SNS網站數據庫技術分析
社交網
現在,傳統的互聯網正在邁向一個一個全新的時代 ---- 社交服務網時代( Social Networking Service ),從“人與機器”的時代邁向“人與人”的時代。互聯網社交服務網站的發展驗證了“六度分隔理論”( Six Degrees of Separation ),即“人際關系脈絡方面你必然可以通過不超出六位中間人間接與世上任意先生女士相識”。個體的社交圈會不斷地擴大和重疊并在最終形成大的社交網絡。無論是國外的 Facebook 、 MySpace 、 Twitter ,還是國內的開心網、人人網等一頭扎進社交網,他們認定社交網必然掀起新一輪的互聯網革命。
社交網其中一個的顯著特點是支持巨大用戶數,例如 Facebook 支持超過 3 億的用戶, Facebook 數據中心運行著超過萬臺的服務器,為這些遍布全球的用戶提供信息通訊服務。另外,任何兩個社交網用戶都可能交互,也就是必須支持任何兩個數據庫用戶的數據關聯操作。這種情況下,對于服務端的數據庫管理提出了極大的挑戰。
關系數據庫與 NoSQL 數據庫
關系數據庫使用者遵循一些數據庫范式,這些范式是數據庫設計中的一系列原理和技術,其目的是為了減少數據庫中數據冗余,并增進數據的一致性。結構化查詢語言 SQL ,大量使用多表連接操作, SQL 的通用性為數據庫使用者帶來很多方便。
隨著越來越多如 Web 服務之類承受大規模工作負荷的應用的發行,其對可伸縮性的需求,首先有可能會改變得非常迅速,其次會變得無比龐大。
關系數據庫的確能伸縮自如,但通常只能單臺服務器節點上進行。 例如采用表分區技術,一個表格可以由多個物理文件組成,雖然表格的容量增大了,但該表格仍然只能由一數據庫引擎管理。
一旦單節點的能力抵達上限,你就得通過多服務器節點來往外擴展來分發負載。這時候關系數據庫的復雜性就開始影響其潛在的擴展規模了。 RDBMS 支持分區視圖 (Partition View) 技術,也就是支持聯邦數據庫 (Federated Databases) 概念【圖 1 】。一個分區視圖可以由多個分布在不同的數據庫節點服務器上的表格組合而成,數據庫用戶只看到是該視圖,不關心多個物理表格。通過數據水平分割技術,分區視圖把負載分擔到多個數據庫節點服務器上。擴容時,該方法除了需改動視圖定義外,分區視圖成為分布式數據庫系統的中心,存在單點故障問題。另外,跨數據庫節點之間多表格間連接操作的支持出現極大困難。
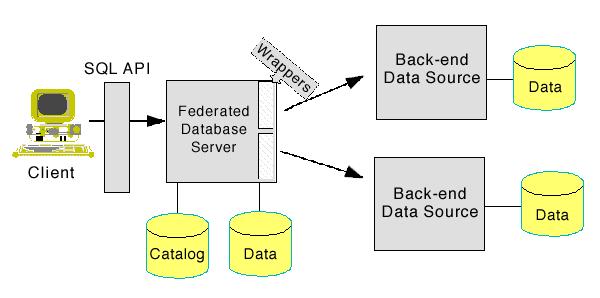
圖 1. IBM 聯邦數據庫的體系結構
當試圖擴展數據庫系統到成百上千個節點,而不是幾個,將導致不堪復雜性之重負,這一特點使得 RDBMS 在大型分布式系統平臺市場里的生存能力被大幅削減。
為了能向客戶提供的一個伸縮自如的空間去存放應用數據,供應商實際上只有一種真正的選擇。他們不得不實現一種新型的關注于可擴性的數據庫系統,而犧牲掉關系數據庫所帶來的其他好處。 NoSQL 是非關系型數據存儲的廣義定義。它打破了長久以來關系型數據庫與 ACID 理論大一統的局面。 NoSQL 數據存儲不需要固定的表結構,通常也不存在連接操作。在超大型數據存取上具備關系型數據庫無法比擬的性能優勢。該術語在 2009 年初得到了廣泛認同。其中 key-value 數據模型是解決大型數據庫系統擴充問題的一種可行的解決方案。
Berkeley DB Key-Value數據模型
