細數Google核心數據庫技術
分布式大規模數據處理
MapReduce
首先,在Google數據中心會有大規模數據需要處理,比如被網絡爬蟲(Web Crawler)抓取的大量網頁等。由于這些數據很多都是PB級別,導致處理工作不得不盡可能的并行化,而Google為了解決這個問題,引入了 MapReduce這個編程模型,MapReduce是源自函數式語言,主要通過"Map(映射)"和"Reduce(化簡)"這兩個步驟來并行處理大規模的數據集。Map會先對由很多獨立元素組成的邏輯列表中的每一個元素進行指定的操作,且原始列表不會被更改,會創建多個新的列表來保存Map的處理結果。也就意味著,Map操作是高度并行的。當Map工作完成之后,系統會先對新生成的多個列表進行清理(Shuffle)和排序,之后會這些新創建的列表進行Reduce操作,也就是對一個列表中的元素根據Key值進行適當的合并。
下圖為MapReduce的運行機制:
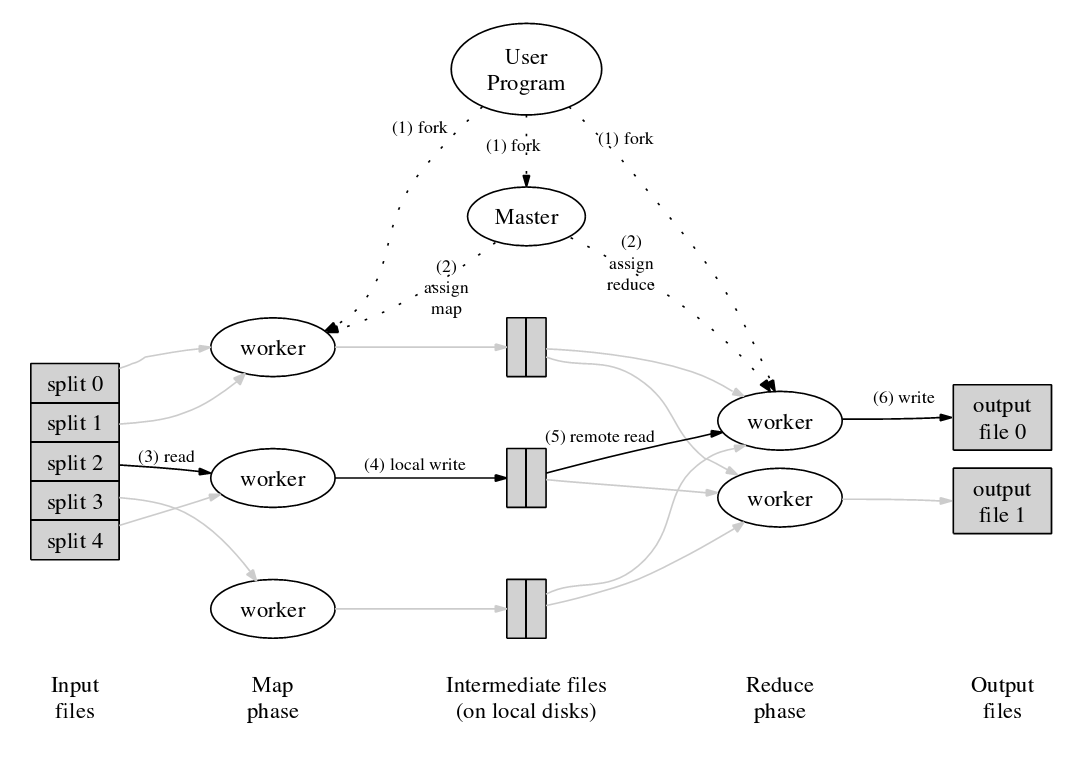
圖2. MapReduce的運行機制(參[19])點擊查看大圖
接下來,將根據上圖來舉一個MapReduce的例子:比如,通過搜索Spider將海量的Web頁面抓取到本地的GFS 集群中,然后Index系統將會對這個GFS集群中多個數據Chunk進行平行的Map處理,生成多個Key為URL,value為html頁面的鍵值對(Key-Value Map),接著系統會對這些剛生成的鍵值對進行Shuffle(清理),之后系統會通過Reduce操作來根據相同的key值(也就是URL)合并這些鍵值對。
***,通過MapReduce這么簡單的編程模型,不僅能用于處理大規模數據,而且能將很多繁瑣的細節隱藏起來,比如自動并行化,負載均衡和機器宕機處理等,這樣將極大地簡化程序員的開發工作。MapReduce可用于包括“分布grep,分布排序,web訪問日志分析,反向索引構建,文檔聚類,機器學習,基于統計的機器翻譯,生成Google的整個搜索的索引“等大規模數據處理工作。Yahoo也推出MapReduce的開源版本Hadoop,而且Hadoop在業界也已經被大規模使用。
Sawzall
