













SQL Server 2005中數(shù)據(jù)挖掘算法擴(kuò)展方法
SSAS為我們提供了九種數(shù)據(jù)挖掘算法,但是在應(yīng)用中我們需要根據(jù)實(shí)際問(wèn)題設(shè)計(jì)適當(dāng)?shù)乃惴ǎ@個(gè)時(shí)候就需要擴(kuò)展SSAS,使它能應(yīng)用更多的算 法,SSAS有比較好的可擴(kuò)展性,它提供了一個(gè)完整的機(jī)制來(lái)進(jìn)行擴(kuò)展,只要繼承一些類(lèi)并按適當(dāng)?shù)姆椒ㄟM(jìn)行注冊(cè)就可以在SSAS中使用自己的算法了。
下面我將通過(guò)實(shí)例分別用幾篇文章來(lái)介紹一下如何開(kāi)發(fā)SSAS算法插件。本文介紹的算法插件開(kāi)發(fā)方法是基于托管代碼的,是用C#開(kāi)發(fā)的(算法插件也可以用C++開(kāi)發(fā),并且SQLSERVER2005的案例中附帶C++版本的代碼stub)。整個(gè)過(guò)程大至為六個(gè)步驟。在開(kāi)始開(kāi)發(fā)之前需要做一些準(zhǔn)備工作,就是要去下載 一個(gè)用C++編寫(xiě)的COM組件,叫DMPluginWrapper(可以通過(guò)下載本文附帶的附件獲得),它作為SSAS與算法插件的中間層,用于處理 SSAS與算法插件之間的交互以及封裝從SSAS到算法插件的參數(shù)和從算法插件到SSAS的處理結(jié)果。DMPluginWrapper、SSAS和算法插 件之間的關(guān)系可以由下圖來(lái)描述。
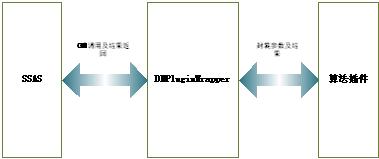
圖表 1: DMPluginWrapper、SSAS和算法插件之間的關(guān)系
下面開(kāi)始創(chuàng)建算法擴(kuò)展的項(xiàng)目。
首先新建一個(gè)類(lèi)庫(kù)項(xiàng)目(名為AlgorithmPlugin)將剛才的DMPluginWrapper項(xiàng)目引用到新建的這個(gè) AlgorithmPlugin類(lèi)庫(kù)項(xiàng)目中。你可以選擇為這個(gè)類(lèi)庫(kù)項(xiàng)目進(jìn)行程序集簽名,這樣就可以將其注冊(cè)到GAC中。另外還要為 DMPluginWrapper添加后生成腳本將程序集注冊(cè)到GAC,參考腳本如下(根據(jù)機(jī)器具體設(shè)置而定):
"C:\WINDOWS\Microsoft.NET\Framework\v2.0.50727\RegAsm.exe" $(TargetPath) |
如果***行腳本不能正確運(yùn)行的話,算法插件是不能被SQLSERVER分析服務(wù)器識(shí)別的。另外兩行腳本就是將算法程序集注冊(cè)到GAC。
接下來(lái)的幾個(gè)步驟主要是繼承一些基類(lèi)的工作,包括AlgorithmMetadataBase類(lèi)、AlgorithmBase類(lèi)和 ICaseProcessor接口和AlgorithmNavigationBase類(lèi)。首先在AlgorithmPlugin中新建一個(gè)類(lèi)文件并命名為 Metadata,為這個(gè)類(lèi)添加ComVisible、MiningAlgorithmClass(typeof(Algorithm))和Guid屬性 (Algorithm是下面要?jiǎng)?chuàng)建的算法類(lèi)),并為Guid屬性指定一個(gè)GUID編碼。這個(gè)類(lèi)要繼承于AlgorithmMetadataBase類(lèi)。現(xiàn) 在要做的事情就是覆蓋基類(lèi)的方法。下面是所有需要覆蓋的方法(對(duì)于較簡(jiǎn)單的實(shí)現(xiàn)寫(xiě)在表格中):
方法名實(shí)現(xiàn)(參考)備注
GetServiceName |
用于指定算法適用的規(guī)模,這個(gè)值不會(huì)被服務(wù)器使用而是顯示在模式行集中,為用戶(hù)提供算法的一些相關(guān)信息。
GetTrainingComplexity
return MiningTrainingComplexity.Low
用于指定算法訓(xùn)練適用的復(fù)雜度,這個(gè)值不會(huì)被服務(wù)器使用而是顯示在模式行集中,為用戶(hù)提供算法的一些相關(guān)信息。
GetPredictionComplexity
return MiningPredictionComplexity.Low
用于指定預(yù)測(cè)復(fù)雜度,這個(gè)值不會(huì)被服務(wù)器使用而是顯示在模式行集中,為用戶(hù)提供算法的一些相關(guān)信息。
GetSupportsDMDimensions
retrun false;
GetSupportsDrillThrough
return false;
指定這個(gè)算法是否支持鉆透功能。
GetDrillThroughMustIncludeChildren
return false;
GetCaseIdModeled
return false;
GetMarginalRequirements
return MarginalRequirements.AllStats
GetParametersCollection
return null;
