數據云URL過濾技術
面臨以上種種問題,該如何解決?全部關閉網絡的大門不符合現代人類文明的發展與進步,也不利于合理商業業務的開展。單純依靠使用者自我約束的網絡使用制度也已經無法執行。于是,誕生了專門針對URL進行過濾的技術,以此達到對員工上網瀏覽內容的控制與管理。
下面我們將對URL過濾技術的進化做一個簡單的介紹。
20世紀90年代中期,URL過濾解決方案依靠企業內部IT人員人工建立、更新與編輯站點黑白名單。這一做法的缺點是,所有分類由一個或少數幾個人自由決定,對于這種資源密集型而且缺乏客觀性的站點分類方法,不僅會使許多被認可的網站被封鎖或被禁止的網站允許通過,而且隨著web站點的快速增長與相關技術的日益復雜,這種方案很難實現客觀、細粒度的URL分類,顯然不能成為企業或單位有效的URL過濾方案。
20世紀90年代末,出現了專門對URL進行收集、分類的廠商。URL過濾技術開始采用本地數據庫分類引擎。URL及其內容在根據預先定義的類別下通過分類引擎進行相應的關鍵字查找分析與分類(如賭博、色情及網上購物等),分類好的URL存儲在一個集中的主數據庫中,然后通過更新復制一份副本移交到客戶本地數據庫中。這種URL過濾方案的缺點是,隨著網頁數量的激增,由于一刀切的關鍵字分類技術和本地分類數據庫的限制,無法實現更高、更準確的覆蓋率和更廣泛的URL分類。
2000年初,URL過濾解決方案試圖采用啟發式內容分析的方法,這種動態的分類技術,通過智能分析網站標題和網頁html主體中相關內容的概率來確定URL類別。從理論上講,相比前兩類URL分類方案,這是一種很好的分類方法,然而在實際中它本身卻存在問題,很多基于啟發式的Web內容分析結果沒有相關的配套技術實時地發送給終端用戶,而且采用的仍然是傳統的本地數據庫進行存儲。但是當今web2.0時代,web數據是一個不定數據且日益多樣化的集合體,而每個用戶的需求卻獨特且具體,基于本地URL數據庫的過濾技術,只能過濾存儲本地用戶需要的數據,不能存儲所有相關及最新數據,以執行快速和準確的監測,因此這種傳統的URL過濾技術也無法應對高度復雜且快速發展壯大的web2.0網絡。
據Google調查,互聯網上的網頁數量以每天一億的數量急速增長。以上三種URL 分類方法已經不能夠準確有效的收集、分類所有的URL類別。數據存儲和處理要求也已經遠遠超出了本地數據庫能力。于是在2009年,業界出現了數據云的URL過濾技術,這類廠商有Commtouch、Anchiva等。這種數據云URL過濾機制,基于云技術的URL收集、分類處理及發放策略,并不依賴于本地數據庫有限的資源進行分析與檢測,也不依賴于數據庫更新最新的URL分類,利用的是專門的分類服務器群,根據實際網絡的使用與普及方式對網頁內容及語義進行全面分析后的分類。與傳統的云不同的是,真正做到了云的客戶端自動主動地去云的服務器端獲取所需的數據,而不是單純的基于云服務端的定時推送更新方法。下面我們將借助Anchiva的數據云URL過濾機制對數據云URL過濾技術進行簡單的介紹。
Anchiva(安啟華)數據云的URL分析過濾技術由兩部分組成:部署在企業網絡邊界處的Anchiva web安全網關(SWG)和Anchiva基于云的URL分類中心。網關設備和URL分類中心實時通信獲取最新的URL分類。不僅打破了傳統本地數據庫的限制,而且與其他基于云的技術不同的是Anchiva web安全網關中具有URL緩存技術,這個本地的緩存為每一個獨立的用戶存儲最為相關的URL,這些設備本地的URL類別,有效地確保了URL匹配的最佳性能,并且采用的是一種本地緩存自動學習的機制,隨著企業用戶使用時間的增長,這個本地緩存的URL庫會更加的貼近每一個用戶的實際需求,將能給客戶更加精準的URL過濾。
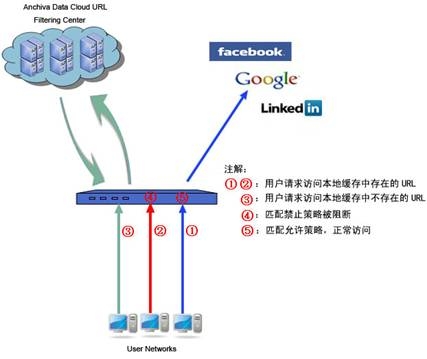
以下是Anchiva web安全網關URL過濾對HTTP-GET 請求的處理過程:
1、Anchiva web安全網關的URL匹配處理引擎接受來自本地用戶的HTTP-GET請求。
2、URL匹配處理引擎首先從設備上的本地緩存中查找相關的URL分類。
3、如果URL匹配處理引擎從本地緩存中查找到了正確的URL分類,那么將該HTTP-GET請求根據客戶設定好的相關過濾策略進行允許或阻止的操作。
4、如果沒有在本地緩存中找到正確的URL分類,URL匹配處理引擎會自動將該HTTP-GET請求發送到Anchiva數據云URL分類中心。
5、Anchiva數據云URL分類中心將自動查詢并返回正確的分類給設備的URL匹配處理引擎。
6、URL匹配處理引擎根據URL分類中心返回的分類對該HTTP-GET請求按照客戶設定好的相關過濾策略進行允許或阻止的操作,并在設備本地緩存的URL類別中添加相應的URL分類。
Anchiva數據云URL過濾處理過程圖:
另外,需要大家認清的一點是,任何的URL分類技術在web2.0時代都不可能做到100%的分類,如果用戶發出未經分類的瀏覽請求,則會自動反饋到云端的分類引擎進行分類,在24小時內將對未經分類URL完成分類。如此一來,數據云系統用戶形成一個實質用戶社區,已被社區用戶瀏覽過的流行站點將被分類并存儲,方便下一位用戶訪問。這種用戶互動保證了數據云系統保持不斷的更新與擴展,無疑是當今web2.0時代最有效實用且積極主動的一種收集分類處理技術。
說了這么多,下面我們對幾種URL過濾技術做以下對比總結:
|
|
90年代中期
自分類黑/白名單 |
90年代末
本地黑/白名單 |
2000年初
啟發式檢測分類 |
2009年基于云的URL過濾技術 |
|
分類技術 |
企業IT人員人工分類 |
關鍵字查詢分類引擎 |
啟發式的關鍵字概率分類技術 |
完整的web內容及語義分析技術 |
|
存儲方法 |
黑白名單文檔 |
本地數據庫 |
本地數據庫/云端服務器群 |
云端服務器群/本地緩存 |
|
更新方法 |
人工編輯更新黑白名單 |
復制數據庫副本更新方法 |
服務器定時推送更新 |
客戶端隨時獲取URL分類更新 |
|
準確性 |
差 |
一般 |
較好 |
極好 |
|
覆蓋范圍 |
差 |
一般 |
較好 |
極好 |
|
總結 |
缺乏客觀性的分類方法,資源集中,不準確。 |
誤報、漏報率高,互聯網的增長速度遠遠超過了本地數據庫存儲能力。 |
服務器不能實時推送準確的分類,沒有客戶端隨時獲取技術,客戶端使用本地數據庫存儲,容量有限。 |
無處理性能和本地數據庫存儲限制,先進的本地緩存自動學習機制,能夠滿足每個客戶獨特且具體的需求。 |