Berkeley DB 是一種支持 key-value 數據模型的嵌入式數據庫存儲引擎。不支持 Client/Server 網絡訪問方式,程序通過進程內的 API 訪問數據庫。不支持 SQL 或者其他的數據庫查詢語言,不支持表結構和數據列。訪問數據庫的程序自主決定數據如何儲存在記錄里,一條記錄由一個稱為鍵 key 的數據塊和一個稱為值 value 的數據塊組成。 Berkeley DB 不對記錄里的數據進行任何包裝。應用程序可通過一回調函數來定義不同鍵之間的大小關系。記錄和它的鍵都可以達到 4G 字節的長度。盡管架構很簡單, Berkeley DB 卻支持很多高級的數據庫特性,比如 ACID 數據庫事務處理, 細粒度鎖, XA 接口,熱備份以及同步復制。 Berkley DB 為不同用戶提供多種功能集( Feature Set ) : 支持單個寫線程的數據存儲( Data Store );支持多并發寫線程的并發數據存儲( Concurrent Data Store ) ; 支持 ACID 和災難恢復的事務數據存儲( Transactional Data Store );和通過復制支持容錯的高可靠數據存儲( High Availability )。
實際上,一個關系數據庫系統由兩個獨立的部分組成,一是存儲引擎,二是關系引擎。存儲引擎負責記錄存儲,索引和事務處理。關系引擎基于存儲引擎提供的服務,根據表格、視圖的數據結構 (Schema) 和已建立的索引等信息, 負責分析 SQL 查詢,制定查詢執行計劃。 Berkeley DB 是一種存儲引擎。例如 MySQL 數據庫可采用 MyISAM 、 InnoDB 、 Berkeley DB 等存儲引擎【圖 2 】。
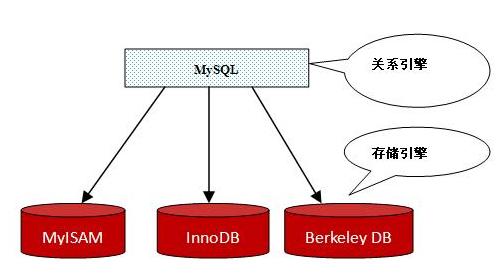
圖 2 : MySQL 使用的多種存儲引擎
Berkeley DB 支持平衡樹( BTree )、哈希( Hash )、隊列( Queue )和記錄( Record )等數據集存儲、索引方式。 Berkeley DB 支持根據 key-value 中的 key 創建集群索引( Clustered Index )。這樣記錄集的物理次序就根據 key 的大小來排列。如果要查詢結果記錄集的鍵值為給定的一個范圍,該特性對于支持這種類型的快速查詢起了很大作用。 Berkeley DB 的一個 key-value 記錄集稱為一個數據庫,一個數據庫存儲在一單獨文件中。 Berkeley DB 通過創建輔助數據庫( Secondary Database )允許對記錄集建立非集群索引( Non-Clustered Index )。非集群索引適用于結果為一條記錄的查詢,該記錄的鍵值為給定的一個值。例如社交網用戶數據集:
User
如果以 UID 作為主數據庫的鍵,其他字段作為主數據庫的值。可再創建一輔助數據庫,以 E-mail 作為輔助數據庫的鍵,輔助數據庫的值為 E-mail 所對應的 UID ,也就是指向主數據庫記錄的指針。
若在一個 key-value 數據庫查詢,一般可根據查詢條件創建成一鍵值,引擎返回一游標( Cursor ),該游標指向等于或大于該鍵值的結果數據集。
不難看出 Berkeley DB 使用的索引技術與 SQL Server, Oracle 等高端數據庫系統是一樣的。
其中在 RDBMS 中經常使用的表格連接操作,在 Berkeley DB 中不再支持,需要應用程序去實現兩個數據集的連接操作。這是 key-value 數據模型與關系數據模型典型的區別。
基于 key-value 數據模型,可把一個 value 數據塊擴充成多個列,來支持列數據模型。
Berkeley DB 除了作為 MySQL 的存儲引擎之外,還應用在 OpenLDAP 、 MemCache 等知名軟件。
與 Berkeley DB 類似的數據庫引擎還有 Tokyo Cabinet/ Tyrant 等。
社交網數據庫系統 Cassandra DB
以 Facebook 用戶數據集為例子,不大可能把 3 億條這巨大的數據集存放在同一表格中、同一個文件或由同一臺計算機處理,這要求系統能支持數據分區,把數據集分割在多臺節點計算機中,每臺計算機分擔一部分負載,當用戶增加到一定程度時,系統能允許加入新的節點計算機,并且盡可能地減少數據遷移。