算法參數(shù),因?yàn)楸疚闹械睦記](méi)有參數(shù),所以這里返回空。
GetSupInputContentTypes
MiningColumnContent[] arInputContentTypes = new MiningColumnContent[]{
MiningColumnContent.Discrete,
MiningColumnContent.Continuous,
MiningColumnContent.Discretized,
MiningColumnContent.NestedTable,
MiningColumnContent.Key
};
return arInputContentTypes;
指定算法所支持的輸入屬性的數(shù)據(jù)類(lèi)型,如連續(xù)型、離散型等。
GetSupPredictContentTypes
MiningColumnContent[] arPredictContentTypes = new MiningColumnContent[]{
MiningColumnContent.Discrete,
MiningColumnContent.Continuous,
MiningColumnContent.Discretized,
MiningColumnContent.NestedTable,
MiningColumnContent.Key
};
return arPredictContentTypes;
與上一個(gè)方法類(lèi)似,這里是指定預(yù)測(cè)屬性所支持的數(shù)據(jù)類(lèi)型。
GetSupportedStandardFunctions
SupportedFunction[] arFuncs= new SupportedFunction[] {
SupportedFunction.PredictSupport,
SupportedFunction.PredictHistogram,
SupportedFunction.PredictProbability,
SupportedFunction.PredictAdjustedProbability,
SupportedFunction.PredictAssociation,
SupportedFunction.PredictStdDev,
SupportedFunction.PredictVariance,
SupportedFunction.RangeMax,
SupportedFunction.RangeMid,
SupportedFunction.RangeMin,
SupportedFunction.DAdjustedProbability,
SupportedFunction.DProbability,
SupportedFunction.DStdDev,
SupportedFunction.DSupport,
SupportedFunction.DVariance,
// content-related functions
SupportedFunction.IsDescendent,
SupportedFunction.PredictNodeId,
SupportedFunction.IsInNode,
SupportedFunction.DNodeId,
};
return arFuncs;
指定DMX所支持的函數(shù)。
CreateAlgorithm
return new Algorithm();
返回算法實(shí)例,Algorithm是接下來(lái)要?jiǎng)?chuàng)建的類(lèi)。
現(xiàn)在創(chuàng)建第二個(gè)類(lèi),命名為Algorithm.cs。這個(gè)類(lèi)要繼承于AlgorithmBase并實(shí)現(xiàn)ICaseProcesses接口,這是實(shí)現(xiàn)算法最重要的一個(gè)類(lèi),主要的算法處理都在這個(gè)類(lèi)中進(jìn)行。這個(gè)類(lèi)要有一個(gè)成員變量TaskProgressNotification trainingProgress。這個(gè)類(lèi)包含了算法主要的處理邏輯。下面是要實(shí)現(xiàn)的方法:
方法名://處理樣本
InsertCases
參考實(shí)現(xiàn):
Code
//遍歷所有的樣本并且每處理100個(gè)樣本更新一次處理進(jìn)度。
trainingProgress = this.Model.CreateTaskNotification();// 設(shè)置當(dāng)前的處理進(jìn)度為0
trainingProgress.Current = 0;// 取得總的樣本數(shù)量。
trainingProgress.Total =
(int)this.MarginalStats.GetTotalCasesCount();// 為跟蹤提示信息設(shè)置格式字符串
trainingProgress.Format = "Processing cases: {0} out of {1}";// 開(kāi)始處理
trainingProgress.Start();
bool success = false;
try
{
caseSet.StartCases(this);
success = true;
}
finally
{
trainingProgress.End(success);
}
方法名:ProcessCase
參考實(shí)現(xiàn):
Code
