- order by m.RowID desc
我執行中間那一段子查詢:select top 4 * from Member
取得的是:
1 26929 Jerome 28
2 28394 Quince 27
3 20983 Green 30
4 27189 Mike 30
但是整個SQL語句的結果卻是:
5 23167 Arishy 30
6 26371 Yager 29
真的不知道到底怎么會出現這種情況,請高手指教。
其實不管你是新手還是高手在寫程序當中經常會碰到類似這樣的細節問題
下面我就對Jerome Wong網友所提出的問題針對select top做出一系列的分析(在這里要感謝Jerome Wong網友提出的這個問題)
準備工作
- if object_id('zhuisuo')is not null
- drop table zhuisuo
- go
- create table zhuisuo
- (
- id int null,name varchar(20) null
- )
- insert into zhuisuo values(1,'追索1')
- insert into zhuisuo values(2,'追索2')
- insert into zhuisuo values(3,'追索3')
- insert into zhuisuo values(4,'追索4')
- insert into zhuisuo values(5,'追索5')
- insert into zhuisuo values(6,'追索6')
- insert into zhuisuo values(7,'追索7')
- insert into zhuisuo values(8,'追索8')
- insert into zhuisuo values(9,'追索9')
- insert into zhuisuo values(10,'追索10')
- go
下面我們來簡單寫兩句Select語句
- select top 2 * from (select top 4 * from zhuisuo) m order by m.id desc
- select top 2 * from (select top 4 * from zhuisuo order by id asc) m order by m.id desc
執行結果大家會發現

平常很多人會認為這兩條語句執行的結果會一樣
怎么會這樣呢?
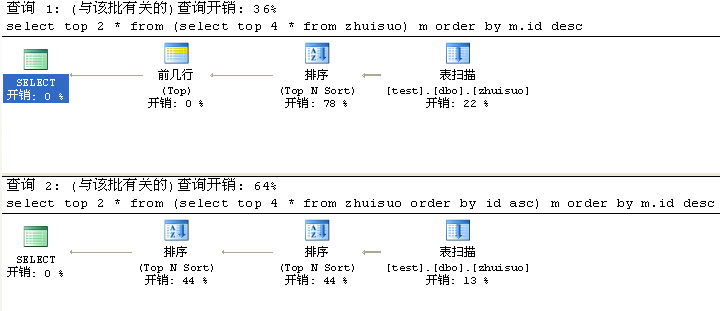
從這個查詢計劃中大家可以清楚的看到
***種掃描完zhuisuo表后先降序(top N Sort)然后在4行范圍中取前2行
第二種掃描完zhuisuo表后先升序取4行(top N Sort)然后再把這4行降序取2行(top N Sort)
在這里就不得不簡單的說說SQL語句中出現的表子查詢了
表子查詢,而出現在from子句中的表我們稱為派生表
派生表是虛擬的,未被物理具體化,也就是說當編譯的時候
如(select top 2 * from (select top 4 * from zhuisuo) m order by m.id desc )
外部查詢和內部查詢會被合并,并生成一個計劃
這時再看看上面的執行計劃就一目了然了
(注意事項:在派生表里面一般不允許使用order by除非指定了top
也就是說select top 2 * from (select * from zhuisuo order by id asc) m order by m.id desc這句語句是不能執行的)
派生表是個擬表要被外部引用,而order by返回的不是表而是游標.所以只用order by的話是被限制的
然而為什么使用top加order by又可以了
是因為top可以從order by返回的游標里選擇指定數量生成一個表并返回
接下來我再舉例關于top需要注意的細節
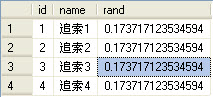
1、使用top返回隨機行,很多人會想到用RAND函數從而得到這樣一個語句
- select top 4 id,name from zhuisuo order by rand();
經過多次查詢后,你會失望的發現它沒有返回隨機行
這是因為每個查詢只調用它一次而不是每行調用它一次
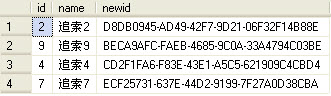
這時我們可以把RAND改為Newid
- select top 4 id,name from zhuisuo order by newid();
這時就會得到你想要的結果了,在這里我們可以意識到NEWID具有更好的分布特性
2、注意insert中使用top
- insert top (4) into zhuisuo
- select * from zhuisuo order by id desc
很多網友會解釋為把zhuisuo表中***4條插入表
但執行完畢后又會讓你失望了,插入的是最前面的4條
正確的倒敘插入top方法應該是
- insert into zhuisuo
- select top (4) * from zhuisuo order by id desc
這兩條語句又有什么區別
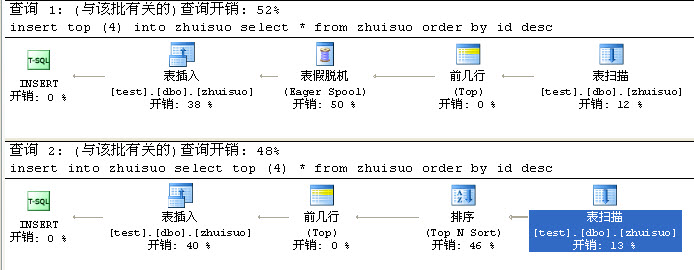
其實第上面那條語句更本就沒有排序(Top N Sort)
3、有時我想刪除數據表里面時間最近的5條數據怎么辦
delete 和update使用top的時候不能使用order by
現在我們可以這樣來解決
- delete zhuisuo
- where id in (select top(5) id from zhuisuo order by id desc)
- update zhuisuo
- set name='追索'+namewhere id in (select top(5) id from zhuisuo order by id desc)
這是變相實現Top N sort更新或刪除數據 但這不是***的方法因為這還要根具id去匹配
這時我們可以使用這種方法
- with cte_del as(select top(5) *
- from zhuisuo order by id desc)
- delete from cte_del
- with cte_del as
- (select top(5) * from zhuisuo order by id desc)
- update cte_del set name='追索'+name
4、top除了這些還有更多的用處,就比如之前我使用Top N sort 加 apply回答過一個網友的問題
如何查詢某用戶近一個月內正確率大于60%的閱讀記錄,每天只顯示符合條件正確率***的那個

在這里我只稍微提一下關于apply 也有很多有意思的細節 今后有時間我會用隨筆形式寫出來
***附上一張關于我用序號表示邏輯查詢處理的步驟

原文鏈接:http://www.cnblogs.com/zhuisuo/archive/2010/12/23/1914790.html
【編輯推薦】