2007 年 10 月 30 日, Amazon 的 CTO Werner Vogels 發表了一文章,討論了一種基于 key-value 數據模型存儲系統 Dynamo 。 Dynamo 系統支撐了不少 Amazon 自有的面向電子商務等關鍵性應用。 Dynamo 上采用的存儲引擎是 Berkeley DB 事務數據存儲( Transactional Data Store )。 Dynamo 系統主要為存儲 1M 左右甚至更小的內容,如購物車、推薦列表等。 Dynamo 設計上有如下一些特點:
通過數據分區復制來支持高可靠性與高可伸縮性
始終可寫
一致性與寫入速度的折衷,不要求同步寫入所有副本
對稱,完全去中心化,人工管理工作很小。
Cassandra DB 最初由 Facebook 開發,后轉變成了開源項目。它是一個為網絡社交云計算設計的數據庫。 Cassandra 的主要特點就是它不是一個數據庫,而是由一堆數據庫節點共同構成的一個分布 式網絡服務,對 Cassandra 的一個寫操作,會被復制到其他節點上去,對 Cassandra 的讀操作,也會被路由到某個節點上面去讀取。對于一個 Cassandra 群集來說,擴展性能 是比較簡單的事情,只管在群集里面添加節點就可以了。
Cassandra 的用戶包括 Facebook 、 Twitter 和 Digg 等。 Digg 工程副總裁 約翰 • 奎因 (John Quinn)說 :“ Cassandra 采用了完全分散的模式,每個節點都一樣,不會出現單一點的故障。其容錯率也非常高,數據可以被復制到數據中心的多個節點中。 Cassandra 還非常具有彈性,隨著新設備的加入,其讀寫吞吐量將呈線性增加。”
Cassandra 以 Amazon 專有的完全分布式的 Dynamo 為基礎,結合了 Google BigTable 基于列族( Column Family )的數據模型。 P2P 去中心化的存儲。很多方面都可以稱之為 Dynamo 2.0 。
圖 3 為 Cassandra 、 Dynamo 、 key-value 之間的關系及在社交網上的應用。箭頭表示依賴關系。
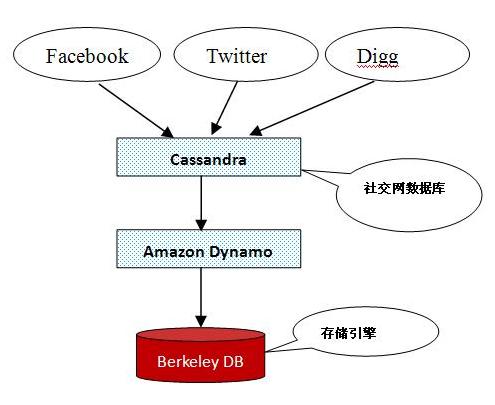
圖 3 : Cassandra, Dynamo, key-value 關系圖
分布式存儲系統 Amazon Dynamo 原理
Dynamo 采用 Consistent Hashing 算法來實現數據分區。
Consistent Hashing 基本原理是:首先求出服務器(節點)的哈希值,并將其配置到 0 ~ 2^32 的圓上。然后用同樣的方法求出存儲數據的鍵的哈希值,并映射到圓上。然后從數據映射到的位置開始順時針查找,將數據保存到找到的第一個服務器上。如果超過 2^32 仍然找不到服務器,就會保存到第一臺服務器上。【圖 4 】
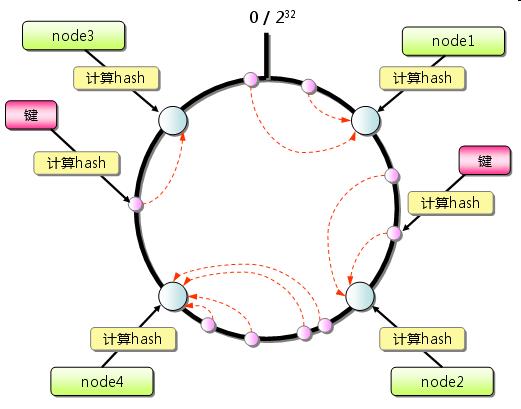
圖 4 :數據分割到 4 個節點數據庫
如果添加一臺服務器。只有在圈上,增加服務器的地點逆時針方向的第一臺服務器上的部分數據需要遷移到新的節點數據庫【圖 4 】。
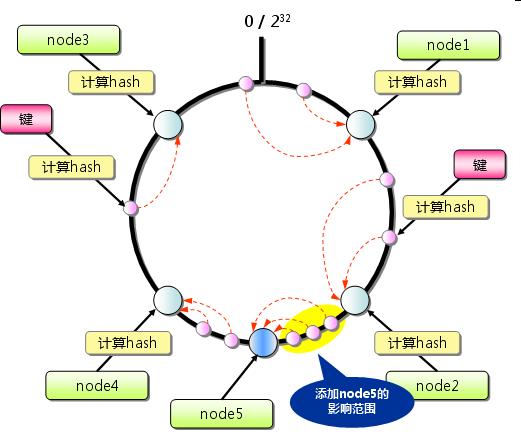
圖 5 :添加 Node5 后需要遷移的數據