// 檢查并確認(rèn)處理過(guò)程沒(méi)有被中斷。
this.Context.CheckCancelled();// 更新當(dāng)前的進(jìn)度值
trainingProgress.Current++;if (caseId % 100 == 0)
{
trainingProgress.Progress();
}
//TODO: 在這里進(jìn)行實(shí)際的模型訓(xùn)練處理邏輯
方法名:SaveContent參考實(shí)現(xiàn):
Code
//創(chuàng)建一個(gè)自定義的標(biāo)簽內(nèi)容用于保存處理結(jié)果(其結(jié)構(gòu)類(lèi)似XML),MyPersistenceTag是自定義的枚舉類(lèi)型writer.OpenScope((PersistItemTag)MyPersistenceTag.ShellAlgorithmContent);
writer.SetValue(System.DateTime.Now);
writer.SetAttribute((PersistItemTag)MyPersistenceTag.NumberOfCases,
this.MarginalStats.GetTotalCasesCount());
writer.CloseScope();
方法名:LoadContent
參考實(shí)現(xiàn):
Code
//打開(kāi)自定義的標(biāo)簽(與SaveContent方法相對(duì)應(yīng))
reader.OpenScope((PersistItemTag)MyPersistenceTag.ShellAlgorithmContent);//讀取處理時(shí)間
System.DateTime processingTime;
reader.GetValue(out processingTime);// 取得處理的樣本數(shù)量
uint numberCases = 0;reader.GetAttribute((PersistItemTag)MyPersistenceTag.NumberOfCases, out numberCases);
reader.CloseScope();
方法名:Predict
參考實(shí)現(xiàn):
Code
AttributeGroup targetAttributes = predictionResult.OutputAttributes;
targetAttributes.Reset();
uint nAtt = AttributeSet.Unspecified;//對(duì)于每一個(gè)目標(biāo)屬性,從訓(xùn)練集中復(fù)制預(yù)測(cè)結(jié)果
while (targetAttributes.Next(out nAtt))
{
//創(chuàng)建一個(gè)AttributeStatistics對(duì)象用于保存對(duì)當(dāng)前目標(biāo)屬性的預(yù)測(cè)結(jié)果
AttributeStatistics result = new AttributeStatistics();//設(shè)置預(yù)測(cè)結(jié)果中的目標(biāo)屬性,即當(dāng)前的預(yù)測(cè)結(jié)果針對(duì)于哪個(gè)輸入屬性
result.Attribute = nAtt;// 取得當(dāng)前屬性的概率統(tǒng)計(jì)值,也即通過(guò)模型訓(xùn)練得到的邊緣統(tǒng)計(jì)概率。
AttributeStatistics trainingStats = this.MarginalStats.GetAttributeStats(nAtt);//復(fù)制其余的數(shù)據(jù)到結(jié)果對(duì)象
result.AdjustedProbability = trainingStats.AdjustedProbability;
result.Max = trainingStats.Max;
result.Min = trainingStats.Min;
result.Probability = trainingStats.Probability;
result.Support = trainingStats.Support;//復(fù)制狀態(tài)統(tǒng)計(jì)到結(jié)果對(duì)象中
if (predictionResult.IncludeStatistics)
{
for ( int nIndex = 0; nIndex < trainingStats.StateStatistics.Count; nIndex++)
{
bool bAddThisState = true;// 如果是丟失值狀態(tài),那么只有當(dāng)需要的時(shí)候才將其包含在結(jié)果之中。
if (trainingStats.StateStatistics[0].Value.IsMissing)
{
bAddThisState = predictionResult.IncludeMissingState;
}if (bAddThisState)
{
result.StateStatistics.Add(
trainingStats.StateStatistics[(uint)nIndex]);
}
}
}//如果預(yù)測(cè)需要內(nèi)容結(jié)點(diǎn),就要為內(nèi)容結(jié)點(diǎn)設(shè)置一個(gè)唯一的編號(hào)