Sawzall可以被認為是構建在MapReduce之上的采用類似Java語法的DSL(Domain-Specific Language),也可以認為它是分布式的AWK。它主要用于對大規模分布式數據進行篩選和聚合等高級數據處理操作,在實現方面,是通過解釋器將其轉化為相對應的MapReduce任務。除了Google的Sawzall之外,yahoo推出了相似的Pig語言,但其語法類似于SQL。
分布式數據庫技術
BigTable
由于在Google的數據中心存儲PB級以上的非關系型數據時候,比如網頁和地理數據等,為了更好地存儲和利用這些數據,Google開發了一套數據庫系統,名為“BigTable”。BigTable不是一個關系型的數據庫,它也不支持關聯(join)等高級SQL操作,取而代之的是多級映射的數據結構,并是一種面向大規模處理、容錯性強的自我管理系統,擁有TB級的內存和PB級的存儲能力,使用結構化的文件來存儲數據,并每秒可以處理數百萬的讀寫操作。
什么是多級映射的數據結構呢?就是一個稀疏的,多維的,排序的Map,每個Cell由行關鍵字,列關鍵字和時間戳三維定位.Cell的內容是一個不解釋的字符串,比如下表存儲每個網站的內容與被其他網站的反向連接的文本。 反向的URL com.cnn.www是這行的關鍵字;contents列存儲網頁內容,每個內容有一個時間戳,因為有兩個反向連接,所以archor的Column Family有兩列:anchor: cnnsi.com和anchhor:my.look.ca。Column Family這個概念,使得表可以輕松地橫向擴展。下面是它具體的數據模型圖:
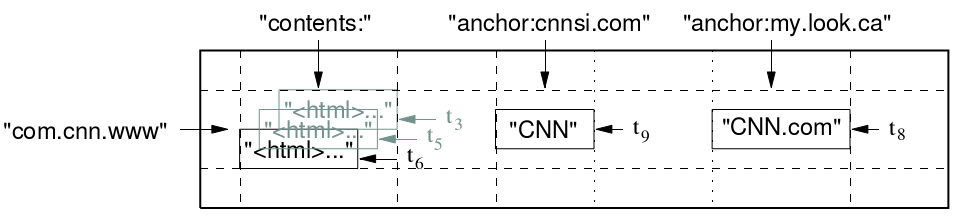
圖3. BigTable數據模型圖(參[4])
在結構上,首先,BigTable基于GFS分布式文件系統和Chubby分布式鎖服務。其次BigTable也分為兩部分:其一是Master節點,用來處理元數據相關的操作并支持負載均衡。其二是tablet節點,主要用于存儲數據庫的分片tablet,并提供相應的數據訪問,同時tablet 是基于名為SSTable的格式,對壓縮有很好的支持。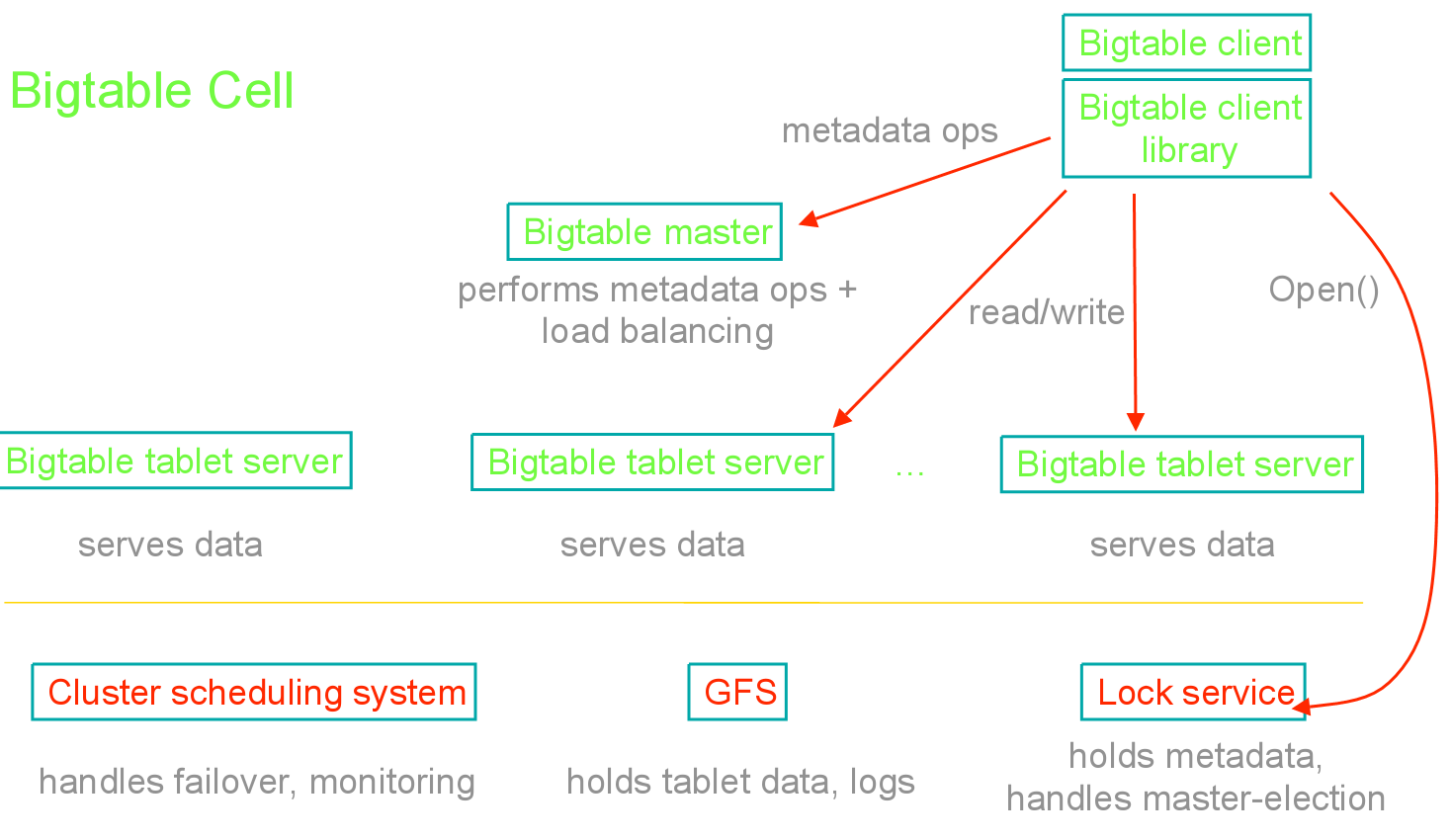
圖4. BigTable架構圖(參[15])
BigTable正在為Google六十多種產品和項目提供存儲和獲取結構化數據的支撐平臺,其中包括有Google Print, Orkut,Google Maps,Google Earth和Blogger等,而且Google至少運行著500個BigTable集群。