數據分區后,數據塊被復制到 N 個節點上。復制時因為更新產生的一致性問題的維護采取類似拜占庭容錯 Quorum 協議( Byzantine Fault-tolerance Quorum )的機制以及去中心化的復制同步協議。當一個存儲節點被認為是拜占庭節點時 , 它的行為可能任意偏移 , 表現在 : 拒絕響應請求、發送錯誤消息、存儲錯誤信息等。 Quorum 協議中除了 N 之外還有兩個關鍵參數: R 與 W 。 R 代表一次成功的讀取操作中最小參與節點數量, W 代表一次成功的寫操作中最小參與節點數量。 R 和 W 直接影響性能、一致性。 R 和 W 值過小則影響一致性,過大則影響效率,這兩個值要平衡。如果 W 設置 為 1 ,則一個實例中只要有一個節點可寫就寫成功,不會影響寫效率;如果 R 設置為 1 ,只要有一個節點可讀,就讀成功,不會影響讀效率。 (N,R,W) 的典型配置是 (3,2,2) ,同時考慮了一致性和效率。
Facebook 數據庫查詢語言 : FQL
Facebook 為開發者提供一套和 SQL 風格一致的數據庫查詢語言,稱為 Facebook Query Language (FQL) 。 FQL 是一種基于列的數據查詢語言。提供豐富的條件查詢,甚至包括子查詢。
例如,以下 FQL 查詢已安裝 Facebook 應用程序的用戶 $app_user 的好友 ID 集合:
SELECT uid FROM user WHERE is_app_user = 1 AND uid IN (SELECT uid2 FROM friend WHERE uid1 = $app_user)
與 SQL 重要區別是 FQL 不支持
· 多表連接: JOIN 操作
· 結果集記錄個數限制: LIMIT
· 分組統計: GROUP BY 操作
· 排序: ORDER BY 操作
隨著技術發展,一部分基于列結構的 NoSQL 數據庫開始支持分組、排序等復雜數據統計分析功能。
例子:查詢好友信息
例如一個 Facebook 應用程序從以下兩個數據集中查找一用戶的好友數據集信息 :
User
Friend_List
注 Friend_UID 是一指向 User ( UID )的外鍵。
RDBMS 應用程序可使用數據集連接操作實現:
- SELECT f.UID, u.Friend_UID, u.First_Name, u.Last_Name, u.Icon
- FROM Friend_List f, User u
- WHERE f.Friend_UID = u.UID AND f.UID=@Input_UID
在社交網數據庫系統中,由于 User 數據分布在多臺服務器中,其連接操作和外鍵約束實際上不能支持。
在 Facebook 中查找一用戶的好友信息,得分 A)B) 兩步操作實現:
A)
- SELECT Friend_UID
- INTO @Out_Record_Set
- FROM Friend_List f
- WHERE f.UID=@Input_UID
B)
- FOR EACH (Friend_UID in @Out_Record_Set)
- SELECT u.Friend_UID, u.First_Name, u.Last_Name, u.Icon
- FROM User u
- WHERE u.UID = Friend_UID
No-SQL: Not Only SQL
對于那些關系復雜的數據處理和分析統計, SQL 值得花錢。但是當數據庫結構非常簡單時, SQL 可能沒有太大用處。如果能用普通文件存儲代替數據庫系統部分功能的話,應該優選普通文件存儲。
考慮社交網,能夠不受限制的擴展比更豐富的功能更加重要。建立大規模社交網成本的壓力讓很多社交網開發人員努力去尋找更高性價比的解決方案。研究表明基于普通廉價硬件的分布式存儲解決方案甚至比現在的高端數據庫更加可靠。當支持 SQL 的 RDBMS 不能解決所有問題的時候, NoSQL 不是簡單的 No SQL ,其本質是 No Relational ,這時候 NoSQL 就成為 Not Only SQL 。
【編輯推薦】