if (predictionResult.IncludeNodeId)
{
result.NodeId = "000";
}
predictionResult.AddPrediction(result);
方法名:GetNavigator參考實(shí)現(xiàn):
Code
//AlgorithmNavigator是下面要?jiǎng)?chuàng)建的類(lèi)
return new AlgorithmNavigator(this, forDMDimensionContent);
接下來(lái)要實(shí)現(xiàn)的是AlgorithmNavigator類(lèi),這個(gè)類(lèi)要繼承于 AlgorithmNavigationBase。這個(gè)類(lèi)主要用于顯示算法處理結(jié)果中所有結(jié)點(diǎn)的信息。在這個(gè)類(lèi)中有三個(gè)成員變量:Algorithm類(lèi)型 的algorithm、bool類(lèi)型的forDMDimension和int類(lèi)型的currentNode。下面是這個(gè)類(lèi)要實(shí)現(xiàn)的方法:
方法名(構(gòu)造方法):AlgorithmNavigator參考實(shí)現(xiàn):
Code
this.algorithm = currentAlgorithm;
this.forDMDimension = dmDimension;
this.currentNode = 0;
方法名
實(shí)現(xiàn)
備注
MoveToNextTree
return false;
GetCurrentNodeId
return currentNode;
ValidateNodeId
return (nodeId == 0);
LocateNode
if (!ValidateNodeId(nodeId))return false;
currentNode = nodeId;
return true;
GetNodeIdFromUniqueName
int nNode = Convert.ToInt32(nodeUniqueName);return nNode;
GetUniqueNameFromNodeId
return nodeId.ToString("D3");
按三位數(shù)字的格式輸出結(jié)點(diǎn)編號(hào)
GetParentCount
return 0;
GetParentNodeId
return 0;
GetChildrenCount
return 0
GetChildNodeId
return -1;
GetNodeType
return NodeType.Model;
GetNodeUniqueName
return GetUniqueNameFromNodeId(currentNode);
GetNodeAttributes
return null;
方法名:
//此方法返回了描述結(jié)點(diǎn)的數(shù)值特征
GetDoubleNodeProperty
參考實(shí)現(xiàn):
Code
double dRet = 0;
double dTotalSupport = lgorithm.MarginalStats.GetTotalCasesCount();
double dNodeSupport = 0.0;
dNodeSupport = dTotalSupport;
switch (property)
{
//結(jié)點(diǎn)的支持度
case NodeProperty.Support:
dRet = dNodeSupport;
break;
case NodeProperty.Score:
dRet = 0;
break;
//結(jié)點(diǎn)概率
case NodeProperty.Probability:
dRet = dNodeSupport / dTotalSupport;
break;
//結(jié)點(diǎn)的邊緣概率
case NodeProperty.MarginalProbability:
dRet = dNodeSupport / dTotalSupport;
break;
}
return dRet;
方法名://取得結(jié)點(diǎn)的字符串表示
GetStringNodeProperty
參考實(shí)現(xiàn):
Code
string strRet = "";
switch (property)
{
case NodeProperty.Caption:
{
strRet = algorithm.Model.FindNodeCaption(GetNodeUniqueName());
if (strRet.Length == 0)
{
strRet = "All";
}
}
break;
case NodeProperty.ConditionXml:
strRet = "";
break;
case NodeProperty.Description:
strRet = "All Cases";
break;
case NodeProperty.ModelColumnName:
strRet = "";
break;
case NodeProperty.RuleXml:
strRet = "";
break;
case NodeProperty.ShortCaption:
strRet = "All";
break;
}
return strRet;
方法名:
//取得結(jié)點(diǎn)的分布
GetNodeDistribution
參考實(shí)現(xiàn):
Code
int attStats = (int)algorithm.AttributeSet.GetAttributeCount();
AttributeStatistics[] marginalStats = new AttributeStatistics[attStats];
for (uint nIndex = 0; nIndex < attStats; nIndex++)
{
marginalStats[nIndex] = algorithm.MarginalStats.GetAttributeStats(nIndex);
}
return marginalStats;
現(xiàn)在我們已經(jīng)實(shí)現(xiàn)了完所有需要要實(shí)現(xiàn)的類(lèi),***要做的就是將算法插件部署到分析服務(wù)器。在完成代碼后,需要將程序集注冊(cè)到GAC以便分析服務(wù)器 可以從中加載插件。下面的代碼就是將DMPluginWrapper加載到GAC的腳本,如果在本文的開(kāi)頭正確地在Visual Studio中設(shè)置了后生成(Post-Building)腳本的話可以跳過(guò)下面的腳本代碼,因?yàn)樗鼈兪窍嗤墓δ埽?nbsp;
//將DMPluginWrapper.dll注冊(cè)到GAC中 |
注意以上的路徑一定要與自己機(jī)器的設(shè)置匹配。成功運(yùn)行上面的腳本后算法插件就被注冊(cè)到計(jì)算機(jī)之中,但要在分析服務(wù)器中使用這個(gè)算法還有一項(xiàng)工 作,就是把在分析服務(wù)器中注冊(cè)這個(gè)算法。在分析服務(wù)器中注冊(cè)算法有兩種方式,一種是通過(guò)發(fā)送XMLA代碼到分析服務(wù)器來(lái)注冊(cè);另一種是通過(guò)修改 SQLSERVER的配置文件來(lái)注冊(cè)算法插件。下面先說(shuō)***種:
通過(guò)XMLA方式注冊(cè)算法插件——
| <!--Template for registering a plug-in algorithm Replace MyPluginAlgorithm with the ServiceName of your algorithm Replace 00000000-0000-0000-0000-000000000000 with the Guid of your Algorithm After deploying, you will need to restart the server to load the plug-in --><ALTER AllowCreate="true" ObjectExpansion="ObjectProperties" xmlns="<A > > <BR><Server xmlns:xsd="<A <A > <Name>.</Name> <ServerProperties> <ServerProperty> <!-- 用自己的算法名稱(chēng)替換 --> <Name>MyFirstAlgorithmPlugin</Name> <!-- 是否啟用算法 --> <Value>true</Value> </ServerProperty> <ServerProperty> <!-- 用自己的算法名稱(chēng)替換 --> <BR><Name>MyFirstAlgorithmPlugin</Name> <!--算法的GUID(在算法類(lèi)中指定的GUID) --><Value>00000000-0000-0000-0000-000000000000</Value> </ServerProperty> </ServerProperties></Server> </ObjectDefinition> </Alter> |
通過(guò)修改SQLSERVER的配置文件注冊(cè)算法——
找到SQLSERVER安裝目錄下的MSSQL.2\OLAP\Config\msmdsrv.ini文件。這個(gè)是一個(gè)XML格式的文檔。文檔內(nèi)容類(lèi)似于下面的代碼:
<ConfigurationSettings> |
在以上的配置信息中算法名稱(chēng)是來(lái)自于Metadata類(lèi)的GetServiceName這個(gè)方法,即在配置中設(shè)置的算法名稱(chēng)要與這個(gè)方法的返回值相同。到這里一個(gè)基本的算法插件程序就完成了,重啟分析服務(wù)器后就可以在建立挖掘模型的窗口中看到新的算法出現(xiàn)在算法下拉列表中了。
從建立算法插件的整個(gè)過(guò)程來(lái)看,除開(kāi)前后的準(zhǔn)備工作和部署主要就是對(duì)三個(gè)類(lèi)的重寫(xiě),而其中最主要的類(lèi)就是算法類(lèi)的重寫(xiě),其它兩個(gè)類(lèi)的主要作用是為算法提供元數(shù)據(jù)信息及結(jié)果的描述。在算法類(lèi)中要實(shí)現(xiàn)挖掘模型的樣本訓(xùn)練以及預(yù)測(cè),這是算法最關(guān)鍵的地方,重寫(xiě)算法類(lèi)中的ProcessCase方法和Predict方法是算法插件的核心。在了解如何擴(kuò)展算法后要做的工作就是設(shè)計(jì)新的算法或?qū)⒁呀?jīng)完成的算法集成到插件中。
【編輯推薦】










