













SQL Server與Oracle數據庫事務處理橫向對比
在這里我們將對MS SQL Server和Oracle數據庫事務處理的一些不同進行對比,希望通過對比能幫助大家更好的理解事務處理的本來面貌。
背景
在吉日嘎拉的軟件編程走火入魔之:數據庫事務處理入門(適合初學者閱讀)文章中關于MS SQL Server和Oracle數據庫事務處理的差異性引起一些爭論,因此記錄我對數據庫事務處理的想法。
簡介
本文講述MS SQL Server和Oracle數據庫事務處理的差異性,以及Oracle如何對事務處理的實現。
什么是事務
數據庫事務(Database Transaction)是一組數據庫操作的處理單元。事務符合ACID的特性:
Atomic:原子性,要么全部要么一無所有。All or None.
Consistent:一致性,所有依賴關系以及約束一致。
Isolated:分離性,不同事務不互相影響。
Durable:持久性,提交事務的數據需要持久化。
為什么要使用事務
實現事務主要有兩大功能:
1.保證數據庫的consistent(一致性狀態),保持所有依賴關系以及約束一致)。哪怕數據庫管理系統出現故障時(例如斷電),也能恢復到一致性狀態。例如一個銀行轉帳系統,張三給李四轉3000圓RMB,張三帳號上減3000和李四帳號上加3000需要同時完成,否則系統的帳就不平了。也例如有些銷售系統的匯總表和明細表,是一個主表和一個從表,需要同步更新。
2.并發時分離不同事務操作。例如編輯過程中的數據不給其他事務查詢到。這也是相對的,在特效需求下可能要支持dirty read(臟讀),但不是這里討論的范圍了。
SQL Server 2008 的事務類型
1.自動提交事務 Autocommit Transactions
這是SQL Server默認的事務類型,每一條單獨的SQL語句(SQL statement)都是單獨的一個事務,語句執行完畢后自動提交。調用方不需要手工控制事務流程。
2.顯示事務 Explicit Transactions
調用方需要調用API或者使用T-SQL的BEGIN TRANSACTION 語句來打開事務。需要調用COMMIT 或者 ROLLBACK TRANSACTION 來提交或者回滾。
3.隱式事務 Implicit Transactions
使用SET IMPLICIT_TRANSACTIONS ON把事務模式變成隱式模式。調用方不需要執行BEGIN TRANSACTION 語句來打開事務。數據庫引擎執行到SQL語句的時候自動打開事務。調用方需要調用COMMIT 或者 ROLLBACK TRANSACTION 來提交或者回滾。當數據庫引擎執行下一個SQL語句時又自動打開一個新事務。
參考:Controlling Transactions (Database Engine)
Oracle的事務類型
Oracle的事務處理類型有點像SQL Server的隱式事務。當執行到第一個可執行的SQL語句時自動打開事務,然后需要調用方執行commit或者rollback來提交或者回滾事務,如果有DDL語句,Oracle也會自動提交事務的。
參考:Transaction Management
Oracle的事務的實現
Oracle的結構分邏輯上和物理上的區別。邏輯上的結構是表空間,而物理上的結構是數據文件。
邏輯實現
Oracle下實現事務在邏輯上是由Undo Tablespace來實現的。Undo Tablespace包含Undo Segements(段),而Undo Segements包含Undo Data。Undo Data是支持事務的邏輯單元。
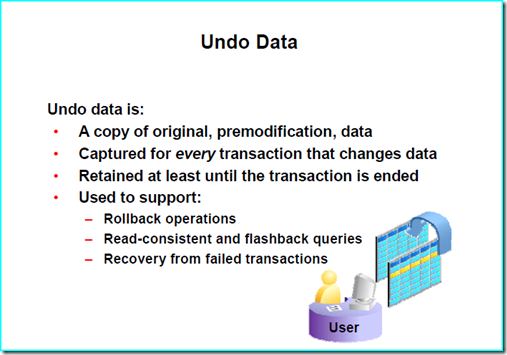
圖源自于《Oracle Database 10g: Administration Workshop I》
Undo Data用于保存修改前后的數據,以支持回滾,長時間查詢,和flashback查詢,以及失敗事務恢復的功能。
由于有了Undo Data,回滾事務變得容易了,因為Undo Data保存了修改前后的數據,保證了事務的原子性。失敗事務恢復和事務回滾類似,當網絡中斷或者其他原因導致事務異常停止,數據庫引擎可以恢復到一致性狀態。
同時Undo Data也支持長時間查詢(Read-consistent),例如有表格T,主鍵為key,有字段為f1,數據如下,盡管只有4條數據,假設需要很長時間進行查詢。
key f1
1 A
2 B
3 C
4 D
