













圖解Python語(yǔ)言說(shuō)明介紹
Python語(yǔ)言這同時(shí)說(shuō)明IDLE的Shell支持兩種格式的中文字符串:GBK編碼的“str”對(duì)象,和UNICODE編碼的unicode對(duì)象,我連接的時(shí)候也用的是UTF-8,為什么查詢得到的文本內(nèi)容卻是UNICODE編碼(unicode對(duì)象)?這是MySQLdb庫(kù)的設(shè)置么?
在window下面用記事本編輯文件的時(shí)候,如果保存為UNICODE或UTF-8,分別會(huì)在文件的開(kāi)頭加上兩個(gè)字節(jié)“\xFF\xFE”和三個(gè)字節(jié)“\xEF\xBB\xBF”。在讀取的時(shí)候就可能會(huì)遇到問(wèn)題,但是不同的環(huán)境對(duì)這幾個(gè)多于字符的處理也不一樣。
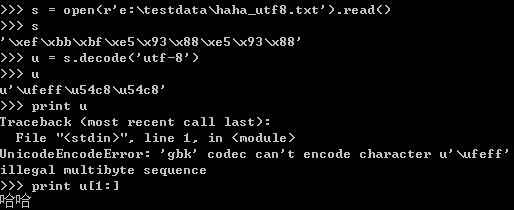
打開(kāi)utf-8格式的文件并讀取utf-8字符串后,解碼變成unicode對(duì)象。但是會(huì)把附加的三個(gè)字符同樣進(jìn)行轉(zhuǎn)換,變成一個(gè)unicode字符,字符的數(shù)據(jù)值為“\xFF\xFE”。這個(gè)字符不能被打印。編碼的時(shí)候需要跳過(guò)這個(gè)字符。
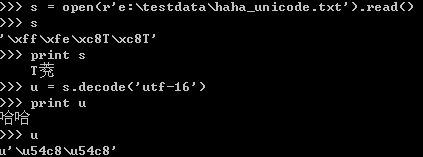
打開(kāi)unicode格式的文件后,得到的字符串正確。這時(shí)候適用utf-16解碼,能得到正確的unicdoe對(duì)象,可以直接使用。多余的那個(gè)填充字符在進(jìn)行轉(zhuǎn)換時(shí)會(huì)被過(guò)濾掉。

開(kāi)ansi格式的文件后,沒(méi)有填充字符,可以直接使用,結(jié)論:讀寫(xiě)使用python生成的文件沒(méi)有任何問(wèn)題,但是在處理由notepad生成的文本文件時(shí),如果該文件可能是非ansi編碼,需要考慮如何處理填充字符。
剛剛接觸Python語(yǔ)言,我用的數(shù)據(jù)庫(kù)是mysql。在執(zhí)行插入、查找等操作時(shí),如果運(yùn)行環(huán)境使用的字符編碼和mysql不一致,就可能導(dǎo)致運(yùn)行時(shí)的錯(cuò)誤。當(dāng)然,和上面看到的情況一樣。
運(yùn)行環(huán)境并不是關(guān)鍵因素,關(guān)鍵是查詢語(yǔ)句的編碼方式。如果在每次執(zhí)行查詢操作時(shí)都把查詢字符串做一次編碼轉(zhuǎn)換,轉(zhuǎn)變成mysql的默認(rèn)字符編碼,一樣不會(huì)遇到問(wèn)題。但是這樣寫(xiě)代碼也太痛苦了吧。
相面是兩種方法的用法比較:

另外,在Python語(yǔ)言的shell中,不要用 u’中文’ 對(duì)屬性進(jìn)行賦值。上面討論過(guò),這樣得到的unicode字符串不正確。
【編輯推薦】