隨著Google內部服務對需求的不斷提高和技術的不斷地發展,導致原先的BigTable已經無法滿足用戶的需求,而 Google也正在開發下一代BigTable,名為“Spanner(扳手)”,它主要有下面這些BigTable所無法支持的特性:
1.支持多種數據結構,比如table,familie,group和coprocessor
2.基于分層目錄和行的細粒度的復制和權限管理。
3.支持跨數據中心的強一致性和弱一致性控
4.基于Paxos算法的強一致性副本同步,并支持分布式事
5.提供許多自動化操作。
6.強大的擴展能力,能支持百萬臺服務器級別的集群。
7.用戶可以自定義諸如延遲和復制次數等重要參數以適應不同的需求。
數據庫Sharding
Sharding就是分片的意思,雖然非關系型數據庫比如BigTable在Google的世界中占有非常重要的地位,但是面對傳統OLTP應用,比如廣告系統,Google還是采用傳統的關系型數據庫技術,也就是MySQL,同時由于Google所需要面對流量非常巨大,所以Google在數據庫層采用了分片(Sharding)的水平擴展(Scale Out)解決方案,分片是在傳統垂直擴展(Scale Up)的分區模式上的一種提升,主要通過時間,范圍和面向服務等方式來將一個大型的數據庫分成多片,并且這些數據片可以跨越多個數據庫和服務器來實現水平擴展。
Google整套數據庫分片技術主要有下面這些優點:
1.擴展性強:在Google生產環境中,已經有支持上千臺服務器的MySQL分片集群。
2.吞吐量驚人:通過巨大的MySQL分片集群能滿足巨量的查詢請求。
3.全球備份:不僅在一個數據中心還是在全球的范圍,Google都會對MySQL的分片數據進行備份,這樣不僅能保護數據,而且方便擴展。
在實現方面,主要可分為兩塊:其一是在MySQL InnoDB基礎上添加了數據庫分片的技術。其二是在ORM層的Hibernate的基礎上也添加了相關的分片技術,并支持虛擬分片(Virtual Shard)來便于開發和管理。同時Google也已經將這兩方面的代碼提交給相關組織。
數據中心優化技術
數據中心高溫化