事務一開始查詢,一直沒結束,而事務二開始修改key為1的數據為Z,事務二進行提交,數據變成下面的表格。但是事務一查詢結束的時候還是讀出A,B,C,D,因為查詢是從Undo中讀出快照。
key f1
1 Z
2 B
3 C
4 D
Flashback查詢是Oracle 10g引進的功能,可以查詢出提交之后修改之前的數據,例如上面例子事務三在事務二提交后想查詢出A,B,C,D可以通過Flashback查詢來完成。這也是有Undo Data來支持的。
物理實現
從上面的邏輯實現看,只是知道了事務以及Undo Data的作用,還不清楚Oracle對事務的支持到底怎么實現的。下面從物理結構上講述Oracle怎么對事務進行支持。請先看一個物理結構圖。
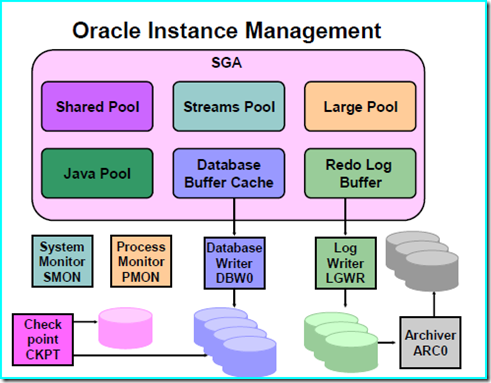
圖源自于《Oracle Database 10g: Administration Workshop I》
為了簡化,我只是用個人的語言講述和事務有關的部件。SGA可以理解為全局內存。其中Database Buffer Cache存放的是從數據文件中讀取的數據緩存。紫色的圓柱體為數據文件。Redo Log Buffer為重做日志緩存,也就是保存日志的內存塊,一切的數據的修改都會記錄在Redo Log Buffer里面。例如用回事務二更新key為1數據的例子。當事務二更新key為1數據從A到Z。Oracle數據庫引擎會把key為1的數據的rowid,修改前數據A以及修改后數據Z都記錄在Redo Log Buffer里面。如果事務二繼續更新key為2的數據為Y,那么key為2的數據的rowid,修改前數據B以及修改后數據Y也記錄到Redo Log Buffer里面。每一筆數據都記錄,而且是流水線性記錄。一旦事務二進行提交,LGWR進程(Log Writer,日志寫進程)就會把Redo Log Buffer的數據按順序寫到Log Datafile里面,也就是日志數據文件里面,當寫日志文件完成,Oracle數據庫引擎會生成一個SCN(system change number,系統更新號),到這時候Oracle數據庫引擎會通知調用方提交完成了。這里可以看到Oracle在提交的時候不必要把更新數據寫回數據文件,而是寫到日志文件里面。因為順序寫線性的日志文件速度快很多,而寫數據文件是需要隨機讀寫。由于線性記錄和SCN號控制,數據庫引擎可以通過redo log(重做日志文件)的操作得到最新的數據。當然在Checkpoint的時候數據文件是最終還是會更新的,只是說事務提交的時候更新數據文件不是必須步驟,這樣能很大的提高性能。
由于這個機制,回滾變得很簡單,要讀沒提交前之前的SCN是很容易的事情。
對于初學者關于數據庫事務處理的建議
我自己也是從新手一步步走過來,現在也不是老鳥,算是有點經驗,如果是剛入門的同學,你覺得有用就看一下,沒用就過了。
對于數據庫事務的處理,開始的時候不需要很深入了解數據庫的原理,當然以后還是需要了解的,優先級排后而已。高優先級如下:
首先,事務不是什么高深神秘的東西,我從入行開始所做的所有系統,包括現在的嵌入式系統,都用到事務。我并不覺得大部分系統事務有什么問題,只是一些約束和同步機制,真的有問題從自身系統設計角度看,不一定說從數據庫技術角度去找解決方法。例如Oracle的長時間查詢如果Undo Data(歷史數據)給覆蓋了,Oracle會拋出異常"ORA-01555: snapshot too old”,如果出現這種問題,我會從自身系統設計角度入手,為什么有那么大的查詢,為什么在這個查詢中其他事務會更新數據,這些查詢是否只是查一次就夠了,查的過程是否需要鎖住表等等。然而這個問題可以通過數據庫調優解決,但是我想問題的角度首先是從自身系統設計出發。
第二,要知道的是不同數據庫的事務類型的區別,例如MS SQL Sever是默認是自動提交事務,用的時候需要知道每個語句都有單獨的事務在操作。而Oracle是類似于隱式事務,必須手工commit或者rollback。
第三,使用事務要知道一一對應,特別是嵌套事務的時候,有始有終。很多問題時候發生終的時候,注意異常處理需要結束已經打開的事務。
第一點是心理問題,第二三點是技術問題,做好我覺得就可以入門開發系統了。以后碰到問題在一步步深入。
原文標題:MS SQL Server和Oracle對數據庫事務處理的差異性
鏈接:http://www.cnblogs.com/procoder/archive/2009/10/06/1578346.html
【編輯推薦】