大中型數據中心的PUE(Power Usage Effectiveness)普遍在2左右,也就是在服務器等計算設備上耗1度電,在空調等輔助設備上也要消耗一度電。對一些非常出色的數據中心,最多也就能達到1.7,但是Google通過一些有效的設計使部分數據中心到達了業界領先的1.2,在這些設計當中,其中最有特色的莫過于數據中心高溫化,也就是讓數據中心內的計算設備運行在偏高的溫度下,Google的能源方面的總監Erik Teetzel在談到這點的時候說:“普通的數據中心在70華氏度(21攝氏度)下面工作,而我們則推薦80華氏度(27攝氏度)“。但是在提高數據中心的溫度方面會有兩個常見的限制條件:其一是服務器設備的崩潰點,其二是精確的溫度控制。如果做好這兩點,數據中心就能夠在高溫下工作,因為假設數據中心的管理員能對數據中心的溫度進行正負1/2度的調節,這將使服務器設備能在崩潰點5度之內工作,而不是常見的20度之內,這樣既經濟,又安全。還有,業界傳言Intel為Google提供抗高溫設計的定制芯片,但云計算界的***專家James Hamilton認為不太可能,因為雖然處理器也非常懼怕熱量,但是與內存和硬盤相比還是強很多,所以處理器在抗高溫設計中并不是一個核心因素。同時他也非常支持使數據中心高溫化這個想法,而且期望將來數據中心甚至能運行在40攝氏度下,這樣不僅能節省空調方面的成本,而且對環境也很有利。
12V電池
由于傳統的UPS在資源方面比較浪費,所以Google在這方面另辟蹊徑,采用了給每臺服務器配一個專用的12V電池的做法來替換了常用的UPS,如果主電源系統出現故障,將由該電池負責對服務器供電。雖然大型UPS可以達到92%到95%的效率,但是比起內置電池的 99.99%而言是非常捉襟見肘的,而且由于能量守恒的原因,導致那么未被UPS充分利用的電力會被轉化成熱能,這將導致用于空調的能耗相應地攀升,從而走入一個惡性循環。同時在電源方面也有類似的“神來之筆”,普通的服務器電源會同時提供5V和12V的直流電。但是Google設計的服務器電源只輸出 12V直流電,必要的轉換在主板上進行,雖然這種設計會使主板的成本增加1美元到2美元,但是它不僅能使電源能在接近其峰值容量的情況下運行,而且在銅線上傳輸電流時效率更高。
原文標題:Google核心技術
鏈接:http://www.cnblogs.com/topcoderliu/archive/2010/08/13/1798619.html
【編輯推薦】